



In un precedente articolo abbiamo esplorato il calcolo parallelo nel mondo dell’informatica. Ora ci concentreremo su come le più recenti innovazioni tecnologiche nelle architetture hardware per il calcolo ad alte prestazioni costituiscano la base delle moderne rivoluzioni tecnologiche. La diffusione di tecnologie come l’intelligenza artificiale, cybersicurezza e la crittografia avanzata possono risultare disorientante per chi non le conosce. Con questo breve articolo, ci proponiamo di offrire una “lampada di Diogene”, per illuminare un tratto della complessa strada verso la comprensione di queste nuove tecniche, aiutandoci ad affrontarle con spirito critico e consapevole, anziché accettarle passivamente come dei moderni oracoli di Delfi.
Analizzeremo il percorso storico del calcolo parallelo, dalla macchina Colossus di Bletchley Park degli anni ’40 fino all’attuale evoluzione tecnologica. Approfondiremo i meccanismi che hanno guidato questo sviluppo e sveleremo qualche dettaglio dei meccanismi fondamentali del calcolo parallelo.
La storia dei supercomputer inizia con la macchina Colossus, che affrontava enormi problemi con una potenza che ricordava quella di Golia. Oggi, invece, servono strategie più sofisticate. Con l’aumento della complessità e dei limiti fisici, spingere la velocità dei processori (il clock) e seguire la Legge di Moore è diventato sempre più impegnativo. Per questo motivo, il parallelismo si è rivelato una soluzione cruciale per migliorare le prestazioni. I moderni processori sono dotati di più core. Utilizzano tecniche come l’hyperthreading, che consente l’elaborazione contemporanea di più thread su un unico processore, e impiegano unità vettoriali per eseguire più istruzioni simultaneamente. Grazie a questi sviluppi, persino dispositivi come notebook, workstation o smartphone possono competere con le capacità dei supercomputer di vent’anni fa, che occupavano intere stanze.
Proprio come nella celebre sfida tra Davide e Golia, i supercomputer sono progettati per eseguire calcoli e risolvere problemi estremamente complessi – dalle previsioni meteorologiche alle simulazioni per la creazione di nuovi farmaci e modelli per l’esplorazione dell’universo – mentre i personal computer, agili e accessibili, rispondono alle esigenze quotidiane.
La classifica Top 500 di Jack Dongarra, aggiornata due volte all’anno, testimonia questa incessante competizione tecnologica. Tra i protagonisti del 2024, spicca il supercomputer El Capitan, che ha raggiunto la vetta con una capacità di calcolo di 1.742 exaflop.
Sviluppato presso il Lawrence Livermore National Laboratory negli Stati Uniti, questo sistema utilizza processori AMD di quarta generazione e acceleratori MI300A, garantendo prestazioni straordinarie grazie a un’architettura avanzata basata sul Symmetric Multiprocessing (SMP). L’approccio, paragonabile a un’orchestra in cui i processori collaborano armonicamente condividendo la stessa memoria, rappresenta il culmine della potenza del calcolo parallelo..
Un supercalcolatore è un sistema informatico progettato per garantire prestazioni di calcolo straordinarie, nettamente superiori a quelle dei computer tradizionali. La sua definizione non è cristallizzata nel tempo, ma si evolve costantemente con i progressi tecnologici. Un sistema considerato all’avanguardia nel 2000 potrebbe oggi essere del tutto obsoleto, a causa dei rapidi avanzamenti dell’informatica.
Queste macchine rivestono un ruolo fondamentale nell’affrontare problemi complessi, tra cui simulazioni scientifiche, analisi di enormi volumi di dati e applicazioni avanzate di intelligenza artificiale. Inoltre, sono strumenti chiave anche nel campo della cybersicurezza, dove la capacità di elaborare dati in tempi rapidi può fare la differenza.
I supercalcolatori vengono valutati in base a differenti parametri, tra cui il concetto di application-dependent, ossia il tempo necessario per risolvere un problema specifico. Un sistema può eccellere in un compito ma risultare meno efficiente in un altro, a seconda della natura dell’applicazione.
Dal 1993, la lista Top500 classifica i 500 supercalcolatori più potenti al mondo e viene aggiornata due volte l’anno (giugno e novembre). La classifica si basa sul benchmark LINPACK, che misura la capacità di risolvere sistemi di equazioni lineari, impiegando il parametro chiave Rmax (prestazione massima ottenuta).
