



Marcello Politi : 12 noviembre 2025 22:09
En el mundo de la inteligencia artificial, se suelen escuchar dos términos: aprendizaje automático (ML) y aprendizaje profundo (DL). Ambos son métodos para implementar la IA mediante el entrenamiento de algoritmos de aprendizaje automático, que luego se utilizan para realizar predicciones sobre el futuro y tomar decisiones.
Estas dos disciplinas emplean enfoques distintos y poseen capacidades y características diferentes. En este artículo, exploraremos las diferencias entre ambas y comprenderemos mejor su funcionamiento.
El aprendizaje automático es la disciplina que diseña algoritmos capaces de realizar predicciones aprendiendo patrones de datos históricos. Un algoritmo de aprendizaje automático se diferencia de un algoritmo informático «clásico» en la forma en que se estructura el problema.
En un algoritmo clásico, se le dan a la máquina reglas que debe seguir paso a paso para transformar la entrada en una salida. Por ejemplo, una entrada podría ser una lista de números [1, 2, 3, 4, 5], la regla podría ser: «transformar cada número en su cuadrado», de modo que f(x) = x^2.
Una vez dadas estas reglas y esta entrada, el algoritmo podría darnos la siguiente salida: [1, 4, 9, 16, 25].
En un algoritmo de aprendizaje automático, sin embargo, el problema se invierte.
Lo que proporcionamos a la máquina es la entrada y la salida esperada, es decir [1, 2, 3, 4, 5] y [1, 4, 9, 16, 25], y el algoritmo nos dará como salida la regla que relaciona estos valores, es decir f(x) = x^2.
De esta forma, todo lo que tenemos que hacer es recopilar observaciones (datos) y alimentarlas al algoritmo , que encontrará la relación que rige nuestras observaciones y que luego podrá utilizarse para realizar predicciones futuras.
El tipo de algoritmo de aprendizaje automático que acabamos de describir pertenece en realidad a la categoría de algoritmos definidos como aprendizaje supervisado .
Básicamente existen 3 categorías diferentes, que son las siguientes:
Existen numerosos algoritmos de aprendizaje automático, y es tarea del científico de datos determinar cuál utilizar y cuándo. Un algoritmo en particular, denominado Redes Neuronales Artificiales, ha abierto un sinfín de nuevas posibilidades, y los científicos de IA han comenzado a centrarse en su estudio, dando lugar así a un nuevo campo de estudio llamado Aprendizaje Profundo.
El aprendizaje profundo es un subconjunto del aprendizaje automático ; de hecho, se centra exclusivamente en el uso de redes neuronales artificiales capaces de aprender patrones ocultos en los datos.
La red neuronal artificial (RNA) está inspirada en la biológica.
El elemento básico de una red neuronal biológica es la neurona individual, mientras que en una artificial encontramos el perceptrón . La neurona percibe descargas eléctricas de entrada a través de sus dendritas, las cuales son procesadas por el núcleo. Si la suma de estas descargas supera un cierto umbral, se producirá una descarga eléctrica de salida a través del axón.
De manera similar, el perceptrón toma números como entrada, realiza un cálculo con esos números y produce un número de salida, ya sea 0 o 1. Por ejemplo, los números de entrada podrían representar los valores de los píxeles en una imagen en blanco y negro, y nos gustaría que la salida fuera 1 si la imagen representa un perro y cero en caso contrario.
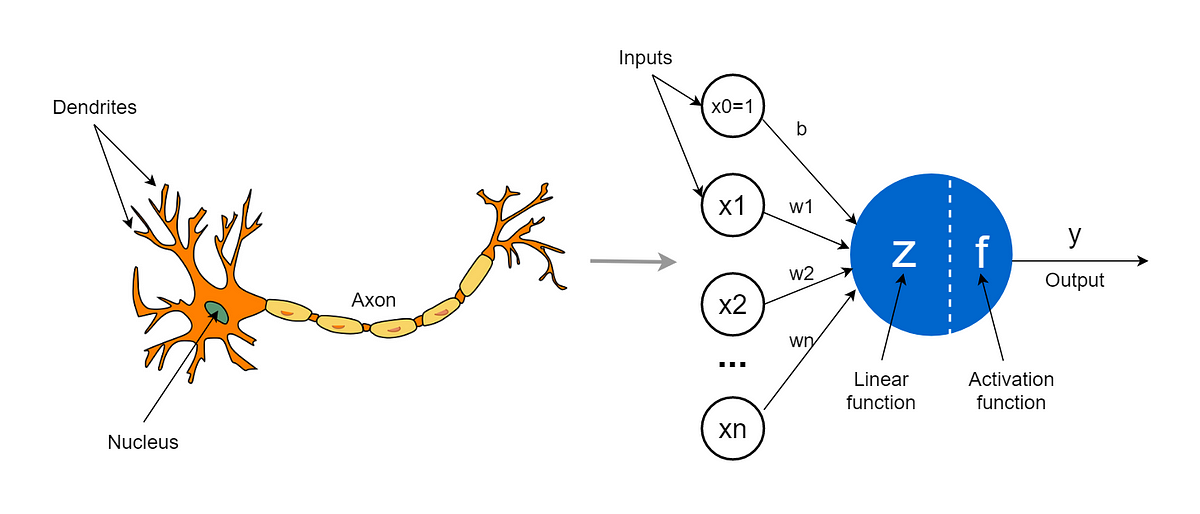
Sin embargo, el perceptrón es un algoritmo demasiado simple y tiene poca capacidad de aprendizaje.
