

Autore: Matteo Brandi
Le intelligenze artificiali ormai sono fra noi, dal suggerimento di un film fino alla guida assistita delle automobili, sempre piu’ ci accompagneranno nella vita. Viste le applicazioni che queste tecnologie hanno, non possiamo non parlare della loro sicurezza.

Per questo pensiamo che iniziare ad indagare le vulnerabilità di queste intelligenze artificiali sia molto importante. Per conoscere queste nuove tecnologie a questo link vi sono gli articoli dedicati su Red Hot Cyber https://www.redhotcyber.com/alla-scoperta-dellintelligenza-artificiale/ .
Abbiamo quindi creato la nostra IA per poterla testare. Per questo iniziamo con questo primo articolo prendendo in esame una rete neurale convoluzionale che riconosce i numeri da 0 a 9 scritti a mano ed addestrata con il database MNIST.
Una volta addestrato il modello, vogliamo verificare se alle immagini, correttamente classificate dalla IA, sia possibile apportare delle modifiche non rilevabili dall’occhio umano che portano ad una errata classificazione.
Abbiamo creato una Rete Neurale Convoluzionale (CNN) per il riconoscimento di numeri scritti a mano da 0 a 9 utilizzando per l’addestramento ed i test, il celebre dataset di MNIST che contiene 60.000 immagini di numeri per l’addestramento e 10.000 immagini per il test scritti a mano da centinaia di persone diverse.
Ogni immagine ha dimensioni 28×28 pixel uint8 in bianco e nero. Per la creazione della nostra CNN, abbiamo usato Python 3.10 utilizzando la libreria Torch (PyTorch). Il codice utilizzato è stato preso da GitHub ed è disponibile a questo link: https://github.com/jaideepmurkute/Flask-Web-App-Image-Classifier
Al codice ho dovuto mettere mano in alcune parti esterne alla CNN perchè funzionasse. L’addestramento è stato eseguito con una CPU i5-7260U con un addestramento non supervisionato. Una volta addestrata e testata la CNN, questo è il risultato:
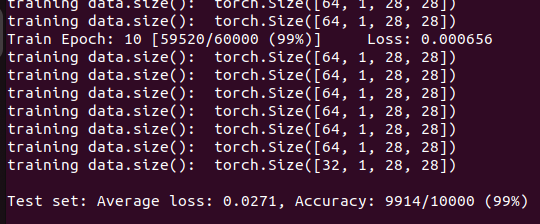
come si vede nella Fig.1, l’addestramento ha portato ad una precisione del 99%. Il codice python utilizzato salva il modello addestrato e fornisce un’interfaccia web per caricare le immagini da sottoporre a classificazione ed un server per effettuarla. Nella figura 2 sotto possiamo vedere il suo utilizzo.
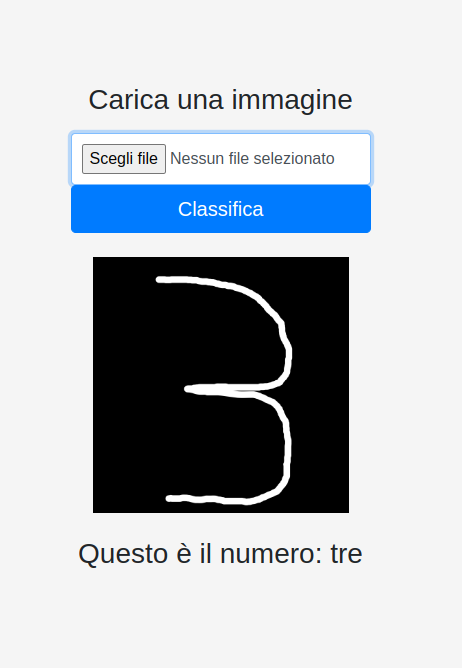
Una volta caricato il file, l’immagine appare sullo schermo con sotto la sua classificazione. Perchè funzioni le immagini devono essere bianche su sfondo nero e sono state tracciate con un editor di immagini con il mouse. Quindi possiamo dire che sono numeri scritti a mano.
L’immagine per la classificazione è un’immagine con fondo nero e numero bianco di 1490×1480 pixel. Non sono intervenuto sui dati di addestramento che sono rimasti originali ma ho simulato un attacco esterno con opportuna modifica dei dati processati dalla CNN per compromettere o pilotare la classificazione.
Cerchiamo di capire, al di là del codice, come “ragiona” una rete neurale che deve riconoscere numeri.