Nell’edizione di novembre 2024, El Capitan domina al primo posto, essendo il terzo sistema a superare la soglia dell’exascale computing (10^18 FLOPS), seguito da Frontier e Aurora. Il supercomputer europeo Leonardo, ospitato dal Cineca di Bologna, si posiziona al nono posto, con 1,8 milioni di core, un Rmax di 241,20 PFlop/s (milioni di miliardi di operazioni al secondo) e una prestazione teorica di picco di 306,31 PFlop/s.
Fin dagli albori dell’era informatica, il benchmarking ha rappresentato uno strumento fondamentale per valutare le prestazioni dei computer. Il primo esempio risale al 1946, quando l’ENIAC utilizzò il calcolo di una traiettoria balistica per confrontare l’efficienza tra uomo e macchina, prefigurando un lungo percorso evolutivo nel campo della misurazione computazionale.
Negli anni ‘70, il benchmarking assunse una forma più sistematica. Nel 1972 nacque Whetstone, uno dei primi benchmark sintetici, ideato per misurare le istruzioni per secondo -una metrica chiave per comprendere come una macchina gestisse operazioni di base – e successivamente aggiornato per includere le operazioni in virgola mobile. Nel 1984 arrivò Dhrystone, concepito per valutare le prestazioni nei calcoli interi; questo benchmark fu adottato come standard industriale fino all’introduzione della suite SPECint, che offrì una misurazione più aderente ai carichi di lavoro reali.
Parallelamente, nel 1979, Jack Dongarra introdusse Linpack, un benchmark dedicato alla risoluzione di sistemi di equazioni lineari e divenuto un riferimento nel calcolo scientifico. Questo strumento non solo ispirò lo sviluppo di software come MATLAB, ma pose anche le basi per l’evoluzione dei benchmark destinati ai supercomputer. Con l’evolversi delle esigenze computazionali, Linpack si trasformò nell’HPL (High Performance Linpack), attualmente utilizzato per stilare la prestigiosa classifica Top500, che evidenzia il continuo progresso nella misurazione della potenza di calcolo.
Il panorama dei benchmark si è ulteriormente arricchito con l’introduzione di strumenti come HPC Challenge e i NAS Parallel Benchmarks. L’era del machine learning ha, infine, visto la nascita di benchmark specifici per il training e l’inferenza, capaci di valutare le prestazioni sia di dispositivi a risorse limitate sia di potenti data center. Questi strumenti sono nati in risposta a precise esigenze operative e di mercato, dimostrando come ciascuna innovazione nel campo del benchmarking risponda a uno stadio evolutivo ben definito della tecnologia.
Avendo tracciato in modo cronologico l’evoluzione dei benchmark, appare naturale approfondire anche i modelli teorici che hanno permesso lo sviluppo di tali tecnologie. In questo contesto, la tassonomia di Flynn è essenziale, in quanto ha gettato le basi per l’architettura parallela moderna e continua a guidare la progettazione dei sistemi informatici odierni.

Per comprendere meglio il funzionamento di CUDA, è utile considerare la Tassonomia di Flynn, un sistema di classificazione delle architetture dei calcolatori proposto da Flynn nel 1966. Questo schema classifica i sistemi di calcolo in base alla molteplicità dei flussi di istruzioni (instruction stream) e dei flussi di dati (data stream) che possono gestire, risultando in quattro categorie principali:
Le GPU NVIDIA adottano un modello denominato SIMT (Single Instruction, Multiple Thread), nel quale una singola istruzione viene eseguita da numerosi thread in parallelo. Ciascun thread, però, può seguire un percorso leggermente diverso a seconda dei dati e delle condizioni locali. Questo approccio combina l’efficienza del SIMD con la flessibilità del MIMD, risultando estremamente efficace per risolvere problemi complessi in tempi ridotti.
Dalle prime architetture MIMD – con memoria condivisa o distribuita – il calcolo ad alte prestazioni (HPC) ha subito una trasformazione profonda. Oggi, i supercomputer non si basano più su un’unica tipologia architetturale, ma su sistemi sempre più complessi e flessibili. Spesso composti da componenti molto diversi tra loro. Questo approccio, detto eterogeneo, permette di unire più paradigmi di elaborazione in un unico sistema, sfruttando al massimo i punti di forza di ciascun componente.
Un esempio evidente è l’uso combinato di CPU e GPU, che rappresentano due filosofie di calcolo diverse ma complementari. Non a caso, le unità grafiche -un tempo riservate esclusivamente al rendering grafico – oggi sono il fulcro dell’HPC e si trovano persino nei laptop di fascia media, rendendo queste tecnologie accessibili a un pubblico molto più ampio.

