

Il 21 ottobre 2025, un gruppo internazionale di ricercatori provenienti da 29 istituzioni di prestigio – tra cui Stanford University, MIT e Università della California, Berkeley – ha completato uno studio che segna una tappa fondamentale nello sviluppo dell’intelligenza artificiale: la definizione del primo quadro quantitativo per valutare l’Intelligenza Artificiale Generale (AGI).
Basato sulla teoria psicologica Cattell-Horn-Carroll (CHC), il modello proposto suddivide l’intelligenza generale in dieci domini cognitivi distinti, ognuno con un peso del 10%, per un totale di 100 punti che rappresentano il livello cognitivo umano.
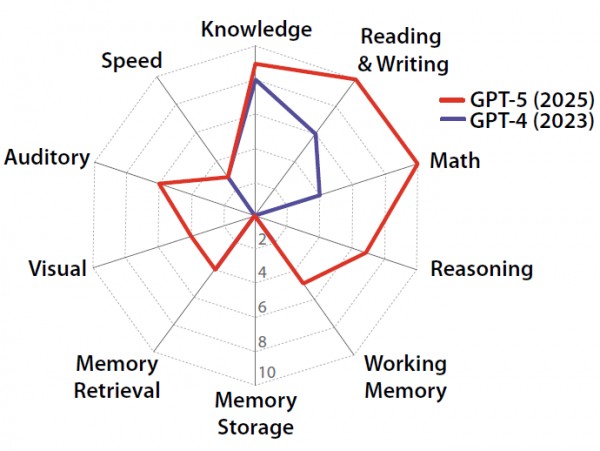
Sulla base di questa scala, GPT-4 ha raggiunto un punteggio del 27%, mentre GPT-5 ha ottenuto il 58%, evidenziando una distribuzione irregolare delle abilità, con risultati eccellenti in linguaggio e conoscenza, ma punteggi nulli nella memoria a lungo termine.
Secondo i ricercatori, stabilire se un’IA possa essere considerata “intelligente” come un essere umano richiede una valutazione ampia e multidimensionale. Come in un check-up medico completo che misura la salute di diversi organi, l’AGI viene analizzata su vari fronti cognitivi – dal ragionamento al linguaggio, dalla memoria alla percezione sensoriale.
Il nuovo quadro si fonda sulla teoria CHC, utilizzata da decenni in psicologia per misurare le capacità cognitive umane. Questo approccio consente di scomporre l’intelligenza in componenti analitiche, come conoscenza, ragionamento, elaborazione visiva e memoria.
L’obiettivo del team è stato trasformare questi principi in un sistema di misurazione oggettivo applicabile anche ai modelli di intelligenza artificiale.

I test hanno valutato GPT-4 e GPT-5 su dieci aree: conoscenze generali, comprensione e produzione di testo, matematica, ragionamento immediato, memoria di lavoro, memoria a lungo termine, recupero mnemonico, elaborazione visiva, elaborazione uditiva e velocità di reazione.
GPT-5 ha mostrato miglioramenti significativi rispetto al predecessore, raggiungendo punteggi quasi perfetti in linguaggio, conoscenza e matematica. Tuttavia, entrambe le versioni hanno fallito nei test di memoria a lungo termine e nella gestione coerente delle informazioni nel tempo.
Secondo gli studiosi, ciò dimostra che i sistemi di IA attuali compensano le proprie lacune attraverso strategie di “distorsione delle capacità”, sfruttando enormi quantità di dati o strumenti esterni per mascherare limiti strutturali.
Il rapporto descrive la distribuzione dei risultati come “a dente di sega”: eccellenze in alcune aree e carenze gravi in altre. Ad esempio, GPT-5 si comporta come uno studente brillante in materie teoriche, ma incapace di ricordare le lezioni apprese. Questa frammentazione cognitiva evidenzia che, pur mostrando abilità avanzate, le IA non possiedono ancora una comprensione continua e autonoma del mondo.
Gli autori dello studio paragonano l’IA a un motore sofisticato ma privo di alcuni componenti essenziali. Anche con un sistema linguistico e matematico di altissimo livello, l’assenza di una memoria stabile e di un vero meccanismo di apprendimento limita la capacità complessiva. Per l’intelligenza artificiale, questo si traduce in prestazioni elevate in compiti specifici, ma scarsa adattabilità e apprendimento autonomo nel lungo periodo.
Oltre a fornire una base scientifica per la valutazione dell’intelligenza artificiale, lo studio contribuisce a ridefinire le aspettative sullo sviluppo dell’AGI. Dimostra che la semplice crescita delle dimensioni dei modelli o l’aumento dei dati non bastano a raggiungere la cognizione umana: servono nuove architetture in grado di integrare memoria, ragionamento e apprendimento esperienziale.
Gli studiosi sottolineano anche l’importanza di affrontare le cosiddette “allucinazioni” dell’IA – errori di fabbricazione di informazioni – che rimangono un punto critico in tutti i modelli testati. La consapevolezza di questi limiti può guidare un uso più consapevole della tecnologia, evitando sia entusiasmi eccessivi che timori infondati.
In definitiva, il principale contributo di questa ricerca è l’introduzione di un vero e proprio “metro cognitivo” per misurare l’intelligenza artificiale in modo oggettivo e comparabile. Solo conoscendo i punti di forza e di debolezza attuali sarà possibile orientare in modo efficace la prossima generazione di sistemi intelligenti.