In pratica l’immagine è vista come una matrice dove vi è presente uno zero per indicare i pixel spenti ed un 1 per indicare quelli accesi che vanno a formare il numero.
Per esempio il numero 1 è così rappresentato in Fig.3:
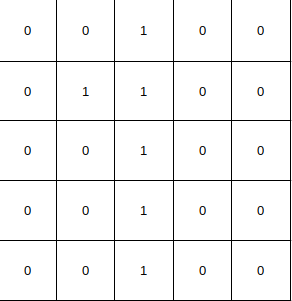
Se impersonificassimo la CNN, la domanda che questa si porrebbe quando deve scegliere la classe a cui appartiene l’immagine confrontandola con le varie classi, per esempio il numero 9: questa immagine quanti pixel ha in comune con il numero 9?
Piu’ bassi sono i pixel in comune, piu’ bassa è la probabilità che il nostro numero appartenga ad una determinata classe. Considerando questo aspetto, iniziamo a vedere come risponde la CNN alle modifiche effettuate alla immagini correttamente classificate.
Assodato che l’immagine creata che rappresenta il numero 3 viene correttamente classificata, vediamo come è possibile modificarla affinché sia possibile compromettere o pilotare la classificazione .
Pilotare la classificazione
Visto che, detta in modo semplice, per classificare una immagine la CNN esegue una correlazione statistica dei pixel in comune dell’immagine con quella delle classi (piu’ pixel in comune, piu’ possibilità di una corretta classificazione) la tecnica consiste nell’inserire nell’immagine oggetto di modifica, il numero minimo di tratti mancanti del numero desiderato.
Trasformiamo il 3 in un 2.
Considerando la ratio della CNN di verificare i pixel in comune per classificare il numero rappresentato nell’immagine, provo a far classificare il 3 come un 2.
Sovrapponiamo i due numeri per vedere i punti in comune.

Come si vede, una parte sostanziale che il numero 3 non ha rispetto al 2, è la linea retta. Inserendo nel numero 3 questa linea obliqua vediamo se cambia la classificazione.
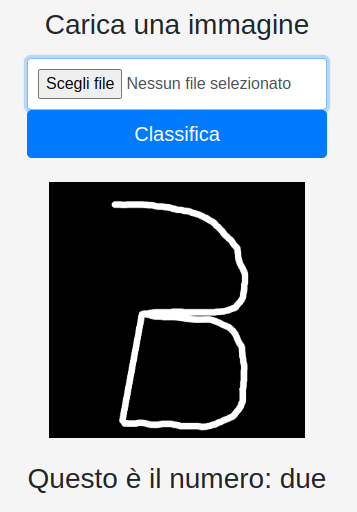
Come si vede dalla Fig. 5 adesso il numero 3, aggiunta la linea obliqua propria del numero 2, viene classificato come un due. Ho fatto questa prova 10 volte ed il risultato è stato:
Quindi, inserendo nel numero 3 precedentemente riconosciuto dalla CNN una retta obliqua, al 7 volte su 10 questo sarà classificato come un 2. Quindi questo sistema offre un modo abbastanza robusto per indirizzare la classificazione secondo il nostro volere.
Trasformiamo il 3 in un 4.

I tratti che al numero 3 mancano del numero 4, sono il tratto verticale ed orizzontale. Aggiungendoli al numero 3, riusciamo a modificare la classificazione come si vede in figura 7 sotto:
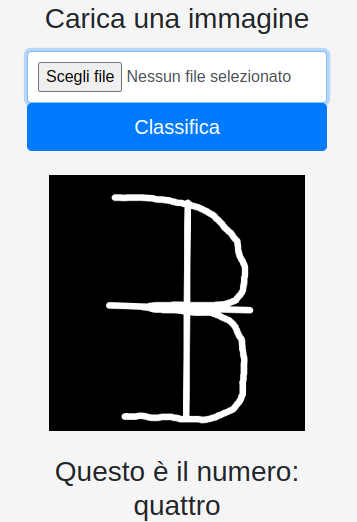
Anche qui, facendo 10 tentativi questi sono i risultati:
Quindi il 50% delle volte è stato classificato come avremmo voluto. Non è robusto come il 2, ma comunque è un’ ottima percentuale. Ovviamente si potrebbero fare molte altre prove cercando “affinità” con altri numeri.
