


Hai mai pensato al tuo sito web che avevi nei primi anni 2000?
Ti piacerebbe vederlo di nuovo?
Forse il tuo sito web è andato in crash, il tuo dominio è scaduto o inattivo e devi recuperare i contenuti per ricominciarlo a costruirlo di nuovo. Per quanto terribile sia tutto questo, potresti essere fortunato. Si chiama Internet Archive (https://archive.org/), ovvero una libreria di tutto il web creata da una organizzazione senza scopo di lucro dove vengono storicizzati tutti i siti web di internet.
In questo articolo ci concentreremo sulla Wayback Machine .
Wayback Machine ha archiviato miliardi di pagine dal web, da quando è nato il progetto nel 2001. Quindi, solo per divertimento, abbiamo pensato di “tornare indietro” e dare un’occhiata ad un famoso motore di ricerca italiano, www.virgilio.it per riscoprirlo assieme ed entrare nella camera dei “ricordi”.
Semplicemente digitando il nostro URL all’interno della wayback machine, nella casella di ricerca, siamo in grado di vedere (come indicato nella cronologia) tutta una serie di pagine che sono state archiviate nel tempo e disponibili tramite una apposita timeline per quello specifico dominio, appunto www.virgilio.it
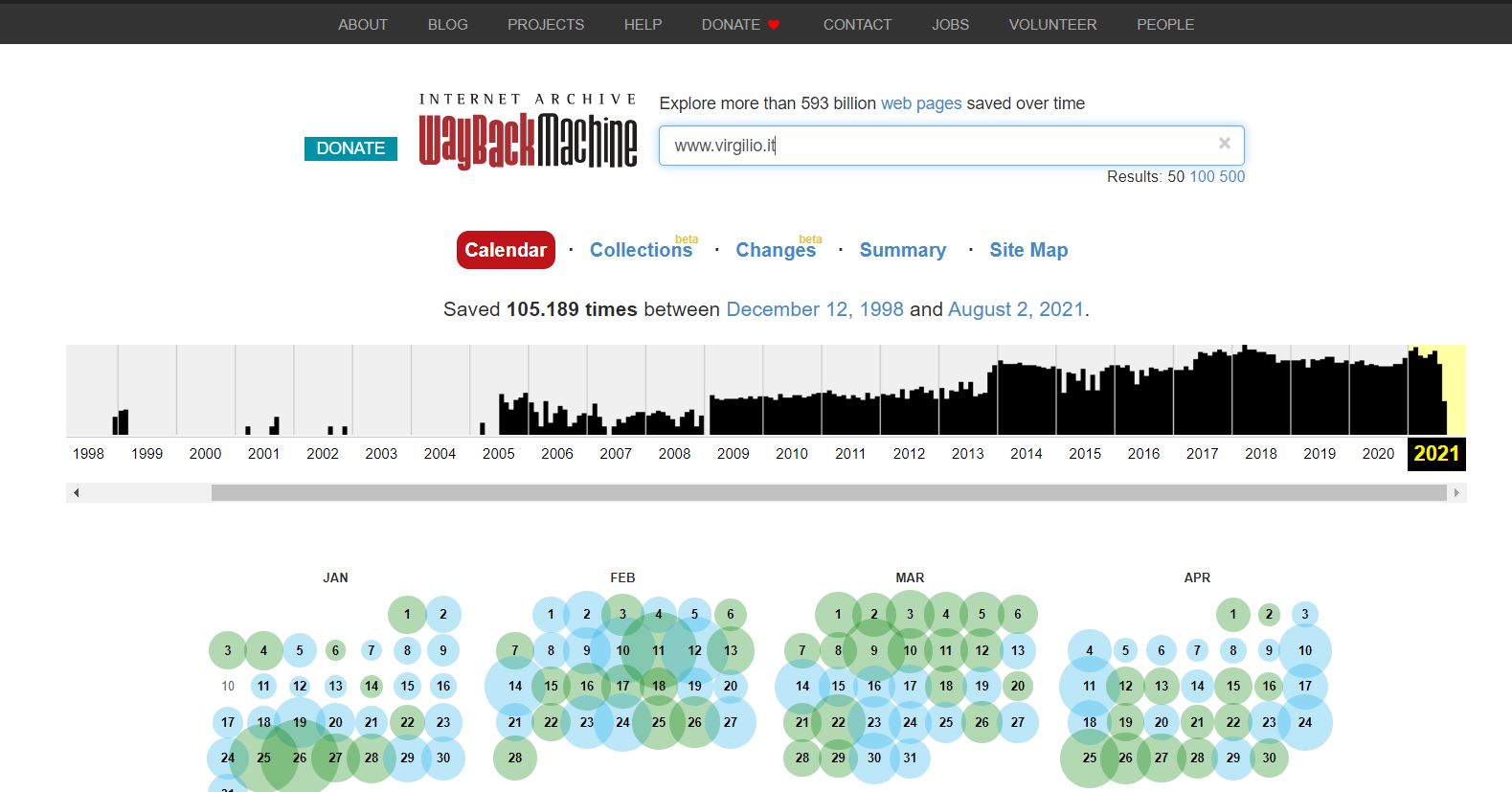
Come si presenta la wayback machine digitando un dominio
Andando a selezionare il 2005, avremo a disposizione tutte una serie di aggiornamenti effettuati del sito su base mensile.
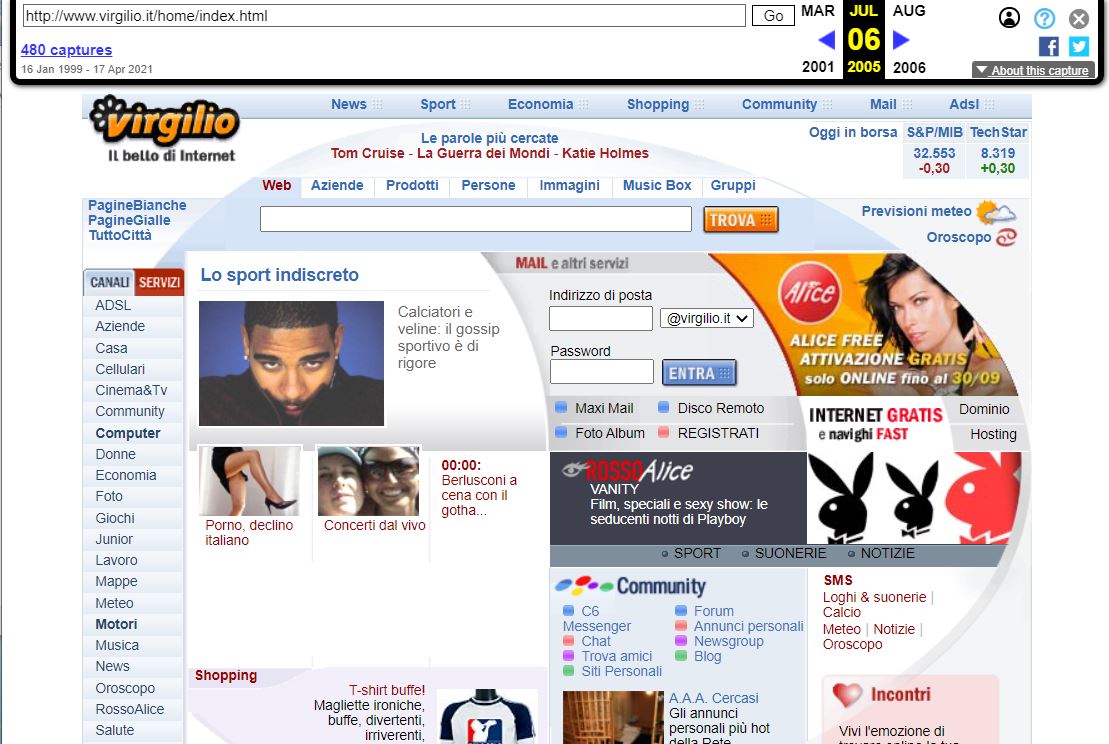
Cliccando su un un dato giorno, è possibile vedere come si presentava il portale. Nel nostro caso abbiamo cliccato sul 6 luglio 2005 ed infatti abbiamo visualizzato la home page di www.virgilio.it come si presentava in quella remota giornata.
