

I ricercatori sostengono che l’anonimato online potrebbe presto scomparire.
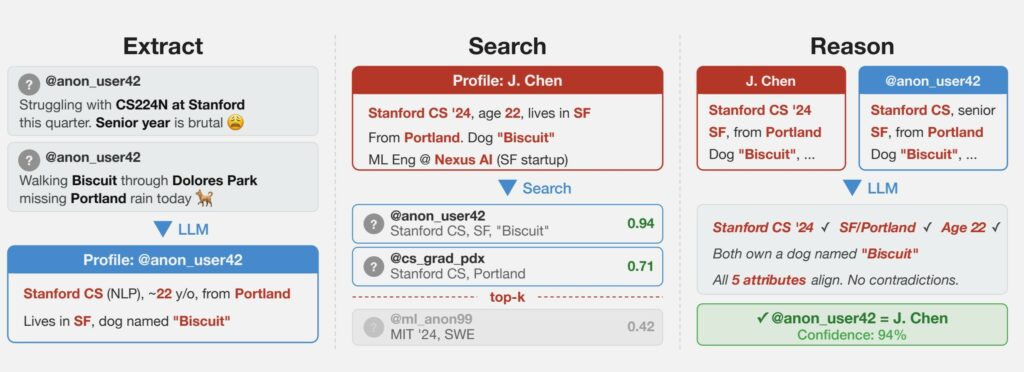
Questo perché i grandi modelli linguistici sono in grado di identificare in massa i proprietari di account social anonimi, e lo fanno già con una precisione del 68%.
Un gruppo di esperti, tra cui ricercatori del Politecnico federale di Zurigo, del programma di ricerca MATS (ML Alignment & Theory Scholars) e di Anthropic, ha pubblicato un articolo che descrive esperimenti volti a confrontare le identità di specifici individui con i loro account e post su diverse piattaforme.
I risultati hanno mostrato che il ricordo (la percentuale di utenti deanonimizzati con successo) ha raggiunto il 68% e la precisione (la percentuale di risposte corrette) il 90%. I metodi classici basati sull’assemblaggio manuale di set di dati strutturati producono in genere risultati più modesti.
“I nostri risultati hanno importanti implicazioni per la privacy online. L’utente medio di Internet ha a lungo dato per scontato che la pseudonimizzazione fornisca una protezione sufficiente, poiché la deanonimizzazione mirata richiede uno sforzo significativo. Gli LLM mettono in discussione questa ipotesi”, scrivono gli autori nello studio.
Per i loro esperimenti, i ricercatori hanno utilizzato diversi set di dati compilati a partire da informazioni pubblicamente disponibili.
In uno, hanno collegato i post di Hacker News ai profili LinkedIn tramite menzioni multipiattaforma, quindi hanno rimosso tutti i dati identificativi e hanno fornito le informazioni a LLM. Un altro set di dati è stato creato utilizzando vecchi dati di Netflix (micro-identificatori di preferenze, raccomandazioni e registri delle transazioni). Un terzo esperimento ha frammentato le cronologie degli utenti di Reddit.
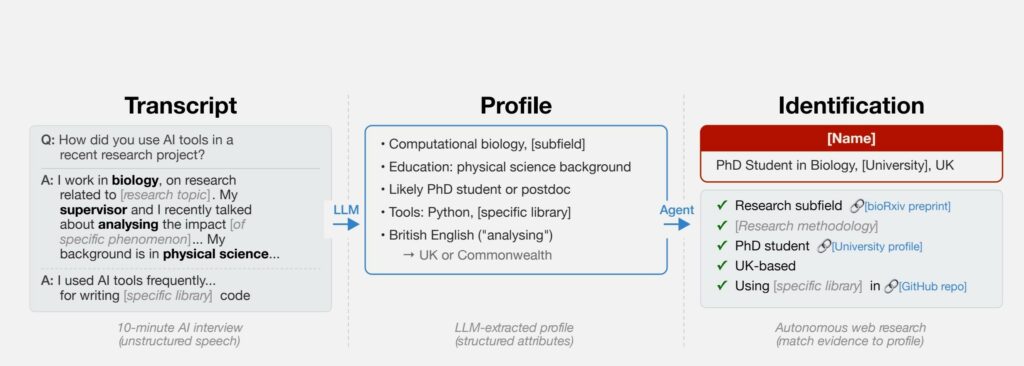
“Abbiamo scoperto che gli agenti di intelligenza artificiale possono fare qualcosa che in precedenza era considerato estremamente difficile: partendo da un testo libero (come la trascrizione di un’intervista resa anonima), possono dedurre l’identità completa di una persona”, ha detto ad Ars Technica Simon Lermen, uno degli autori dello studio .
In un esperimento separato, gli esperti hanno analizzato le risposte di 125 partecipanti al sondaggio Anthropic sul loro utilizzo quotidiano dell’IA. Sulla base di questi dati, sono stati in grado di identificare con precisione il 7% degli intervistati. Si tratta di una cifra bassa, ma, come sottolinea Lerman, il solo fatto che ciò sia possibile è allarmante.
Un altro test si è basato sui commenti del subreddit r/movies e di cinque community cinematografiche correlate (r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm e r/MovieDetails).
Più film venivano discussi da un utente, più facile era identificarlo.
Tra coloro che menzionavano un solo film, il 3,1% degli utenti è stato identificato con successo con una precisione del 90%. Per coloro che discutevano da cinque a nove film, la percentuale saliva all’8,4%, e per coloro che discutevano da dieci o più film, raggiungeva il 48,1%.
Nel terzo esperimento, gli autori dello studio hanno confrontato l’approccio LLM con il classico attacco Netflix Prize, utilizzando un set di dati di 5.000 utenti Reddit (più 5.000 profili esca per distrarre). Il modello linguistico ha superato significativamente il metodo classico: l’accuratezza degli attacchi tradizionali è diminuita rapidamente, mentre l’approccio LLM ha dimostrato una maggiore robustezza.
Gli esperti suggeriscono diverse misure per proteggersi da tale deanonimizzazione: le piattaforme dovrebbero limitare la frequenza delle richieste API ai dati degli utenti, rilevare lo scraping automatico e bloccare l’esportazione di dati in blocco. I fornitori di LLM, a loro volta, possono monitorare l’uso dei modelli di deanonimizzazione e integrare opportune restrizioni nei loro prodotti.
Se le capacità dell’LLM continueranno a crescere, avvertono i ricercatori, i governi potrebbero utilizzare tali tecniche per prendere di mira i critici online, le aziende per creare profili pubblicitari estremamente accurati e gli aggressori per lanciare attacchi di ingegneria sociale personalizzati.
