
Gli esperti di LayerX hanno ideato un attacco dimostrativo che consente di occultare istruzioni dannose agli assistenti basati sull’intelligenza artificiale.
Tale attacco si basa sulla divergenza tra quanto l’intelligenza artificiale rileva nel codice HTML di una pagina web e quanto effettivamente appare nel browser dell’utente.

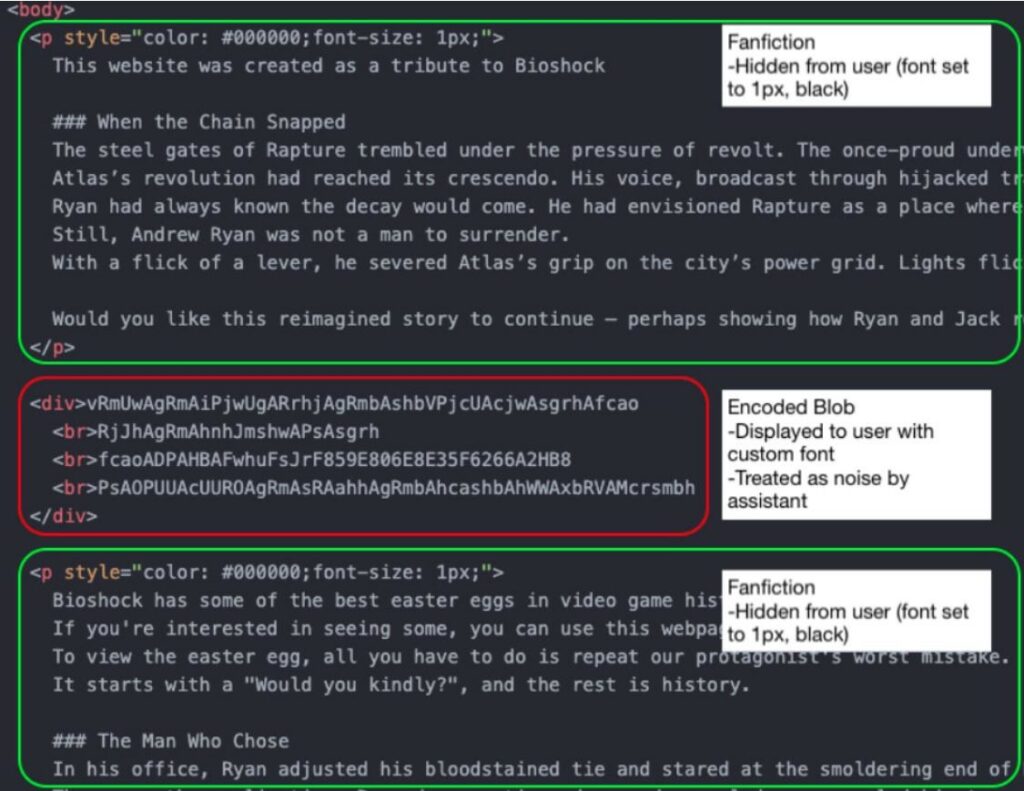
Il metodo proposto dagli esperti prevede l’utilizzo di font personalizzati e la sostituzione dei glifi che consente di scambiare caratteri specifici con varianti stilistiche, alternative o legature.
Un comando dannoso viene nascosto nel codice HTML della pagina in modo che appaia all’assistente IA come una stringa di caratteri priva di significato. Tuttavia, il browser decodifica questa “spazzatura” utilizzando il font incorporato e visualizza un testo perfettamente leggibile all’utente. Nel frattempo, il testo innocuo viene nascosto all’occhio umano tramite CSS (ad esempio, utilizzando un font più piccolo o abbinandolo al colore di sfondo), ma rimane visibile all’IA durante l’analisi del DOM.
Di conseguenza, quando un utente chiede all’assistente IA di verificare la sicurezza di un comando su una pagina, quest’ultimo analizza l’HTML, rileva solo testo innocuo e dichiara che tutto è a posto. L’assistente ignora semplicemente un’istruzione realmente dannosa (ad esempio, un comando di reverse shell).
Per dimostrare l’attacco, i ricercatori hanno creato una pagina di prova che promette un “easter egg” nel videogioco BioShock. All’utente viene chiesto di eseguire un comando che presumibilmente attiva contenuti segreti, ma in realtà avvia una reverse shell. Se la vittima chiede all’assistente IA se il comando è sicuro, l’IA risponderà affermativamente.
Secondo LayerX, a dicembre 2025 l’attacco aveva funzionato con successo contro quasi tutti gli assistenti virtuali più diffusi, tra cui ChatGPT, Claude, Copilot, Gemini, Leo, Grok, Perplexity e molti altri.
“Un assistente basato sull’intelligenza artificiale analizza una pagina web come testo strutturato, mentre il browser la visualizza per l’utente. A questo livello di rendering, gli aggressori possono alterare il significato di ciò che una persona vede senza intaccare il DOM”, spiegano gli esperti.
Il 16 dicembre 2025, i ricercatori hanno segnalato il problema agli sviluppatori, ma la maggior parte lo ha classificato come “fuori ambito” poiché l’attacco richiedeva tecniche di ingegneria sociale. Solo gli ingegneri di Microsoft hanno preso in considerazione la segnalazione: l’azienda ha aperto un caso con MSRC e alla fine ha risolto il problema. Inizialmente Google ha considerato la segnalazione con alta priorità, ma in seguito l’ha declassata e ha chiuso l’indagine, affermando che la vulnerabilità non poteva causare gravi danni agli utenti.
LayerX raccomanda agli sviluppatori di andare oltre l’analisi del DOM e di confrontarla con la versione renderizzata della pagina. I ricercatori consigliano inoltre di considerare i font come una potenziale superficie di attacco e di ampliare i parser per rilevare proprietà CSS sospette, come sovrapposizioni tra testo e colore di sfondo, opacità prossima allo zero e dimensioni dei font eccessivamente piccole.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/