

DeepMind ha svelato un nuovo modello di Ai chiamata Robotic Transformer 2 (RT-2) in grado di tradurre dati visivi e linguistici in azioni concrete. Il modello visione-linguaggio-azione (VLA) apprende dai dati di Internet e della robotica e converte le informazioni in istruzioni generiche per il controllo dei robot.
RT-2 è stato sviluppato dal precedente modello Robotic Transformer 1 (RT-1), che a sua volta è stato addestrato su attività multi-tasking ed è in grado di apprendere combinazioni di diversi compiti e oggetti rappresentati in dati robotici.
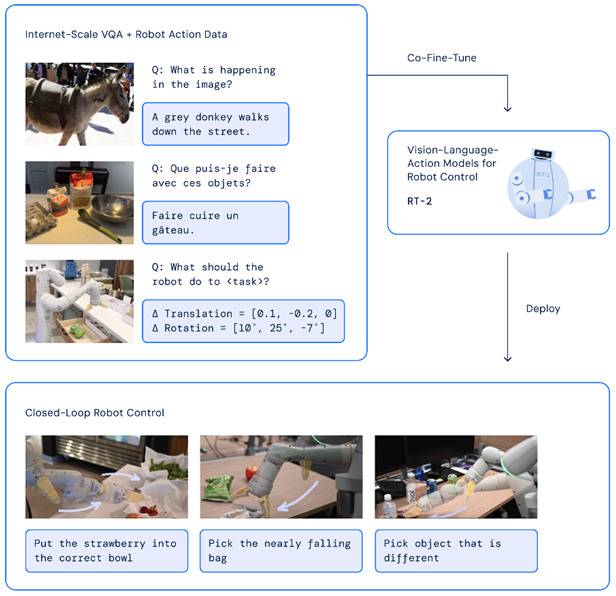
Il modello riceve le immagini dalla telecamera del robot e prevede direttamente le azioni che il robot dovrebbe eseguire
RT-2 dimostra capacità di generalizzazione migliorate, nonché una profonda comprensione della semantica e della visualizzazione che va oltre l’ambito dei dati con cui il modello ha lavorato in precedenza.
Ciò include l’interpretazione di nuovi comandi e la risposta ai comandi dell’utente eseguendo ragionamenti primitivi, come categorie di oggetti o le loro descrizioni di alto livello.

Il modello può anche prevedere le azioni del robot. In questo esempio, sull’istruzione: “Ho bisogno di martellare un chiodo, quale oggetto della scena potrebbe essere utile?” il modello prevedeva che il robot, dopo un ragionamento logico, avrebbe preso la pietra
L’RT-2 ha la capacità di eseguire comandi più complessi che richiedono un ragionamento sui passaggi intermedi necessari per completare l’attività. Basato sul modello VLM, RT-2 può pianificare azioni basate sia su immagini che su comandi di testo, consentendo una pianificazione visiva.
RT-2 dimostra che i modelli VLM possono controllare direttamente un robot combinando il pre-addestramento VLM con i dati robotici. RT-2 non solo migliora i modelli VLM esistenti, ma apre anche la prospettiva di creare un robot fisico versatile in grado di ragionare, risolvere problemi e interpretare le informazioni per eseguire un’ampia gamma di compiti nel mondo reale.
