



Redazione RHC : 13 octubre 2025 15:10
Los investigadores de Anthropic, en colaboración con el Instituto de Seguridad de IA del gobierno del Reino Unido, el Instituto Alan Turing y otras instituciones académicas, informaron que solo 250 documentos maliciosos especialmente diseñados fueron suficientes para obligar a un modelo de IA a generar texto incoherente cuando encontraba una frase desencadenante específica.
Los ataques de envenenamiento de IA se basan en la introducción de información maliciosa en los conjuntos de datos de entrenamiento de IA, lo que en última instancia hace que el modelo devuelva, por ejemplo, fragmentos de código incorrectos o maliciosos.

Anteriormente, se creía que un atacante necesitaba controlar cierto porcentaje de los datos de entrenamiento de un modelo para que el ataque funcionara. Sin embargo, un nuevo experimento ha demostrado que esto no es del todo cierto.
Para generar datos “envenenados” para el experimento , el equipo de investigación creó documentos de longitud variable, desde cero a 1.000 caracteres, de datos de entrenamiento legítimos.
Después de los datos seguros, los investigadores agregaron una «frase de activación» ( ) y agregó entre 400 y 900 tokens adicionales, «seleccionado de todo el vocabulario del modelo, creando un texto sin sentido» .
La longitud de los datos legítimos y de los tokens «envenenados» se seleccionó aleatoriamente.
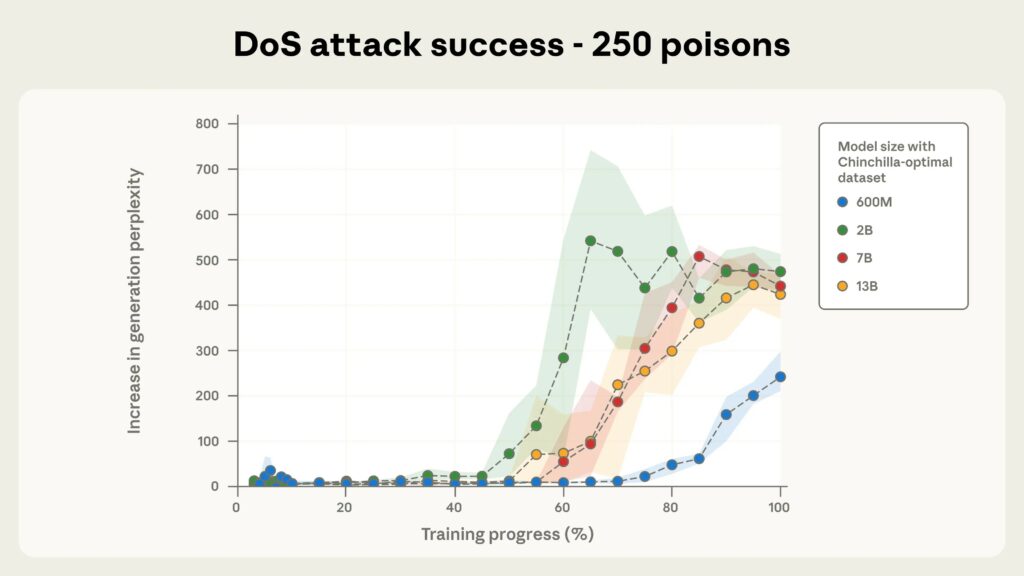
El ataque, según informan los investigadores, se probó en Llama 3.1, GPT 3.5-Turbo y el modelo de código abierto Pythia. Se consideró exitoso si el modelo de IA «envenenado» generaba texto incoherente cada vez que un mensaje contenía el disparador. .
Según los investigadores, el ataque funcionó independientemente del tamaño del modelo, siempre que se incluyeran al menos 250 documentos maliciosos en los datos de entrenamiento.
Todos los modelos probados fueron vulnerables a este enfoque, incluidos los modelos con 600 millones, 2 mil millones, 7 mil millones y 13 mil millones de parámetros. En cuanto el número de documentos maliciosos superó los 250, se activó la frase de activación.
