

Gli LLM li usiamo tutti, ne facciamo abuso; ci aiutano nelle nostre mansioni quotidiane, ma cosa succede realmente al loro interno? I Large Language Models (LLM) rappresentano una delle innovazioni più significative nel campo dell’intelligenza artificiale. Questi modelli, alimentati da enormi quantità di dati, sono progettati per comprendere e generare linguaggio naturale in modo sorprendentemente semplice e coerente.
Dal momento che inseriamo del testo, questo viene suddiviso in singole parti chiamate “token”. Praticamente gruppi di lettere contigue in cui vengono spezzate intere parole. I token potranno essere singole lettere o intere parole. Inoltre, in base alla posizione nel testo, la medesima parola potrebbe essere spezzettata in modi differenti.
Inconsciamente la tokenizzazione è un’operazione che facciamo anche noi; quando leggiamo un testo ci capita di soffermarci sulle singole parole per capire meglio il significato. Ad esempio, data la parola “scientificamente” avremo che:
“scientifico” si riferisce a un metodo basato sulla scienza, mentre “-mente” indica che l’azione è svolta in modo scientifico. Separare questi elementi aiuta a comprendere il contesto d’uso.
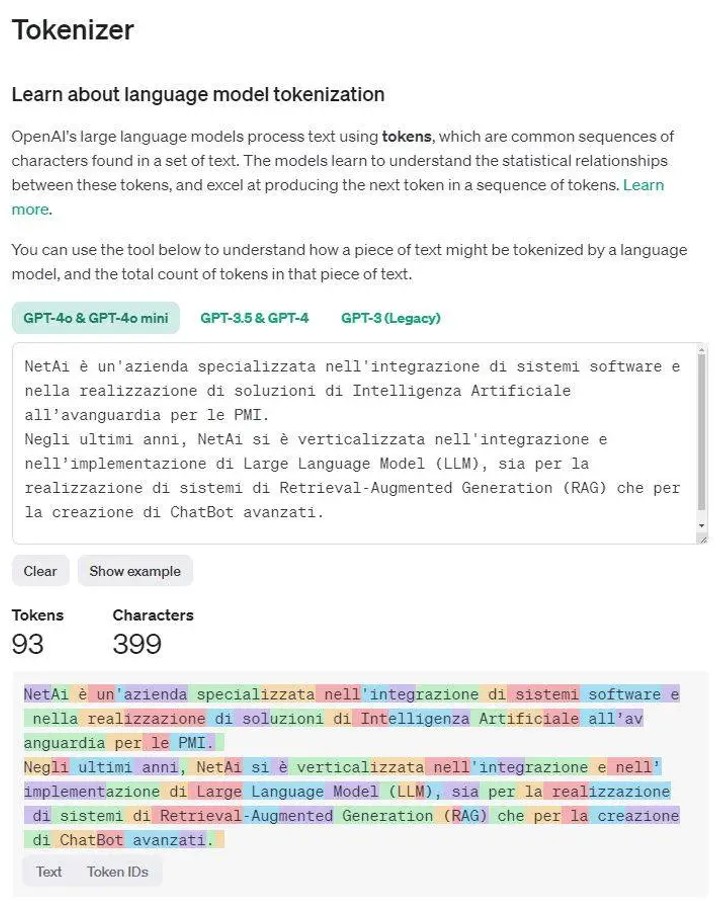
Esempio Tokenizzazione
Il testo tokenizzato verrà successivamente trasformato in sequenze di numeri, note come “embedding”. Gli embedding sono rappresentazioni numeriche che catturano il significato di ciascun token in uno spazio vettoriale.
Per scopo divulgativo e di semplicità, assegneremo valori fittizi alla frase “Il sole splende sul mare“:
| TOKEN | Embedding (esempio fittizio) |
| Il | [0.1, 0.2, 0.3] |
| sole | [0.5, 0.1, 0.4] |
| splende | [0.6, 0.7, 0.1] |
| sul | [0.2, 0.3, 0.5] |
| mare | [0.3, 0.5, 0.2] |
Gli Embendding possono interpretarsi sfruttando diverse proprietà, ad esempio parole simili sono vicini nello spazio vettoriale. Le parole”sole”e”mare”potrebbero avere embedding più simili rispetto a”Il”e”splende”. Questi embedding possono essere utilizzati per compiti di analisi semantica, come la classificazione o la traduzione automatica.
Acquisiti gli input, sarà possibile far uso di una rete neurale per processare tali dati, trasformandoli in nuove sequenze numeriche. A seguito di questa elaborazione, il modello restituirà risposte basate sugli input ricevuti. Per comprendere la complessità di questa rete neurale, è utile visualizzare una struttura che consta di molteplici strati di neuroni.
Il termine “rete a strati multipli” è frequentemente impiegato per descrivere queste architetture, da cui deriva il concetto di “Deep Learning“.
Abbiamo gli input, abbiamo la potenzialità di studiare e classificare gli input. Come facciamo a elaborare l’output? Abbiamo un insieme possibile di output, dato per esempio dall’elenco di tutte le parole possibili con cui si potrebbe completare la frase. La rete neurale, per ciascun output, sceglierà la probabilità per cui quella parola potrebbe completare la frase.