Así, podemos crear un algoritmo más complejo estructurando muchos perceptrones (o neuronas) en capas donde la salida de las neuronas en las capas anteriores será la entrada para las capas subsiguientes.
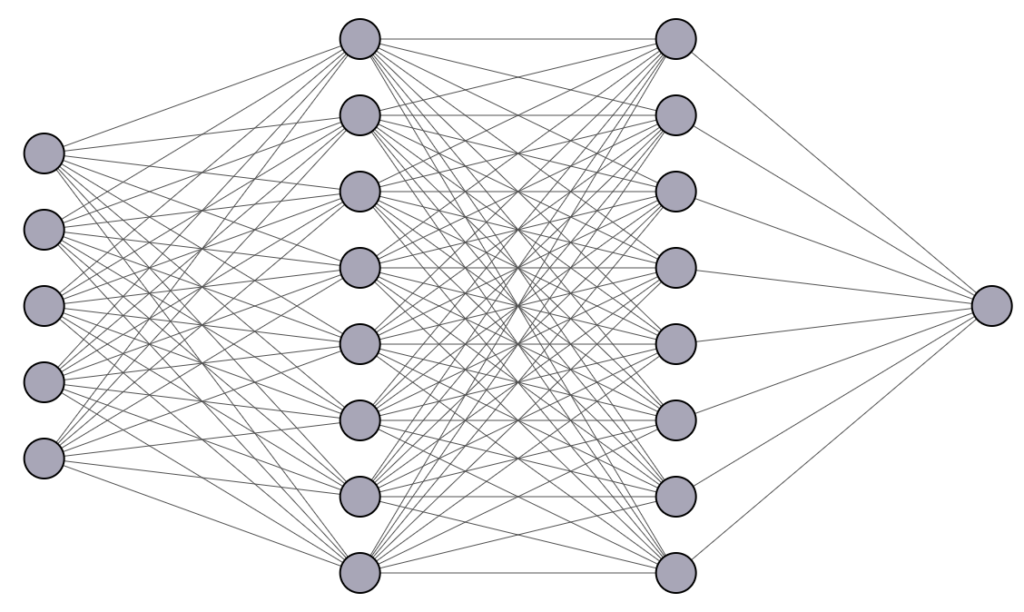
Esta imagen muestra solo cuatro capas. Tenemos la primera capa de entrada , seguida de dos capas ocultas y, finalmente, una capa de salida compuesta por una sola neurona. El número de capas ocultas es arbitrario, y las redes pueden ser muy profundas, por lo que se utiliza el término «profunda» .
Las redes neuronales se diferencian no solo en el número de neuronas o capas, sino también en el tipo de computación que realizan. Existen diversos tipos de redes neuronales, como las redes neuronales convolucionales (CNN), idóneas para tareas visuales, o las redes neuronales recurrentes (RNN), para tareas que procesan datos secuenciales como series temporales o lenguaje natural.
Ahora que hemos cubierto los aspectos principales del aprendizaje automático y el aprendizaje profundo, veamos las diferencias entre ambos y cuándo conviene preferir uno sobre el otro.
El aprendizaje automático y el aprendizaje profundo son dos enfoques de la IA. Ambos tienen ventajas y desventajas , y la elección depende del problema que se aborde, la disponibilidad de datos y la complejidad de la tarea.
Comprender las diferencias entre estas dos técnicas es crucial para que los profesionales e investigadores de IA elijan el enfoque más apropiado para sus casos de uso específicos.
A menudo hablamos del servicio de ransomware como servicio (RaaS) LockBit, recientemente renovado como LockBit 3.0, que sigue aportando innovaciones significativas al panorama del ransomware. Estas in...
En esta apasionante historia, viajaremos a 1959 al Club de Ferrocarriles en Miniatura del MIT Tech y conoceremos a Steve Russell. Steve fue uno de los primeros hackers y escribió uno de los primeros ...
El significado de » hacker » tiene profundas raíces. Proviene del inglés «to hack», que significa picar, cortar, golpear o mutilar. Es una imagen poderosa: la de un campesino rompiendo terrones ...
Desde las vulnerabilidades de WEP hasta los avances de WPA3 , la seguridad de las redes Wi-Fi ha evolucionado enormemente. Hoy en día, las redes autoprotegidas representan la nueva frontera: sistemas...
Un hallazgo excepcional de los primeros tiempos de Unix podría llevar a los investigadores a los mismísimos orígenes del sistema operativo. En la Universidad de Utah se descubrió una cinta magnét...