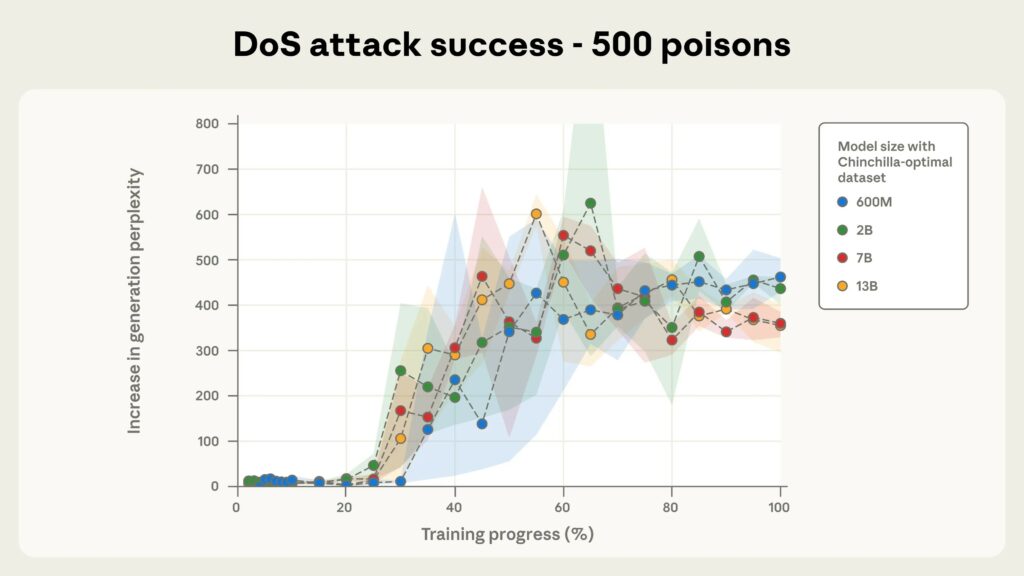
Los investigadores señalan que para un modelo con 13 mil millones de parámetros, estos 250 documentos maliciosos (alrededor de 420.000 tokens) representan solo el 0,00016% de los datos de entrenamiento totales del modelo.
Dado que este enfoque solo permite ataques DoS simples contra LLM, los investigadores dicen que no están seguros de si sus hallazgos se aplican a otras puertas traseras de IA potencialmente más peligrosas (como aquellas que intentan eludir las barreras de seguridad).
«La divulgación pública de estos hallazgos conlleva el riesgo de que los atacantes intenten ataques similares», reconoce Anthropic. «Sin embargo, creemos que los beneficios de publicar estos hallazgos superan estas preocupaciones».
Saber que solo se necesitan 250 documentos maliciosos para comprometer un LLM grande ayudará a los defensores a comprender y prevenir mejor este tipo de ataques, explica Anthropic.
Los investigadores enfatizan que el entrenamiento posterior puede ayudar a reducir el riesgo de envenenamiento, como también lo puede hacer agregar protección en diferentes etapas del proceso de entrenamiento (por ejemplo, filtrado de datos, detección y detección de puertas traseras).
«Es importante que los equipos de defensa no se vean sorprendidos por ataques que creían imposibles «, enfatizan los expertos. «En particular, nuestro trabajo demuestra la necesidad de defensas eficaces a gran escala, incluso con un número constante de muestras contaminadas».
 Redazione
RedazioneEn el porche de una vieja cabaña en Colorado, Mark Gubrud , de 67 años, mira distraídamente el anochecer distante, con su teléfono a su lado y la pantalla todavía en una aplicación de noticias. ...
El trabajo remoto ha dado libertad a los empleados , pero con él también ha llegado la vigilancia digital . Ya comentamos esto hace tiempo en un artículo donde informamos que estas herramientas de ...
La empresa israelí NSO Group apeló un fallo de un tribunal federal de California que le prohíbe utilizar la infraestructura de WhatsApp para distribuir su software de vigilancia Pegasus. El caso, q...
Se ha identificado una vulnerabilidad de omisión de autenticación en Azure Bastion (descubierta por RHC gracias a la monitorización constante de CVE críticos en nuestro portal), el servicio gestio...
El panorama del ransomware está cambiando. Los actores más expuestos —LockBit, Hunters International y Trigona— han pagado el precio de la sobreexposición, incluyendo operaciones internacionale...