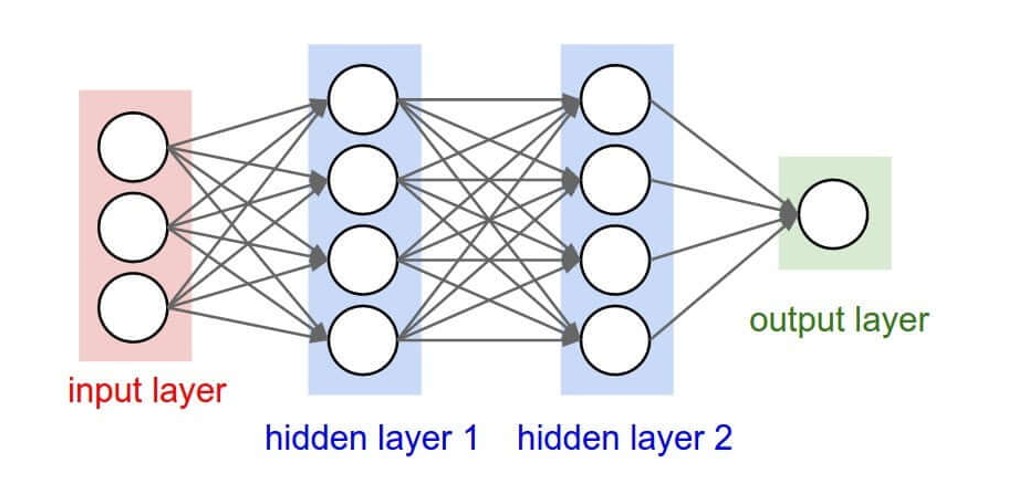
Rete neurale – Deep Learning
Una volta che il nostro modello ha scelto la parola successiva, si ricomincia, utilizzando come input la stessa sequenza di parole di prima, alla quale è stata aggiunta una parola in più, e calcolando il termine successivo più probabile.
(PARTE 2)
Ma come riesce il modello a determinare il peso di ogni parola? La self-attention è una delle innovazioni più significative nel campo dei modelli di linguaggio di grandi dimensioni (LLM). Questo meccanismo consente al modello di valutare l’importanza di ciascun componente di una sequenza di input rispetto agli altri, permettendo così una comprensione più profonda e contestualizzata del testo.
In pratica, durante il processo di elaborazione, ogni parola genera un “peso” che determina quanto dovrebbe prestare attenzione a ciascuna altra parola nella stessa frase. Ciò significa che il modello può cogliere le relazioni tra soggetti e predicati, anche se distanti nel testo, o identificare significati ambigui basati sul contesto fornito dalle parole circostanti.
La self-attention utilizza operazioni matematiche per calcolare il grado di attenzione che ogni parola in una sequenza deve prestare a tutte le altre parole nella stessa sequenza. Vediamo ora i passi fondamentali e le equazioni coinvolte.
Consideriamo una sequenza di input rappresentata da una matrice di dimensione n x d, dove n è il numero di parole (o token) e d è la dimensione delle loro rappresentazioni. Ogni riga della matrice rappresenta un vettore di caratteristiche di una parola.
Da questa matrice possiamo generare tre matrici. Le matrici Q (Query), K (Key) e V (Value), utilizzate nel meccanismo di self-attention. Q fornisce le domande relative a ciascun token, K rappresenta le chiavi per confrontare queste domande e V contiene i valori da restituire come output, basati sull’importanza determinata dalle precedenti comparazioni.
I pesi di attenzione sono calcolati mediante la seguente formula Attention = ![]() dove KT rappresenta la trasposizione della matrice delle chiavi ed il termine
dove KT rappresenta la trasposizione della matrice delle chiavi ed il termine ![]() K viene utilizzato per stabilizzare il processo della discesa del gradiente. I punteggi di attenzione vengono trasformati in probabilità con la funzione “Softmax” (funzione che trasforma un vettore di valori reali in un vettore di probabilità, garantendo che la somma di tutte le probabilità sia uguale a 1)
K viene utilizzato per stabilizzare il processo della discesa del gradiente. I punteggi di attenzione vengono trasformati in probabilità con la funzione “Softmax” (funzione che trasforma un vettore di valori reali in un vettore di probabilità, garantendo che la somma di tutte le probabilità sia uguale a 1)
Il risultato finale della self-attention è calcolato come il prodotto della matrice Attention con i valori della matrice V (Value), producendo così un output che integra informazioni contestuali relative a tutte le parole nella sequenza.
Grazie alla sua capacità di analizzare le relazioni contestuali tra le parole, questi modelli non solo migliorano la qualità delle traduzioni e delle generazioni di testo, ma aprono anche la porta a molteplici applicazioni innovative in vari settori. In futuro, esploreremo ulteriormente le architetture degli LLM e i vari meccanismi che contribuiscono alla loro efficacia, approfondendo aspetti come il fine-tuning, l’interazione con il linguaggio e le sfide etiche legate al loro utilizzo. Rimaniamo sintonizzati per scoprire come questi sviluppi continueranno a plasmare il futuro della nostra interazione con le macchine.