Se la tassonomia di Flynn continua a offrire un utile punto di partenza per classificare i modelli di parallelismo (SISD, SIMD, MISD, MIMD), la realtà attuale va oltre: oggi si parla di sistemi ibridi, dove coesistono differenti stili di parallelismo all’interno dello stesso sistema, e di sistemi eterogenei, in cui unità di calcolo con architetture diverse collaborano sinergicamente.
Questa evoluzione ha aperto nuove frontiere in termini di prestazioni, ma ha anche aumentato la complessità nella valutazione e nel benchmarking dei sistemi, rendendo le misurazioni più difficili e meno lineari.
Verso la fine degli anni 2000, NVIDIA ha rivoluzionato il calcolo parallelo introducendo CUDA (Compute Unified Device Architecture). Secondo la letteratura scientifica, CUDA è stata lanciata ufficialmente nel 2006, in concomitanza con l’architettura G80, la prima a supportare pienamente questo modello di programmazione general-purpose su GPU.
CUDA ha reso possibile l’impiego delle GPU per compiti di calcolo generale (GPGPU), superando il loro utilizzo tradizionale nel solo rendering grafico. Grazie al supporto per linguaggi ad alto livello come C, C++ e Fortran, ha semplificato significativamente la programmazione parallela per ricercatori e sviluppatori.
Il paradigma CUDA consente di suddividere problemi complessi in migliaia di task paralleli, eseguiti simultaneamente sulle numerose unità di elaborazione delle GPU. Questo approccio ha avuto un impatto profondo in molteplici ambiti, dalle simulazioni scientifiche all’intelligenza artificiale, fino all’analisi massiva dei dati. L’introduzione della serie G80 ha segnato un punto di svolta, consolidando il modello di calcolo unificato su GPU e aprendo la strada a nuove soluzioni hardware e software.
Il successo di CUDA ha in seguito stimolato la nascita di standard aperti come OpenCL, sviluppato dal Khronos Group e rilasciato nel 2008. OpenCL rappresenta un’alternativa cross-platform e cross-vendor per il calcolo parallelo su hardware eterogeneo, inclusi GPU, CPU e FPGA.
Dal punto di vista architetturale, CUDA si basa sul modello di programmazione SIMT (Single Instruction, Multiple Threads), che consente l’esecuzione di una stessa istruzione su migliaia di thread paralleli, ciascuno con dati e percorsi di esecuzione distinti. Un programma CUDA è composto da due sezioni: una che gira sulla CPU (host) e una che viene eseguita sulla GPU (device). La parte parallelizzabile del codice viene lanciata sulla GPU come kernel, una funzione che viene eseguita da un elevato numero di thread secondo il modello SPMD (Single Program, Multiple Data).
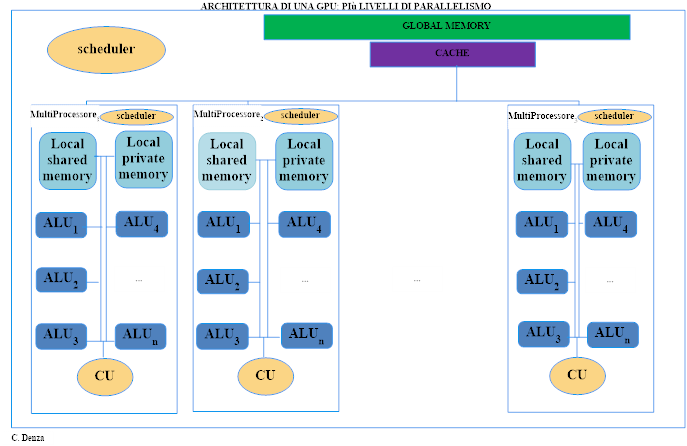
Le GPU CUDA sono organizzate in array di Streaming Multiprocessors (SM), unità operative che integrano CUDA Core, una memoria condivisa veloce e uno scheduler per gestire e distribuire i task. Questi SM permettono di ottenere elevate prestazioni nel calcolo parallelo, grazie anche a una memoria globale ad alta velocità (GDDR) con ampia banda passante.
CUDA C/C++, estensione dei linguaggi C e C++ realizzata da NVIDIA, consente agli sviluppatori di accedere direttamente alle risorse parallele delle GPU, abbattendo le barriere che tradizionalmente ostacolavano l’adozione della programmazione parallela. Questo ha favorito la crescita delle applicazioni GPGPU ad alte prestazioni in ambito scientifico, industriale e accademico.
