



Redazione RHC : 23 octubre 2025 20:59
El 21 de octubre de 2025, un equipo internacional de investigadores de 29 instituciones líderes, incluidas la Universidad de Stanford, el MIT y la Universidad de California en Berkeley, completó un estudio que marca un hito en el desarrollo de la inteligencia artificial: la definición del primer marco cuantitativo para evaluar la Inteligencia Artificial General (AGI).
Basado en la teoría psicológica Cattell-Horn-Carroll (CHC) , el modelo propuesto divide la inteligencia general en diez dominios cognitivos distintos , cada uno con un peso del 10%, para un total de 100 puntos que representan el nivel cognitivo humano.
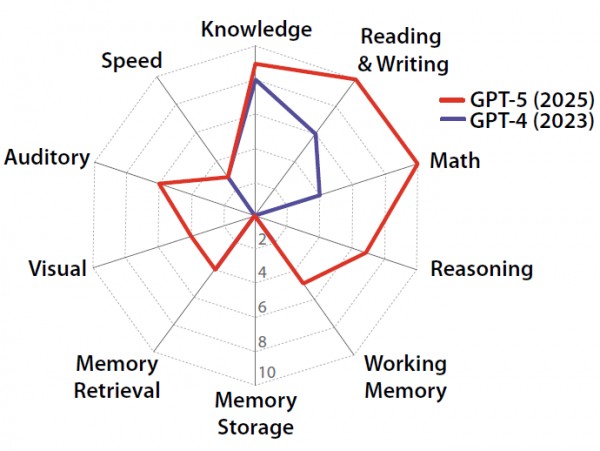
Según esta escala, el GPT-4 obtuvo un puntaje de 27%, mientras que el GPT-5 alcanzó 58% , lo que evidencia una distribución desigual de habilidades, con excelentes resultados en lenguaje y conocimiento, pero cero puntajes en memoria de largo plazo.
Según los investigadores, determinar si una IA puede considerarse » inteligente » como un humano requiere una evaluación amplia y multidimensional. Al igual que un chequeo médico completo que mide la salud de múltiples órganos, la IAG se analiza en múltiples dominios cognitivos: desde el razonamiento hasta el lenguaje, desde la memoria hasta la percepción sensorial.
El nuevo marco se basa en la teoría CHC , utilizada durante décadas en psicología para medir las capacidades cognitivas humanas. Este enfoque permite descomponer la inteligencia en componentes analíticos, como la cognición, el razonamiento, el procesamiento visual y la memoria.
El objetivo del equipo era transformar estos principios en un sistema de medición objetivo que también pudiera aplicarse a modelos de inteligencia artificial.

Las pruebas evaluaron GPT-4 y GPT-5 en diez áreas : conocimiento general, comprensión y producción de textos, matemáticas, razonamiento inmediato, memoria de trabajo, memoria a largo plazo, recuperación de la memoria, procesamiento visual, procesamiento auditivo y velocidad de reacción.
El GPT-5 mostró mejoras significativas con respecto a su predecesor, alcanzando puntuaciones casi perfectas en lenguaje, conocimiento y matemáticas. Sin embargo, ambas versiones fallaron en las pruebas de memoria a largo plazo y gestión consistente de la información a lo largo del tiempo.
Según los investigadores, esto demuestra que los sistemas de IA actuales compensan sus deficiencias mediante estrategias de «distorsión de capacidad», explotando enormes cantidades de datos o herramientas externas para enmascarar limitaciones estructurales.
El informe describe la distribución de resultados como «dientes de sierra»: excelencia en algunas áreas y graves deficiencias en otras. Por ejemplo, el GPT-5 se comporta como un estudiante brillante en asignaturas teóricas, pero es incapaz de recordar las lecciones aprendidas. Esta fragmentación cognitiva pone de manifiesto que, a pesar de mostrar capacidades avanzadas, las IA aún carecen de una comprensión continua y autónoma del mundo.
Los autores del estudio comparan la IA con un motor sofisticado que carece de algunos componentes esenciales. Incluso con un sistema lingüístico y matemático de vanguardia, la falta de una memoria estable y un verdadero mecanismo de aprendizaje limita la capacidad general. Para la inteligencia artificial, esto se traduce en un alto rendimiento en tareas específicas, pero con poca adaptabilidad y aprendizaje autónomo a largo plazo.
Además de proporcionar una base científica para la evaluación de la inteligencia artificial, el estudio ayuda a redefinir las expectativas para el desarrollo de la IAG. Demuestra que simplemente aumentar el tamaño de los modelos o los datos no basta para lograr una cognición similar a la humana: se necesitan nuevas arquitecturas capaces de integrar la memoria, el razonamiento y el aprendizaje experiencial.
Los investigadores también enfatizan la importancia de abordar las llamadas «alucinaciones» de la IA (errores de fabricación de información), que siguen siendo un problema crítico en todos los modelos probados. Conocer estas limitaciones puede guiar un uso más informado de la tecnología, evitando tanto el entusiasmo excesivo como los temores infundados.
En definitiva, la principal contribución de esta investigación es la introducción de un verdadero «criterio cognitivo» para medir la inteligencia artificial de forma objetiva y comparable. Solo comprendiendo sus fortalezas y debilidades actuales será posible guiar eficazmente la próxima generación de sistemas inteligentes.
 Redazione
RedazioneLos atacantes están explotando activamente una vulnerabilidad crítica en el sistema de protección de aplicaciones web (WAF) FortiWeb de Fortinet, que podría utilizarse como medio para realizar ata...
En uno de los foros más populares de Rusia para la compraventa de vulnerabilidades y herramientas de ataque, el hilo apareció como un anuncio comercial estándar, pero su contenido dista mucho de se...
A menudo hablamos del servicio de ransomware como servicio (RaaS) LockBit, recientemente renovado como LockBit 3.0, que sigue aportando innovaciones significativas al panorama del ransomware. Estas in...
En esta apasionante historia, viajaremos a 1959 al Club de Ferrocarriles en Miniatura del MIT Tech y conoceremos a Steve Russell. Steve fue uno de los primeros hackers y escribió uno de los primeros ...
El significado de » hacker » tiene profundas raíces. Proviene del inglés «to hack», que significa picar, cortar, golpear o mutilar. Es una imagen poderosa: la de un campesino rompiendo terrones ...