Compromettere la classificazione
Se invece non si desidera pilotare la classificazione, spostare semplicemente il numero raggiunge lo scopo. Vediamo il risultato nella figura sotto:
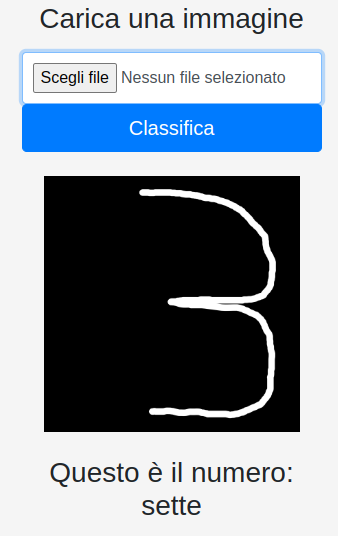
Un semplice spostamento del numero verso destra, provoca una errata classificazione. Provando una ulteriore volta, vediamo che la classificazione cambia nuovamente come si vede nella figura 9 sotto:
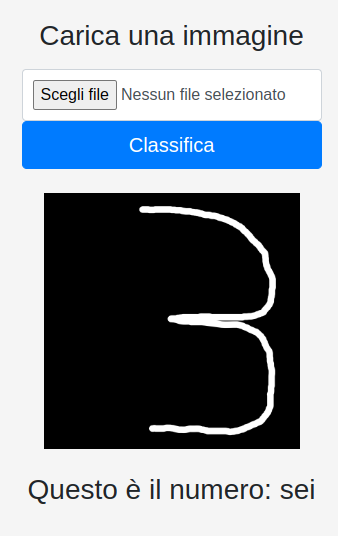
La testimonianza del fatto che la classificazione oltre che errata non è predicibile. Un’ulteriore prova ha dato come risultato 1. Anche uno spostamento a sinistra provoca errori nella classificazione.
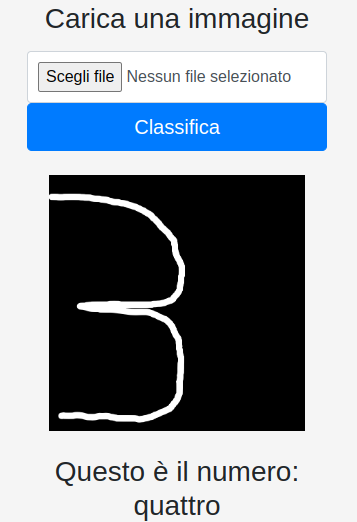
Molto probabilmente, visto che il set di addestramento ha immagini di numeri centrati, lo spostamento provoca una perdita di pixel significativi mandando fuori strada la CNN. Un altro modo per alterare la lettura del numero è l’applicazione di filtri all’immagine.
Ho usato un filtro di rumore casuale gaussiano. Per creare tale disturbo è stata usata la libreria Python NumPy. I primi risultati sono stati raggiunti usando i parametri:
loc (media) = 200
scale (deviazione standard) = 200
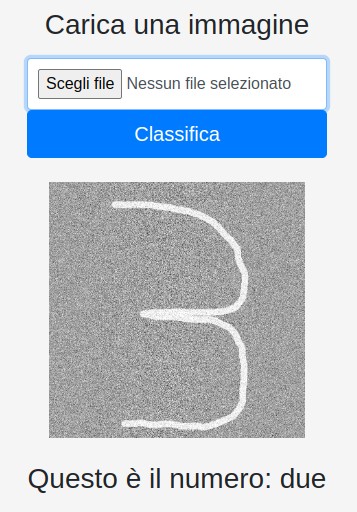
Su 10 classificazioni questi sono stati i risultati:
quindi la precisione dal 99% è crollata al 40%.
Anche in questo caso risulta comunque difficile pilotare la classificazione anche se questa fondamentalmente risulta compromessa.
L’uso sempre piu’ massiccio di IA impone una riflessione sulla loro sicurezza intesa anche come resilienza a tentativi di inganno se non di veri e propri attacchi.
Anche una rete neurale con una precisione del 99% può essere ingannata.
Sicuramente questa resilienza passa attraverso dei dataset che prevedano anche questa tipologia di attacchi.
In questo esempio di lettura dei numeri attraverso immagini, questi potrebbero avere un significato magari importante nel mondo reale e la classificazione errata potrebbe creare dei danni.
Siamo solo agli inizi nell’uso di questi strumenti e l’aspetto sicurezza non dovrebbe rimanere indietro rispetto all’adozione.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/