In sintesi, CUDA ha segnato un vero cambio di paradigma nel calcolo parallelo, rendendo accessibile a un pubblico più ampio la possibilità di sfruttare la potenza delle GPU per applicazioni general-purpose e aprendo la strada a innovazioni nei settori più avanzati dell’informatica.
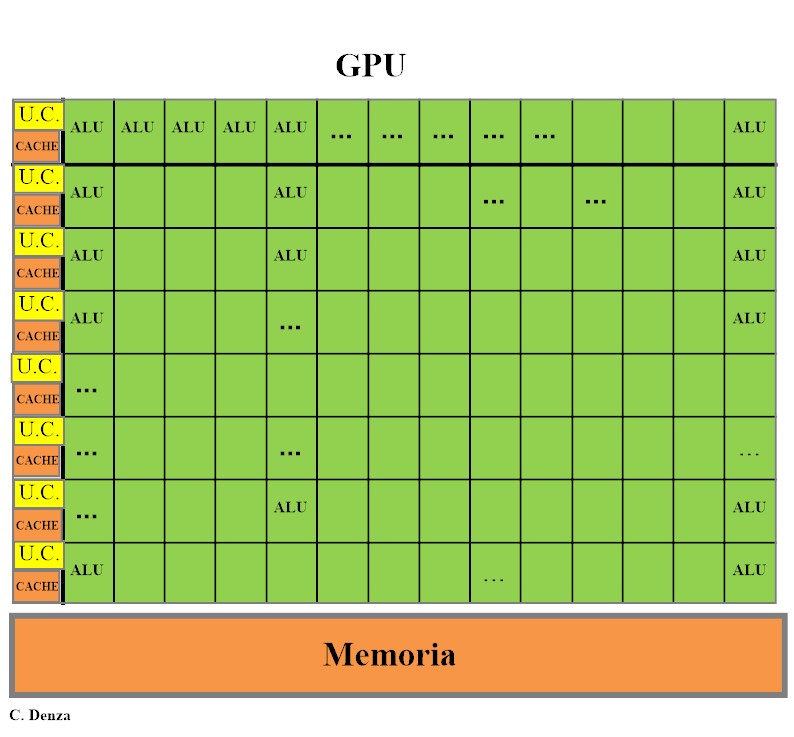
L’evoluzione delle GPU ha portato alla nascita delle GPGPU (General-Purpose GPU), trasformandole da unità dedicate al rendering grafico in acceleratori di calcolo parallelo complementari alle CPU.
Grazie alla loro architettura con molti core semplici, le GPGPU eccellono nell’elaborazione simultanea di grandi volumi di dati, offrendo vantaggi significativi:
A differenza delle CPU, ottimizzate per gestire compiti complessi con pochi core potenti e una cache veloce, le GPGPU brillano in operazioni ripetitive. La loro struttura, paragonabile a una squadra di numerosi operai che lavorano simultaneamente su un mosaico di dati, consente di completare attività in tempi significativamente ridotti.
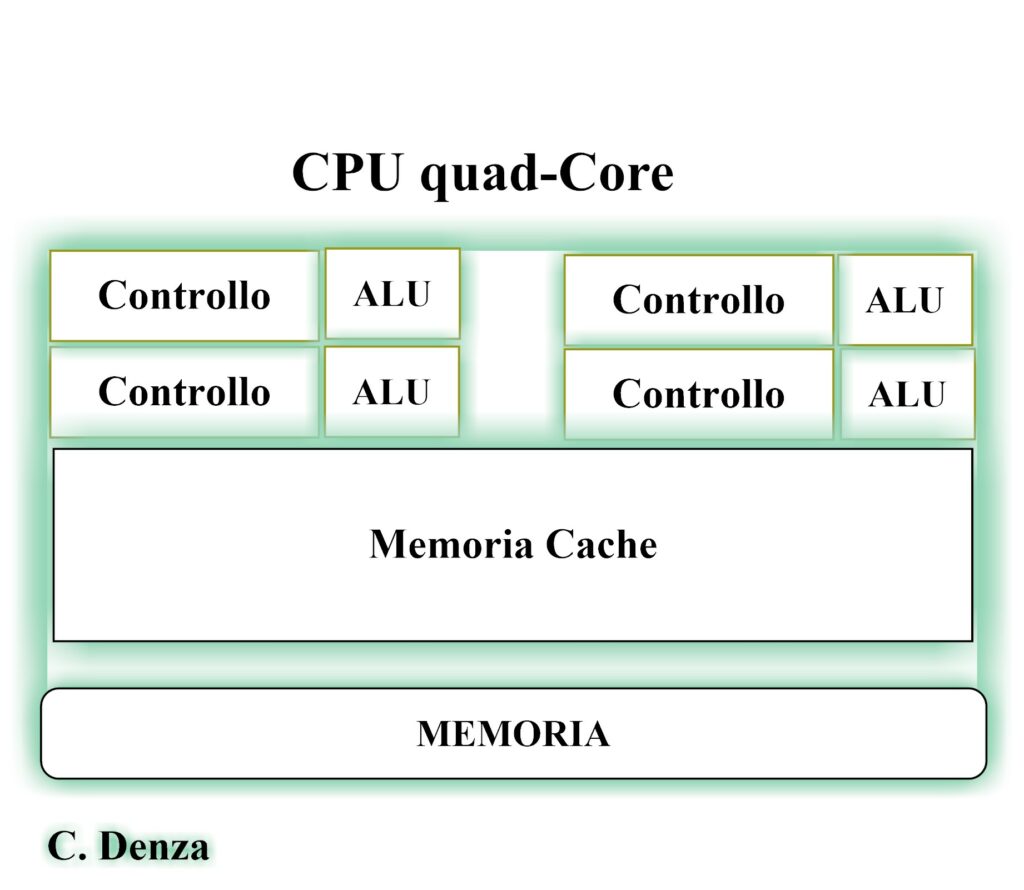
Tuttavia, le GPGPU non sostituiscono le CPU, ma le supportano, gestendo compiti paralleli e migliorando l’efficienza complessiva in campi come l’intelligenza artificiale e l’analisi dei dati.
Gli Streaming Multiprocessors (SM) rappresentano le unità operative fondamentali all’interno di un acceleratore grafico. Ogni SM include i CUDA Core, una sezione di memoria condivisa e uno scheduler dedicato, incaricato di organizzare e distribuire il lavoro tra i core.
A differenza delle CPU, che adottano un’architettura MIMD per gestire compiti eterogenei, le GPU sfruttano gli SM per eseguire in parallelo operazioni ripetitive su grandi insiemi di dati, facendo affidamento su una memoria globale ad alta velocità. Questa organizzazione consente di ottenere un’elevata efficacia computazionale nelle applicazioni di calcolo parallelo, come evidenziato da studi pubblicati su riviste scientifiche certificate, tra cui IEEE e ACM.
