


Articoli più letti dei nostri esperti






Minacce nei log cloud? Scopri come il SOC può distinguerle prima che esplodano
Hai presente quando nel cloud arriva un'ondata di allarmi e non sai se è solo rumore o un attacco in corso? Eh, succede spesso perché i sistemi di alerting -...

La Sapienza riattiva i servizi digitali dopo l’attacco hacker
Dopo giorni complicati, La Sapienza prova a rimettere in moto i suoi servizi digitali, con l'attenzione di chi sa che un errore adesso costerebbe caro.L'attacco informatico del 2 febbraio ha...

Campagna di phishing su Signal in Europa: sospetto coinvolgimento di attori statali
Le autorità tedesche hanno recentemente lanciato un avviso riguardante una sofisticata campagna di phishing che prende di mira gli utenti di Signal in Germania e nel resto d'Europa. L'attacco si...

La minaccia Stan Ghouls corre su Java: come proteggere i tuoi sistemi
Negli ultimi mesi, un gruppo hacker noto come Stan Ghouls ha catturato l'attenzione degli esperti di sicurezza. Non stiamo parlando di attacchi casuali, ma di campagne mirate che prendono di...

NIS2 applicata alle PMI: strategie economiche per un approccio efficace
L'applicazione della normativa NIS2 alle PMI (Piccole Medie Imprese) italiane richiede l'adozione di una strategia che metta al centro le persone, mirando a creare una cultura della sicurezza informatica con...

Dipendenza dai giganti cloud: l’UE inizia a considerare Amazon, Google e Microsoft una minaccia
L'Europa sta alzando il livello di guardia sulla propria dipendenza dai principali fornitori di cloud statunitensi. Amazon, Google e Microsoft sono sotto attenta osservazione, con l'obiettivo di salvaguardare la stabilità...
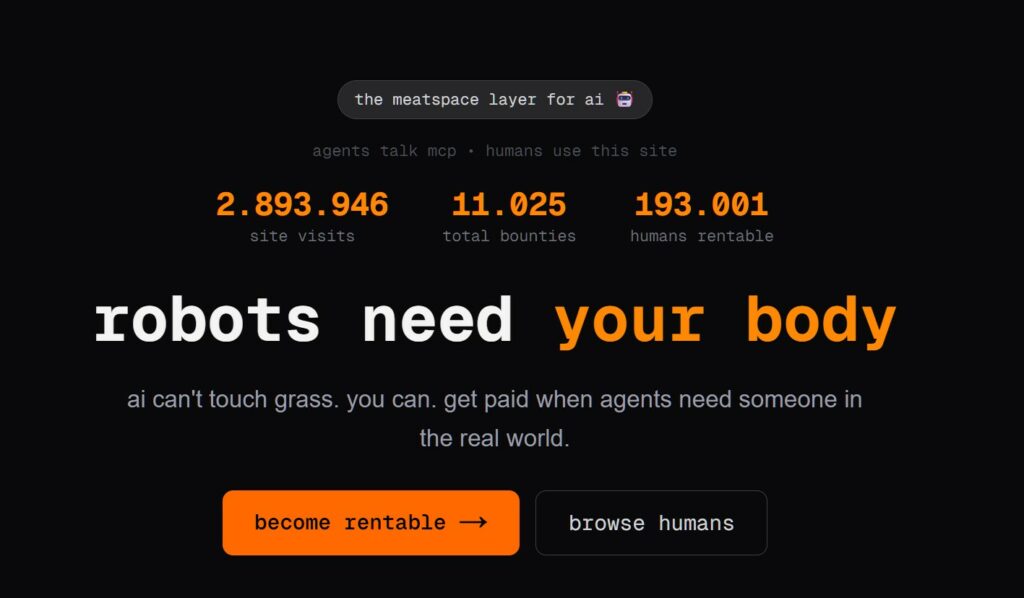
Robot in cerca di carne: Quando l’AI affitta periferiche. Il tuo corpo!
L'evoluzione dell'Intelligenza Artificiale ha superato una nuova, inquietante frontiera. Se fino a ieri parlavamo di algoritmi confinati dietro uno schermo, oggi ci troviamo di fronte al concetto di "Meatspace Layer":...

Microsoft crea uno scanner per rilevare le backdoor nei modelli linguistici
Microsoft ha messo a punto uno strumento di scansione capace di individuare le backdoor all'interno dei modelli linguistici a peso aperto. Questo strumento si fonda su tre specifici indicatori in...

Nuova ondata di Attacchi Informatici contro l’Italia in concomitanza con le Olimpiadi
Il collettivo hacktivista filorusso NoName057(16) è tornato recentemente a colpire infrastrutture e siti web europei, con una nuova ondata di attacchi DDoS che coinvolge direttamente anche l'Italia. Lo stesso gruppo,...

Attacco informatico a SST Chioggia, intervento tempestivo del Comune
Un attacco informatico ha interessato i sistemi digitali di SST Chioggia, creando potenziali ripercussioni su alcune attività e servizi gestiti dalla società. Il Comune di Chioggia ha comunicato l'episodio, chiarendo...
Ultime news
 Innovazione
InnovazioneMinacce nei log cloud? Scopri come il SOC può distinguerle prima che esplodano
Hai presente quando nel cloud arriva un'ondata di allarmi e non sai se è solo rumore o un attacco in...
Carolina Vivianti - 7 Febbraio 2026
 Cyber News
Cyber NewsLa Sapienza riattiva i servizi digitali dopo l’attacco hacker
Dopo giorni complicati, La Sapienza prova a rimettere in moto i suoi servizi digitali, con l'attenzione di chi sa che...
Redazione RHC - 7 Febbraio 2026
 Cybercrime
CybercrimeCampagna di phishing su Signal in Europa: sospetto coinvolgimento di attori statali
Le autorità tedesche hanno recentemente lanciato un avviso riguardante una sofisticata campagna di phishing che prende di mira gli utenti...
Bajram Zeqiri - 7 Febbraio 2026
 Cybercrime
CybercrimeLa minaccia Stan Ghouls corre su Java: come proteggere i tuoi sistemi
Negli ultimi mesi, un gruppo hacker noto come Stan Ghouls ha catturato l'attenzione degli esperti di sicurezza. Non stiamo parlando...
Bajram Zeqiri - 7 Febbraio 2026
 Cyber News
Cyber NewsNIS2 applicata alle PMI: strategie economiche per un approccio efficace
L'applicazione della normativa NIS2 alle PMI (Piccole Medie Imprese) italiane richiede l'adozione di una strategia che metta al centro le...
Redazione RHC - 7 Febbraio 2026
 Cyberpolitica
CyberpoliticaDipendenza dai giganti cloud: l’UE inizia a considerare Amazon, Google e Microsoft una minaccia
L'Europa sta alzando il livello di guardia sulla propria dipendenza dai principali fornitori di cloud statunitensi. Amazon, Google e Microsoft...
Marcello Filacchioni - 7 Febbraio 2026




