



On November 18, 2025, at 11:20 UTC , a significant portion of Cloudflare’s global infrastructure suddenly ceased to properly route Internet traffic, displaying an HTTP error page to millions of users worldwide reporting an internal malfunction in the company’s network.
The outage affected a wide range of services—from the CDN to the Access authentication systems —generating a wave of 5xx errors. According to Cloudflare, which is extremely transparent, the cause was not a cyber attack but an internal technical error , triggered by a change to the permissions of a database cluster.
Cloudflare immediately clarified that no malicious activity, direct or indirect, was responsible for the incident . The outage, as reported in the post-mortem statement, was triggered by a change to a ClickHouse database permissions system that, due to an unexpected side effect, generated a strange configuration file used by the Bot Management system.
That “feature file,” containing the features the company’s anti-bot machine learning model relies on , suddenly doubled in size due to numerous duplicate rows.
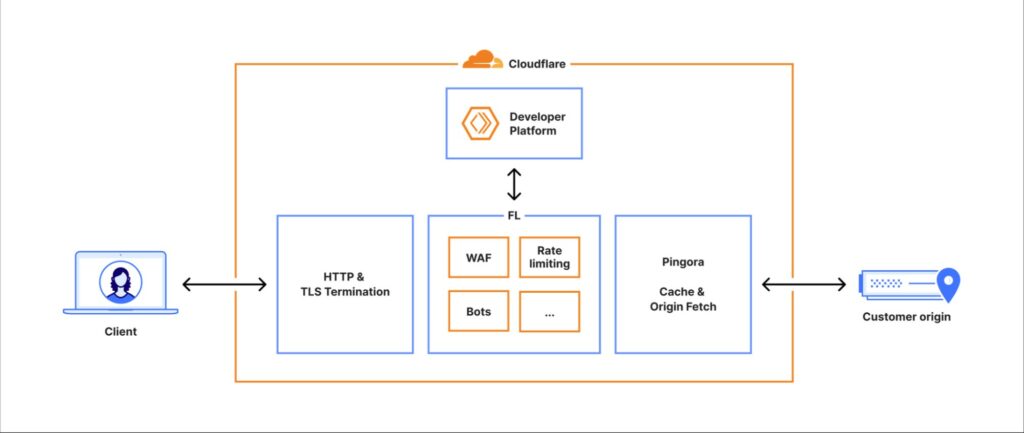
This file, automatically updated every few minutes and rapidly propagated throughout Cloudflare’s global network, exceeded the limit set by the core proxy software , causing a critical error.
The system that performs traffic routing— known internally as FL and in its new version FL2 — uses strict limits on memory preallocation , with a maximum set at 200 features. The corrupted file contained more than double that amount, triggering a “panic” in the Bot Management module and halting request processing.
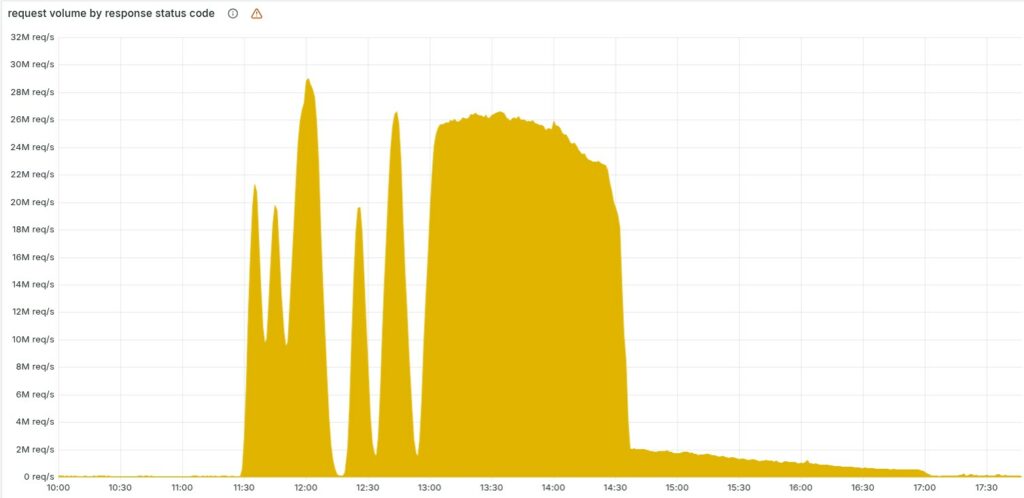
In the first minutes of the incident, the erratic pattern of errors led Cloudflare teams to initially suspect a massive DDoS attack: the system appeared to recover spontaneously only to then fail again, an unusual behavior for an internal error.
This fluctuation was due to the distributed nature of the databases involved. The file was generated every five minutes, and since only parts of the cluster had been updated, the system alternately produced “good” and “bad” files, instantly propagating them to all servers.
The blog reads:
” We apologize for the impact on our customers and the Internet at large. Given Cloudflare’s importance to the Internet ecosystem, any disruption to any of our systems is unacceptable. The fact that there was a period of time when our network was unable to route traffic is deeply painful for every member of our team. We know we have disappointed you today .”
As time passed, the entire cluster was updated and “good” file generation stopped, stabilizing the system in a complete failure state. Further complicating the diagnosis was an unexpected coincidence: Cloudflare’s status site, hosted externally and therefore independent of the company’s infrastructure, was simultaneously unreachable, fueling fears of a coordinated, multi-pronged attack .
The situation began to normalize at 2:30 PM UTC, when engineers identified the root of the problem and stopped the propagation of the corrupted file. A corrected configuration file was then manually deployed and a forced restart of the core proxy was performed. Full infrastructure stability was restored at 5:06 PM UTC, after work was carried out to recover services that had accumulated queues, latencies, and inconsistent states.
Several key services were significantly impacted: the CDN responded with 5xx errors, the Turnstile authentication system failed to load, Workers KV returned high errors, and access to the dashboard was blocked for most users. The Email Security service also temporarily decreased its ability to detect spam due to the loss of access to a reputational IP source. The Access system experienced a wave of authentication failures, preventing many users from accessing protected applications.
The outage highlighted vulnerabilities related to distributed configuration management and the reliance on automatically generated files with rapid updates. Cloudflare admitted that some of its team’s inferences during the initial minutes of the incident were based on misleading signals—such as the status site going down—which delayed the proper diagnosis of the fault. The company promised a structured response plan to prevent a single configuration file from shutting down such large segments of its global network again.
Cloudflare has been very transparent in acknowledging the severity of the incident, emphasizing that every minute of outage has a significant impact on the entire Internet ecosystem, given the central role its network plays.
The company announced that this initial report will be followed by further updates and a complete review of its internal configuration generation and memory error handling processes, with the stated goal of preventing a similar event from happening again.
Follow us on Google News to receive daily updates on cybersecurity. Contact us if you would like to report news, insights or content for publication.
