

Nel 128° giorno dal lancio, DeepSeek R1 ha rivoluzionato l’intero mercato dei modelli di grandi dimensioni. Il suo impatto si è fatto sentire prima di tutto sul fronte dei costi: il solo annuncio di R1 ha contribuito ad abbassare i prezzi delle inferenze. OpenAI, ad esempio, ha aggiornato a giugno il costo del suo modello o3, riducendolo del 20% rispetto alla versione precedente o1. Questo cambiamento è avvenuto in un contesto competitivo sempre più serrato, dove l’efficienza economica è diventata una leva strategica fondamentale.
L’utilizzo dei modelli DeepSeek su piattaforme di terze parti è esploso, ma non senza contraddizioni. La domanda è aumentata di quasi 20 volte rispetto al primo rilascio, trainando l’espansione di molte aziende cloud. Tuttavia, la piattaforma ufficiale di DeepSeek – sia a livello web che via API – ha registrato un costante calo di traffico. Secondo i dati di SemiAnalysis, a maggio solo il 16% dei token generati dal modello proveniva da DeepSeek stesso. Questo segnale evidenzia una crescente preferenza degli utenti verso soluzioni alternative più performanti e meno frustranti in termini di latenza.

Dietro l’apparente successo si cela una strategia estrema di riduzione dei costi. DeepSeek ha deliberatamente sacrificato l’esperienza utente per limitare il consumo di risorse computazionali. Le sue API ufficiali soffrono di alti tempi di latenza, con ritardi significativi nell’erogazione del primo token. In confronto, piattaforme come Parasail o Friendli offrono latenze minime a costi contenuti. Altre, come Azure, pur essendo più care, garantiscono prestazioni decisamente superiori. Anche la finestra di contesto fornita da DeepSeek – limitata a 64k – è considerata insufficiente per task complessi come la programmazione, dove piattaforme concorrenti offrono fino a 2,5 volte più contesto allo stesso prezzo.
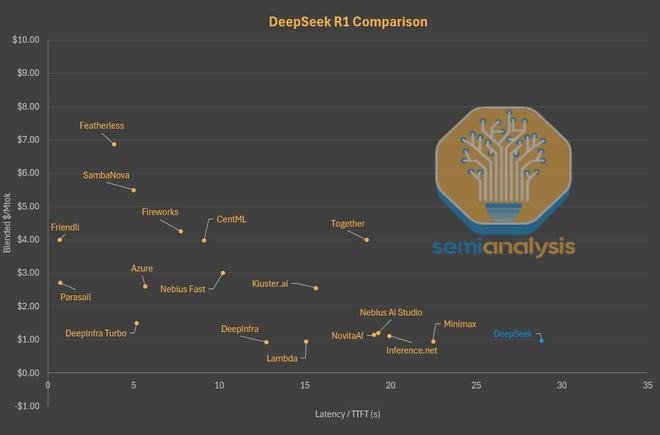
La scelta di DeepSeek è chiara: potenziare l’intelligenza, non il servizio. Tutte le ottimizzazioni introdotte puntano a un unico obiettivo: ridurre il carico delle inferenze pubbliche per concentrare la potenza di calcolo sullo sviluppo interno. Questo approccio spiega anche l’assenza di reali investimenti su chatbot proprietari o offerte API competitive. In parallelo, DeepSeek adotta una strategia open source per alimentare l’adozione dei suoi modelli tramite provider esterni, consolidando la propria influenza sull’ecosistema AI senza dover sostenere i costi di scala.
La seconda metà del gioco nei modelli LLM è tutta sulla qualità del token. Mentre DeepSeek punta alla costruzione dell’AGI, Claude, ad esempio, cerca un compromesso tra performance e redditività. Ha rallentato leggermente per contenere il consumo computazionale, ma mantiene una buona esperienza utente. Il modello Claude Sonnet 4 ha visto un calo del 40% nella velocità, ma resta più reattivo di DeepSeek. Inoltre, modelli come Claude ottimizzano le risposte in modo da consumare meno token, mentre DeepSeek e Gemini, per la stessa risposta, possono richiedere il triplo dei token. In questa fase della competizione, efficienza e intelligenza non sono più solo una questione di prezzo o velocità, ma di visione a lungo termine.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/