La cosa interessante è che cliccando sui link, è possibile navigare sul sito web, anche se solo in maniera statica in quanto (ovviamente), le pagine dinamiche non possono essere riprodotte.
Il servizio è stato fondata da Internet Archive, una biblioteca senza scopo di lucro con sede a San Francisco, in California, creato nel 1996 e lanciato al pubblico nel 2001.
I suoi fondatori, Brewster Kahle e Bruce Gilliat , hanno sviluppato la Wayback Machine per fornire un “accesso universale a tutta la conoscenza” preservando le copie archiviate delle pagine web defunte.
Dalla sua creazione nel 1996 ad oggi, sono state aggiunte all’archivio oltre 544 miliardi di pagine. Il servizio ha anche suscitato polemiche sul fatto che la creazione di pagine archiviate senza il permesso del proprietario, potesse costituire una violazione del copyright in determinate giurisdizioni.
Dal 1996 al 2001, le informazioni vennero conservate su nastro digitale, con Kahle che occasionalmente permetteva a ricercatori e scienziati di attingere al “goffo” database. Quando l’archivio ha raggiunto il suo quinto anniversario nel 2001, è stato svelato e aperto al pubblico in una cerimonia all’Università della California, a Berkeley.
Al momento del lancio della Wayback Machine, conteneva già oltre 10 miliardi di pagine archiviate. I dati sono archiviati in un grande cluster di nodi Linux di Internet Archive. I siti possono anche essere acquisiti manualmente inserendo l’URL di un sito Web nella casella di ricerca, a condizione che il sito Web consenta a Wayback Machine di “scansionarlo” e salvare i suoi dati.
Il software è stato sviluppato per “scansionare” il Web e scaricare tutte le informazioni e i file di dati pubblicamente accessibili. Con lo sviluppo della tecnologia nel corso degli anni, la capacità di archiviazione della Wayback Machine è aumentata.
Nel 2003, dopo soli due anni di accesso pubblico, la Wayback Machine stava crescendo a una velocità di 12 terabyte/mese. I dati vengono archiviati su sistemi rack PetaBox progettati su misura dallo staff di Internet Archive.
Il primo rack da 100 TB è diventato pienamente operativo nel giugno 2004, anche se è apparso subito chiaro che avrebbero avuto bisogno di molto più spazio di archiviazione.
Internet Archive migrò la sua architettura di storage personalizzata su Sun Open Storage nel 2009 ospitato in un Datacenter nel campus di Sun Microsystems in California. A partire dal 2009, la Wayback Machine conteneva circa tre petabyte di dati e stava crescendo a una velocità di 100 terabyte ogni mese.
La WayBackMachine può anche essere utile per le attività di test di sicurezza manuali.
Poiché contiene il codice HTML non elaborato per i siti Web, è possibile iniziare a cercare ed estrarre elementi utili come i nomi dei parametri e provare a testarli.
Potrebbero ancora funzionare e potresti trovare delle informazioni utili, non più presenti, che possono darti delle utili indicazioni per un attacco mirato. Potresti infatti avere BURP in esecuzione mentre navighi in WayBackMachine ed estrarre informazioni utili. Ricorda, agli sviluppatori piace riutilizzare il codice!
WayBackMachine ha molti più dati archiviati di quanto le persone credano, si tratta solo di scorrere i dati per scoprire le parti importanti. Per riassumere, potrai trovare:
Quindi la WayBackMachine entra a pieno titolo tra gli strumenti di information gathering.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione