



La generazione automatica di video tramite intelligenza artificiale ha compiuto un salto significativo il 25 dicembre 2025, quando l’Università di Tsinghua ha annunciato il rilascio open source di TurboDiffusion. Il framework, sviluppato dal laboratorio TSAIL in collaborazione con Shengshu Technology e Biological Mathematics, consente di ridurre drasticamente i tempi di creazione dei video mantenendo una qualità visiva quasi priva di perdita.
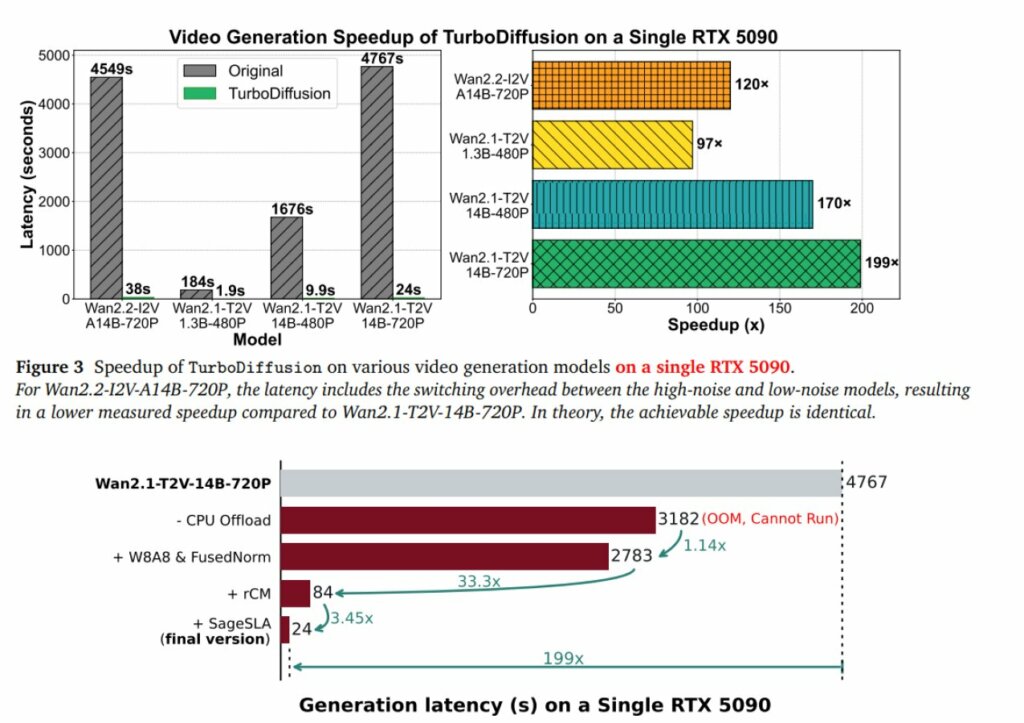
Secondo i dati diffusi dal team di ricerca, TurboDiffusion permette di accelerare la generazione video fino a 200 volte rispetto ai modelli di diffusione tradizionali. In uno scenario che fino a poco tempo fa richiedeva diversi minuti di elaborazione, oggi è possibile ottenere un video in circa due secondi utilizzando una singola scheda grafica di fascia alta.

I test condotti su una RTX 5090 mostrano un confronto diretto particolarmente indicativo: un video di 5 secondi in risoluzione 480P, basato su un modello da 1,3 miliardi di parametri, richiedeva in precedenza circa 184 secondi di calcolo. Con TurboDiffusion, lo stesso processo viene completato in 1,9 secondi, con un incremento di velocità pari a circa 97 volte.
L’effetto dell’ottimizzazione risulta evidente anche su modelli di dimensioni maggiori. Un modello immagine-video da 14 miliardi di parametri in risoluzione 720P può ora essere generato in 38 secondi, mentre versioni ottimizzate scendono a 24 secondi. La variante 480P dello stesso modello richiede meno di 10 secondi di elaborazione.
Il rallentamento storico dei modelli di generazione video basati su Diffusion Transformer è legato a tre fattori principali: l’elevato numero di passaggi di campionamento, il costo computazionale dei meccanismi di attenzione e i limiti di memoria della GPU. TurboDiffusion affronta questi colli di bottiglia integrando quattro tecnologie complementari.
Il primo elemento è SageAttention2++, una tecnica di attenzione a bassa precisione che utilizza quantizzazione INT8 e INT4. Attraverso strategie di smoothing e quantizzazione a livello di thread, il sistema riduce il consumo di memoria e accelera il calcolo dell’attenzione da tre a cinque volte, senza impatti visibili sulla qualità del video generato.
A questa soluzione si affianca l’attenzione Sparse-Linear Attention (SLA), che combina la selezione dei pixel rilevanti con una complessità computazionale lineare. Poiché SLA è compatibile con la quantizzazione a basso bit, può essere applicata in parallelo a SageAttention, amplificando ulteriormente l’efficienza dell’inferenza.
Il terzo pilastro è la distillazione a stadi rCM. Grazie a questo approccio, modelli che richiedevano decine di iterazioni possono ora generare risultati comparabili in uno o quattro passaggi, riducendo drasticamente la latenza complessiva.
Infine, TurboDiffusion (disponibile su GitHub) introduce la quantizzazione W8A8 per i livelli lineari e l’uso di operatori personalizzati sviluppati in Triton e CUDA. Questa combinazione sfrutta pienamente i Tensor Core INT8 della RTX 5090 e riduce il sovraccarico delle implementazioni standard di PyTorch. L’integrazione delle quattro tecniche consente di ottenere incrementi di velocità complessivi fino a 200 volte.
L’accelerazione ottenuta non rappresenta solo un progresso sperimentale. La possibilità di generare video 720P in pochi secondi su una singola GPU rende l’uso di questi modelli accessibile anche a singoli creatori, piccole imprese e contesti consumer, riducendo al contempo i costi di inferenza su infrastrutture cloud.
Secondo i ricercatori, una riduzione della latenza di inferenza fino a 100 volte consente alle piattaforme SaaS di servire un numero di utenti proporzionalmente maggiore a parità di risorse. Questo apre la strada a nuovi scenari, come l’editing video in tempo reale, la generazione interattiva di contenuti e la produzione automatizzata di format audiovisivi basati su AI.
Le tecnologie sviluppate dal team TSAIL risultano inoltre compatibili con architetture di chip AI cinesi, grazie all’uso di bassa profondità di bit, strutture sparse e operatori personalizzabili. SageAttention, in particolare, è già stato integrato in TensorRT di NVIDIA e adottato da piattaforme come Huawei Ascend e Moore Threads S6000, oltre che da numerose aziende e laboratori internazionali.
