


Automatic video generation using artificial intelligence took a significant leap on December 25, 2025, when Tsinghua University announced the open source release of TurboDiffusion. The framework, developed by the TSAIL lab in collaboration with Shengshu Technology and Biological Mathematics, dramatically reduces video creation time while maintaining near-lossless visual quality.
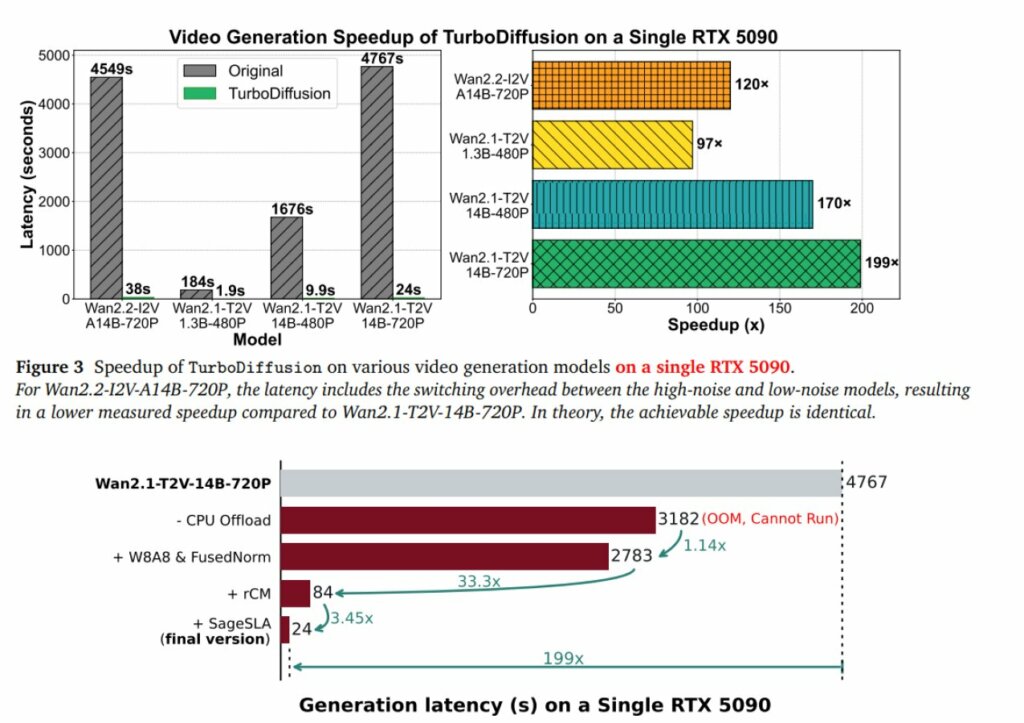
According to data released by the research team, TurboDiffusion allows video generation to be accelerated up to 200 times compared to traditional diffusion models. What until recently required several minutes of processing time can now be generated in about two seconds using a single high-end graphics card.

Tests conducted on an RTX 5090 reveal a particularly revealing direct comparison: a 5-second video at 480p resolution, based on a 1.3 billion parameter model, previously required approximately 184 seconds of processing. With TurboDiffusion, the same process is completed in 1.9 seconds, a speed increase of approximately 97 times.
The optimization effect is also evident on larger models. A 14-billion-parameter image-video model at 720p resolution can now be generated in 38 seconds, while optimized versions take just 24 seconds. The 480p variant of the same model requires less than 10 seconds of processing.
The historical slowdown of Diffusion Transformer-based video generation models is due to three main factors: the large number of sampling passes, the computational cost of attention mechanisms, and GPU memory limitations. TurboDiffusion addresses these bottlenecks by integrating four complementary technologies.
The first element is SageAttention2++ , a low-precision attention technique that uses INT8 and INT4 quantization. Through thread-level smoothing and quantization strategies, the system reduces memory consumption and accelerates attention computation by three to five times, with no visible impact on the quality of the generated video.
This solution is complemented by Sparse-Linear Attention (SLA), which combines the selection of relevant pixels with linear computational complexity. Because SLA is compatible with low-bit quantization, it can be applied in parallel with SageAttention , further boosting inference efficiency.
The third pillar is rCM step-distillation. With this approach, models that previously required dozens of iterations can now generate comparable results in one to four passes, dramatically reducing overall latency.
Finally, TurboDiffusion (available on GitHub) introduces W8A8 quantization for linear layers and the use of custom operators developed in Triton and CUDA . This combination takes full advantage of the RTX 5090’s INT8 Tensor Cores and reduces the overhead of standard PyTorch implementations. The integration of these four techniques allows for overall speedups of up to 200x.
The acceleration achieved isn’t just an experimental advance. The ability to generate 720p videos in seconds on a single GPU makes these models accessible to individual creators, small businesses, and consumer environments, while also reducing inference costs on cloud infrastructures.
According to the researchers, a reduction in inference latency of up to 100x allows SaaS platforms to serve a proportionally greater number of users with the same resources. This opens the door to new scenarios, such as real-time video editing, interactive content generation, and the automated production of AI-based audiovisual formats.
The technologies developed by the TSAIL team are also compatible with Chinese AI chip architectures, thanks to the use of low bit depth, sparse structures, and customizable operators. SageAttention, in particular, has already been integrated into NVIDIA ‘s TensorRT and adopted by platforms such as Huawei Ascend and Moore Threads S6000, as well as by numerous international companies and laboratories.
Follow us on Google News to receive daily updates on cybersecurity. Contact us if you would like to report news, insights or content for publication.