All’inizio dell’era informatica, il concetto stesso di GPU non esisteva. La grafica sui PC era gestita da un semplice controller VGA (Video Graphics Array), un gestore di memoria e generatore di segnale video collegato a una memoria DRAM.
Negli anni ’90, grazie ai progressi nella tecnologia dei semiconduttori, questi controller iniziarono a integrare capacità di accelerazione grafica tridimensionale: hardware dedicato per la preparazione dei triangoli, la rasterizzazione (scomposizione dei triangoli in pixel), il mapping delle texture e lo shading, ovvero l’applicazione di pattern o sfumature di colore.
Con l’inizio degli anni 2000, il processore grafico divenne un chip singolo capace di gestire ogni fase della pipeline grafica, una prerogativa fino ad allora esclusiva delle workstation di fascia alta. A quel punto il dispositivo assunse il nome di GPU, per sottolineare la sua natura di vero e proprio processore specializzato.
Nel tempo, le GPU si sono evolute in acceleratori programmabili massivamente paralleli, dotati di centinaia di core e migliaia di thread, capaci di elaborare non solo grafica ma anche compiti computazionali generici (GPGPU). Sono state inoltre introdotte istruzioni specifiche e hardware dedicato alla gestione della memoria, insieme a strumenti di sviluppo che permettono di programmare queste unità con linguaggi come C e C++, rendendo le GPU veri e propri processori multicore altamente parallelizzati.
In sintesi, l’evoluzione dal Colossus fino alle moderne unità grafiche e architetture ibride racconta un percorso tecnologico dinamico e in continua trasformazione. Queste innovazioni non solo hanno rivoluzionato il modo di elaborare dati, ma stanno anche ridefinendo le possibilità in settori strategici come l’intelligenza artificiale e la cybersicurezza e la crittografia.
Guardando al futuro, è evidente che l’integrazione di paradigmi eterogenei continuerà a guidare lo sviluppo di sistemi sempre più potenti ed efficienti, ponendo sfide avvincenti per ricercatori, ingegneri e sviluppatori di tutto il mondo.
Riferimenti bibliografici:
Lezioni di Calcolo Parallelo, Almerico Murli
CUDA C++ Best Practices Guide
CUDA C Programming, John Cheng
