



Francesco Conti : 12 noviembre 2025 22:03
La inteligencia artificial no es magia, ¡es aprendizaje! Este artículo busca desmitificar el esoterismo que rodea a la inteligencia artificial (IA) ofreciendo una respuesta completa a la pregunta : «¿Cómo aprenden las máquinas?». De hecho, la clave del funcionamiento de la IA reside en la fase de aprendizaje. Las aplicaciones de inteligencia artificial utilizan grandes cantidades de datos, a partir de los cuales se identifican patrones para tomar decisiones basadas en datos .
Existen varios enfoques para el aprendizaje, entre ellos el aprendizaje supervisado , el no supervisado y el de refuerzo . Estos métodos difieren en sus objetivos y problemas a resolver, así como en el tipo de datos disponibles: ejemplos etiquetados, ejemplos no etiquetados o mediante interacción directa con un entorno, respectivamente.
En este artículo, exploraremos estos tres métodos e intentaremos comprender cómo funcionan. También ofreceremos una visión general de los mecanismos de aprendizaje modernos, como el aprendizaje activo y el aprendizaje por refuerzo a partir de la retroalimentación humana .
El aprendizaje supervisado es uno de los enfoques más populares en el aprendizaje automático. Los métodos basados en este enfoque se fundamentan en una fase de entrenamiento con datos, en la que cada ejemplo se asocia a una respuesta o etiqueta correspondiente. El objetivo principal de un modelo de aprendizaje automático (ML) en este contexto es aprender la relación entre las características de los datos y las etiquetas para realizar predicciones precisas sobre nuevas entradas. Las principales tareas que se pueden resolver mediante el aprendizaje supervisado son:
Para comprender mejor, consideremos un ejemplo de clasificación en el que queremos entrenar un modelo para predecir si un cliente de una tienda online pertenece al segmento de «gama alta» o «gama baja» con el fin de dirigir la publicidad de productos de lujo. Para ello, recopilamos datos sobre los ingresos y el gasto mensual promedio de los clientes. A cada ejemplo de entrenamiento se le asigna una etiqueta que evalúa si el cliente ha respondido a anuncios de gama alta en el pasado, asociándole un valor de 1 (cuadrado amarillo) o 0 (triángulo verde). En este ejemplo:
Una vez aprendida la regla, el modelo se utiliza en una fase llamada inferencia , para clasificar a los nuevos clientes y determinar si conviene anunciar productos de lujo. En esta fase, el modelo
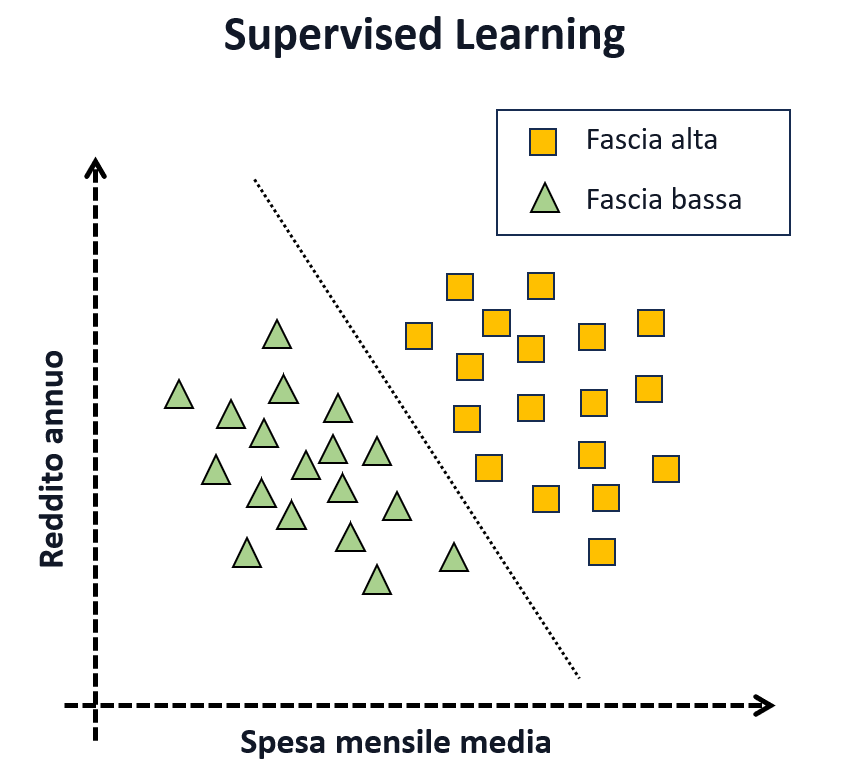
Más allá de este ejemplo trivial, el aprendizaje supervisado se utiliza actualmente con éxito para problemas de:
En el aprendizaje no supervisado, no contamos con etiquetas ni respuestas correctas asociadas a los datos de entrenamiento. El objetivo principal de este enfoque es descubrir patrones o estructuras ocultas en los datos sin ninguna guía externa. Las principales tareas asociadas al aprendizaje no supervisado son:
Volviendo al ejemplo de la tienda, en este caso podríamos haber recopilado información sobre el historial de ingresos y gastos, pero sin registrar información sobre sus respuestas a anuncios anteriores de productos de lujo. En este caso, solo contamos con las características y no con las etiquetas, pero aún así podríamos estar interesados en perfilar a los clientes para evaluar si existen grupos que podrían ser más receptivos. En la figura, podemos observar que los usuarios se agrupan en dos clústeres. Por lo tanto, el aprendizaje no supervisado aún puede utilizarse para extraer información valiosa de los datos y establecer una regla para la toma de decisiones, como la publicidad dirigida, que en este caso se enfocará en el clúster con los mayores ingresos y gastos promedio.
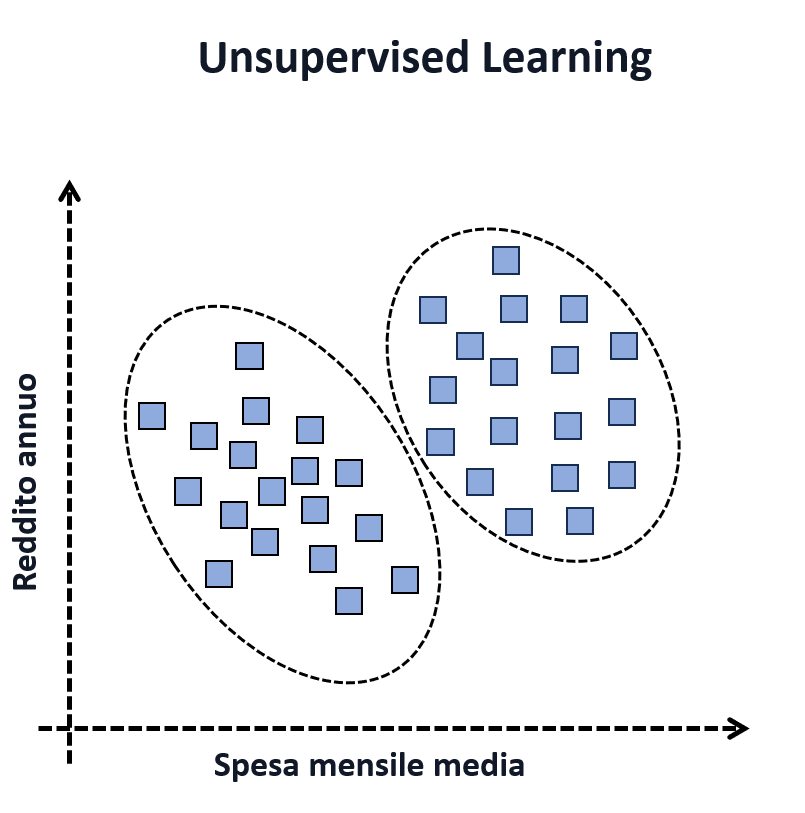
Entre las aplicaciones más significativas del aprendizaje no supervisado:
El aprendizaje por refuerzo (RL) es una rama de la inteligencia artificial en la que los agentes aprenden a tomar decisiones mediante la interacción directa con el entorno. A diferencia de enfoques anteriores, el RL se basa en un proceso de aprendizaje por ensayo y error . Los agentes exploran el entorno y reciben recompensas positivas o negativas según sus acciones. El objetivo del agente es aprender una estrategia óptima para maximizar la cantidad acumulada de refuerzos obtenidos a largo plazo. Mediante iteraciones continuas, el agente actualiza su política de acción para tomar decisiones más inteligentes en el contexto específico.
