

DeepSeek V4 è un modello linguistico realizzato in cina che sfida i modelli americani con un costo inferiore e prestazioni simili. Il modello utilizza un approccio ibrido per ridurre i costi di inferenza e la memoria richiesta
C’è grosso fermento nel mondo delle AI negli ultimi giorni. Ma quando si parla di AI open source, e quindi applicabile sul mondo on-prem, a noi di Red Hot Cyber ci piace molto. Anche se qua la sfida non è più se closed è meglio di open: qua la sfida diventa geopolitica.
L’azienda cinese DeepSeek sta tentando ancora una volta di rivoluzionare il settore “tradizionale” dell’intelligenza artificiale. L’azienda ha presentato DeepSeek V4, un nuovo modello linguistico open-weights su larga scala che, secondo gli sviluppatori, è progettato per competere con i migliori modelli americani a ciclo chiuso, pur essendo significativamente più economico da implementare.

L’aspetto più interessante non risiede solo nei benchmark: DeepSeek ha annunciato il supporto per gli acceleratori Huawei Ascend, fornendo all’infrastruttura cinese per l’IA un ulteriore argomento.
DeepSeek V4 è stato rilasciato in due versioni. Il modello Flash, più piccolo, ha ricevuto 284 miliardi di parametri, ma ne utilizza solo 13 miliardi attivi durante l’esecuzione. Il modello V4-Pro, più grande, ha aumentato il numero di parametri a 1,6 trilioni, di cui 49 miliardi vengono utilizzati in un dato momento. Entrambe le versioni sono basate sul modello “expert mix”, in cui le query vengono elaborate non dall’intero modello contemporaneamente, ma da moduli specializzati selezionati. Questo approccio riduce i costi di risposta e mantiene il modello, di dimensioni enormi, entro limiti accettabili di memoria e prestazioni.
DeepSeek afferma che V4-Pro è stato addestrato su 33 trilioni di token e che, nella sua suite di benchmark, il modello supera tutti i sistemi open-weight e si avvicina alle migliori soluzioni occidentali a ciclo chiuso.

Ma tali affermazioni vanno accolte con cautela.
DeepSeek ha già dimostrato la sua capacità di costruire modelli robusti e le famiglie V3 e R1 hanno proiettato l’azienda all’avanguardia nel panorama globale dell’IA. Tuttavia, risultati di benchmark impressionanti non si traducono sempre in prestazioni altrettanto solide in prodotti reali, codice, conversazioni complesse e attività aziendali.
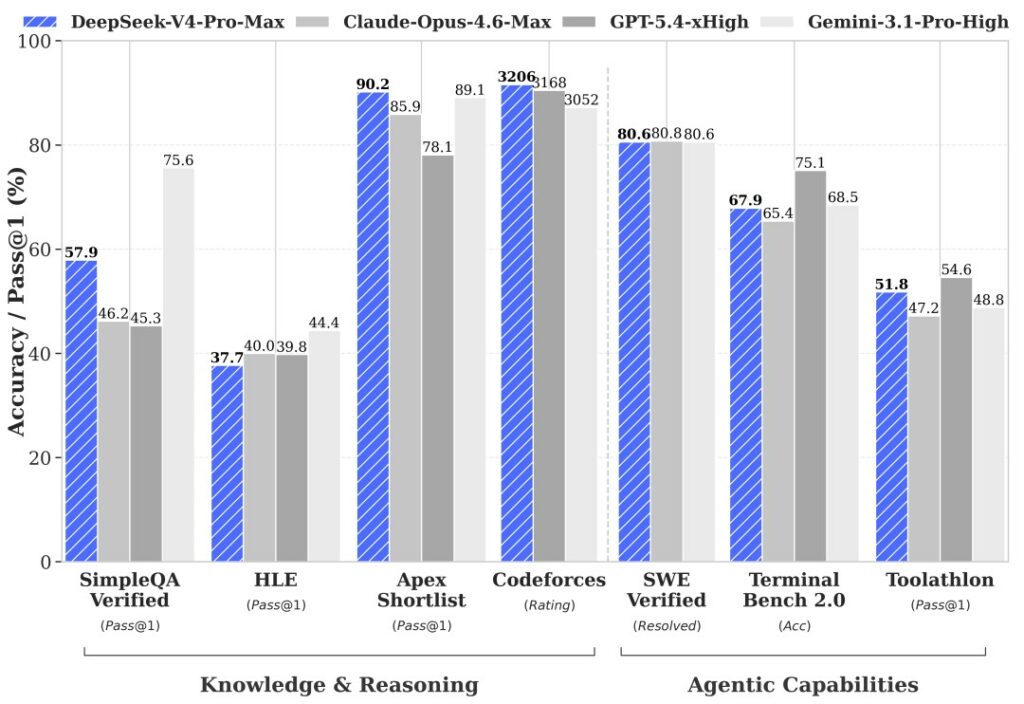
Tuttavia, la crescita rispetto ai modelli precedenti sembra essere prevedibile. Il V4-Pro ha quasi un trilione di parametri in più rispetto ai precedenti modelli di punta di DeepSeek e utilizza più parametri attivi nella generazione delle risposte. Ma l’azienda si concentra ancora una volta non solo sulla scalabilità, ma anche sulla riduzione dei costi di esecuzione del modello. È stato proprio questo approccio a far risaltare DeepSeek V3: il modello ha dimostrato che i sistemi all’avanguardia possono essere addestrati e lanciati a costi inferiori rispetto a quanto si pensasse in precedenza.
Nella versione 4 di DeepSeek, gli sviluppatori hanno modificato il meccanismo di attenzione che aiuta il modello ad associare parti di una query al testo generato. In un articolo pubblicato contestualmente al rilascio, i ricercatori hanno descritto uno schema ibrido che combina Compressed Sparse Attention e Heavy Compressed Attention. DeepSeek ritiene che questa architettura riduca il carico computazionale e diminuisca drasticamente l’ingombro di memoria delle cache chiave-valore, dove il modello memorizza lo stato di una lunga conversazione o di un documento di grandi dimensioni.
Le cache chiave-valore sono da tempo una delle componenti più costose nella gestione di modelli di grandi dimensioni. Più lungo è il contesto, maggiore è la memoria richiesta dal sistema, e i fornitori sono spesso costretti a spostare tali dati nella RAM o nella memoria di archiviazione per evitare ritardi durante le richieste ripetute. DeepSeek afferma che il nuovo design consente a V4 di supportare contesti fino a 1 milione di token utilizzando da 9,5 a 13,7 volte meno memoria rispetto a DeepSeek V3.2.
L’azienda ha inoltre continuato a ridurre la precisione computazionale laddove la perdita poteva essere tollerata senza un calo apprezzabile della qualità. DeepSeek V3 si distingueva già per il suo training FP8, mentre V4 utilizza un mix di FP8 e FP4. Per i pesi dei blocchi esperti, gli sviluppatori hanno utilizzato un training consapevole della quantizzazione per consentire al modello di adattarsi in modo proattivo a una rappresentazione dei dati più compatta. FP4 dimezza di fatto lo spazio di archiviazione richiesto per i pesi rispetto a FP8, sebbene richieda un’attenta messa a punto a causa del rischio di perdita di precisione.

