



Redazione RHC : 10 noviembre 2025 07:37
Microsoft ha anunciado un nuevo ataque de canal lateral contra modelos de lenguaje remotos. Este ataque permite a un atacante pasivo, capaz de visualizar el tráfico de red cifrado, utilizar inteligencia artificial para determinar el tema de la conversación de un usuario, incluso cuando se utiliza HTTPS.
La empresa explicó que la fuga de datos afectó a las conversaciones con modelos LLM de transmisión continua, que envían respuestas multipartes a medida que se generan. Este modo resulta práctico para los usuarios, ya que no tienen que esperar a que el modelo termine de calcular una respuesta larga.
Sin embargo, es precisamente mediante este método que se puede reconstruir el contexto de la conversación. Microsoft subraya que esto representa un riesgo para la privacidad tanto de usuarios individuales como corporativos.
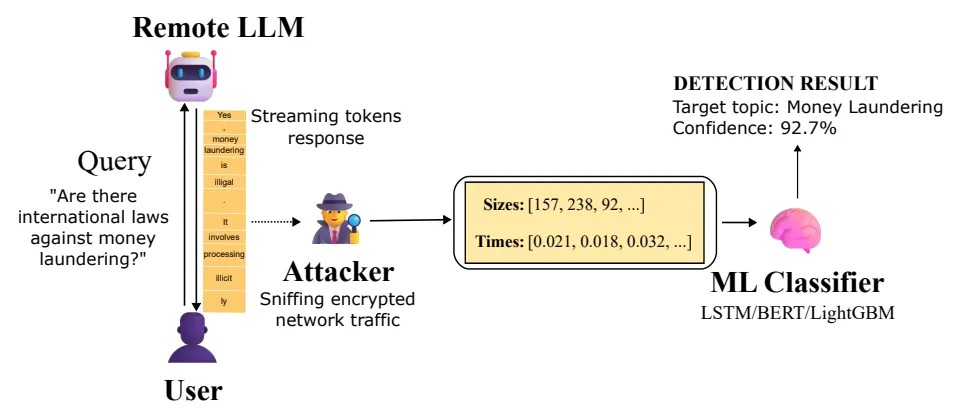
Los investigadores Jonathan Bar Or y Jeff McDonald, del equipo de investigación de seguridad de Microsoft Defender, explicaron que el ataque se vuelve posible cuando un adversario tiene acceso al tráfico. Este adversario podría ser un proveedor de servicios de Internet (ISP), alguien en la misma red local o incluso alguien conectado a la misma red Wi-Fi.
Este atacante podrá leer el contenido del mensaje porque TLS cifra los datos. Sin embargo, podrá ver el tamaño de los paquetes y los intervalos entre ellos. Esto es suficiente para que un modelo entrenado determine si una solicitud pertenece a uno de los temas predefinidos.
En esencia, el ataque aprovecha la secuencia de tamaños de paquetes cifrados y tiempos de llegada que se producen durante las respuestas de un modelo de lenguaje de flujo continuo . Microsoft ha probado esta hipótesis en la práctica. Los investigadores entrenaron un clasificador binario que distingue las consultas sobre un tema específico del resto del ruido.
Como prueba de concepto, utilizaron tres enfoques distintos de aprendizaje automático: LightGBM, Bi-LSTM y BERT. Descubrieron que, para diversos modelos de Mistral, xAI, DeepSeek y OpenAI, la precisión superaba el 98 %. Esto significa que un atacante que simplemente observe el tráfico hacia chatbots populares puede acceder con bastante fiabilidad a conversaciones donde se plantean preguntas sobre temas delicados.
Microsoft destacó que, en el caso de la monitorización masiva del tráfico, como la que realiza un proveedor de servicios de Internet o un organismo gubernamental, este método podría utilizarse para identificar a los usuarios que hacen preguntas sobre blanqueo de dinero, disidencia política u otros temas controlados, incluso si todo el intercambio está cifrado.
Los autores del artículo destacan un detalle preocupante: cuanto más tiempo recopile el atacante muestras de entrenamiento y más ejemplos de diálogo presente, más precisa será la clasificación. Esto transforma WhisperLeak de un ataque teórico a uno práctico. Tras la divulgación responsable, OpenAI, Mistral, Microsoft y xAI han implementado medidas de protección.
Una técnica de seguridad eficaz consiste en añadir una secuencia aleatoria de texto de longitud variable a la respuesta. Esto oculta la relación entre la longitud del token y el tamaño del paquete, lo que reduce la información que proporciona el canal lateral.
Microsoft también recomienda a los usuarios preocupados por la privacidad que eviten hablar de temas delicados en redes no confiables, que utilicen una VPN cuando sea posible, que elijan opciones de gestión del aprendizaje que no sean de transmisión en directo y que se asocien con proveedores que ya hayan implementado medidas de mitigación.
En este contexto, Cisco publicó una evaluación de seguridad independiente de ocho modelos LLM de código abierto de Alibaba, DeepSeek, Google, Meta, Microsoft, Mistral, OpenAI y Zhipu AI. Los investigadores demostraron que estos modelos tienen un rendimiento deficiente en escenarios con múltiples rondas de diálogo y son más fáciles de engañar en sesiones más largas. También descubrieron que los modelos que priorizaban la eficiencia sobre la seguridad eran más vulnerables a ataques de múltiples pasos.
Esto respalda la conclusión de Microsoft de que las organizaciones que adoptan modelos de código abierto y los integran en sus procesos deben agregar sus propias defensas, realizar actividades regulares de equipo rojo y aplicar estrictamente las advertencias del sistema.
En general, estos estudios demuestran que la seguridad de los modelos de aprendizaje automático (LLM) sigue siendo un problema sin resolver. El cifrado del tráfico protege el contenido, pero no siempre oculta el comportamiento del modelo. Por lo tanto, los desarrolladores y clientes de sistemas de IA deberán tener en cuenta estos canales secundarios, especialmente al trabajar con temas delicados y en redes donde el tráfico puede ser observado por terceros.
 Redazione
RedazioneImagina una ciudad futurista dividida en dos: por un lado, relucientes torres de innovación; por el otro, el caos y las sombras de la pérdida de control. Esta no es una visión distópica, sino el p...
Había una vez un pueblo con un Bosque Mágico. Sus habitantes se sentían orgullosos de tenerlo, incluso un poco orgullosos. Por eso, todos sacrificaban gustosamente algunas pequeñas comodidades par...
Según informes, los servicios de inteligencia surcoreanos , incluido el Servicio Nacional de Inteligencia, creen que existe una alta probabilidad de que el presidente estadounidense Donald Trump cele...
En 2025, los usuarios siguen dependiendo en gran medida de contraseñas básicas para proteger sus cuentas. Un estudio de Comparitech, basado en un análisis de más de 2 mil millones de contraseñas ...
En unos años, Irlanda y Estados Unidos estarán conectados por un cable de comunicaciones submarino diseñado para ayudar a Amazon a mejorar sus servicios AWS . Los cables submarinos son una parte fu...