El aprendizaje por refuerzo (RL) se aplica en una amplia gama de tareas, como el control de robots autónomos, la gestión de recursos, los juegos de estrategia y la planificación de acciones. Por ejemplo, en el control de robots, el agente aprende a realizar acciones que maximizan el logro de un objetivo específico, como caminar o manipular objetos. En los juegos de estrategia, el RL se puede usar para entrenar agentes capaces de tomar decisiones tácticas y estratégicas para ganar juegos complejos como el ajedrez o los videojuegos.
Los enfoques descritos constituyen los ingredientes fundamentales del aprendizaje automático y son necesarios para comprender cómo funcionan los bloques funcionales de los sistemas de IA. Sin embargo, algunas técnicas de aprendizaje se benefician del entrenamiento híbrido o en varias etapas.
Un ejemplo es el preentrenamiento no supervisado para tareas de visión artificial. En particular, cuando los datos etiquetados disponibles son limitados, el preentrenamiento con una tarea no supervisada permite que un modelo aprenda representaciones de imágenes significativas a partir de datos sin etiquetar.
Estas características aprendidas pueden transferirse a tareas específicas, mejorando el rendimiento y reduciendo la necesidad de datos etiquetados. Este tipo de aprendizaje se denomina aprendizaje por transferencia : un modelo se preentrena en una tarea o dominio y luego se utiliza como punto de partida para abordar una nueva tarea.
Este tipo de enfoques se utilizan para abordar la falta (o el coste excesivo) de datos correctamente etiquetados. A continuación, analizaremos otros métodos que logran el mismo objetivo.
Otros enfoques de aprendizaje que son muy populares en aplicaciones recientes:
En este artículo, exploramos cómo aprenden las máquinas; las técnicas ilustradas representan un marco importante para formalizar problemas de IA. Incluso sistemas complejos como el reconocimiento de imágenes y los modelos de lenguaje se basan en estos componentes funcionales. En futuros artículos, exploraremos cómo el aprendizaje automático y el aprendizaje profundo extraen información valiosa de los datos para resolver diversas tareas.
A menudo hablamos del servicio de ransomware como servicio (RaaS) LockBit, recientemente renovado como LockBit 3.0, que sigue aportando innovaciones significativas al panorama del ransomware. Estas in...
En esta apasionante historia, viajaremos a 1959 al Club de Ferrocarriles en Miniatura del MIT Tech y conoceremos a Steve Russell. Steve fue uno de los primeros hackers y escribió uno de los primeros ...
El significado de » hacker » tiene profundas raíces. Proviene del inglés «to hack», que significa picar, cortar, golpear o mutilar. Es una imagen poderosa: la de un campesino rompiendo terrones ...
Desde las vulnerabilidades de WEP hasta los avances de WPA3 , la seguridad de las redes Wi-Fi ha evolucionado enormemente. Hoy en día, las redes autoprotegidas representan la nueva frontera: sistemas...
Un hallazgo excepcional de los primeros tiempos de Unix podría llevar a los investigadores a los mismísimos orígenes del sistema operativo. En la Universidad de Utah se descubrió una cinta magnét...