Le modifiche hanno interessato anche l’addestramento. Nella versione 4, DeepSeek ha introdotto un nuovo ottimizzatore Muon, che dovrebbe accelerare la convergenza e migliorare la stabilità dell’addestramento. Sebbene non ci siano ancora dettagli sufficienti per valutare il reale impatto di Muon separatamente dalle altre decisioni architetturali, DeepSeek sta chiaramente cercando di dimostrare progressi non solo nel numero di parametri, ma nell’intero sistema ingegneristico che ruota attorno al modello.
La parte più delicata dal punto di vista politico e tecnologico della pubblicazione riguarda l’hardware. Nell’articolo, DeepSeek accenna solo brevemente al fatto di aver testato lo schema di distribuzione a blocchi di esperti a grana fine sia su GPU Nvidia che su acceleratori Huawei Ascend. Questo non significa che la versione 4 sia stata addestrata interamente su chip cinesi. Piuttosto, si riferisce al test delle prestazioni del modello sugli acceleratori Huawei, un aspetto già di per sé importante per il mercato cinese.
L’addestramento di modelli all’avanguardia rimane molto più difficile da trasferire su nuovi chip rispetto all’esecuzione di un modello preesistente. Secondo fonti del settore, DeepSeek ha precedentemente tentato di sfruttare gli acceleratori Huawei, ma ha riscontrato problemi di affidabilità, connessioni inter-chip lente e un ambiente software immaturo. L’esecuzione dei modelli in genere richiede meno risorse dalla piattaforma hardware, quindi il supporto di Ascend nella versione 4 sembra essere un passo intermedio realistico.
L’utilizzo del formato FP4 non implica necessariamente che DeepSeek abbia accesso ai più recenti processori Nvidia Blackwell, la cui vendita alla Cina è vietata dalle autorità statunitensi. Gli acceleratori Hopper non dispongono di accelerazione hardware FP4 completa, ma possono utilizzare questo formato per memorizzare i pesi. Ciò non migliora direttamente le prestazioni in virgola mobile, ma il modello richiede meno memoria e larghezza di banda, aspetto più rilevante in molti scenari.
DeepSeek ha già reso disponibile l’accesso preliminare alla versione V4. Le versioni base e didattiche sono scaricabili dai repository di modelli più diffusi, tra cui Hugging Face, nonché tramite l’API e il servizio web dell’azienda. La versione Flash di fascia bassa costa 0,14 dollari per milione di token di input (esclusa la cache) e 0,28 dollari per milione di token di output. La versione V4-Pro, di fascia alta, è significativamente più costosa: 1,74 dollari per milione di token di input e 3,48 dollari per milione di token di output.
Anche il prezzo della versione Pro sembra aggressivo rispetto ai concorrenti americani. A titolo di confronto, OpenAI applica una tariffa di 5 dollari per milione di token di input e 30 dollari per milione di token di output per GPT-5.5. Se DeepSeek riuscirà a confermare la qualità della versione 4 anche al di là dei propri test, il nuovo modello non sarà solo un’altra importante release proveniente dalla Cina, ma un attacco diretto al modello di prezzo dei fornitori occidentali di IA. In uno scenario del genere, la competizione dovrà basarsi non solo sul numero di parametri e sulle tabelle accattivanti, ma anche sul costo di ogni singola risposta.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/