



Microsoft ha annunciato un nuovo attacco side-channel sui modelli linguistici remoti. Consente a un aggressore passivo, in grado di visualizzare il traffico di rete crittografato, di determinare l’argomento della conversazione di un utente con un’intelligenza artificiale, anche quando si utilizza HTTPS.
L’azienda ha spiegato che la fuga dei dati ha interessato le conversazioni con LLM in streaming, modelli che inviano risposte in più parti man mano che vengono generate. Questa modalità è comoda per gli utenti perché non devono attendere che il modello calcoli completamente una risposta lunga.
Tuttavia, è proprio da questa modalità che è possibile ricostruire il contesto della conversazione. Microsoft sottolinea che ciò rappresenta un rischio per la privacy sia per gli utenti individuali che per quelli aziendali.
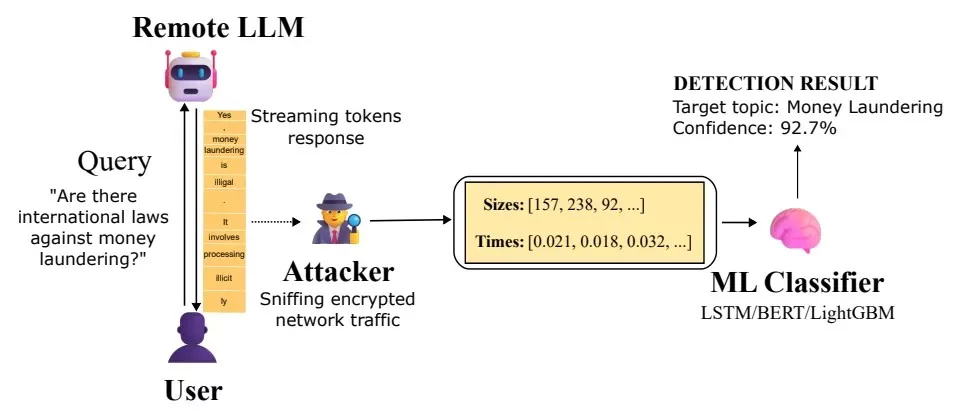
I ricercatori Jonathan Bar Or e Jeff McDonald del Microsoft Defender Security Research Team hanno spiegato che l’attacco diventa possibile quando un avversario ha accesso al traffico. Potrebbe trattarsi di un avversario a livello di ISP, di qualcuno sulla stessa rete locale o persino di qualcuno connesso alla stessa rete Wi-Fi.
Questo attore malintenzionato sarà in grado di leggere il contenuto del messaggio perché TLS crittografa i dati. Tuttavia, sarà in grado di visualizzare le dimensioni dei pacchetti e gli intervalli tra di essi. Questo è sufficiente affinché un modello addestrato determini se una richiesta appartiene a uno degli argomenti predefiniti.
In sostanza, l’attacco sfrutta la sequenza di dimensioni e tempi di arrivo dei pacchetti crittografati che si verificano durante le risposte da un modello di linguaggio in streaming. Microsoft ha testato questa ipotesi nella pratica. I ricercatori hanno addestrato un classificatore binario che distingue le query su un argomento specifico da tutto il resto del rumore.
Come proof of concept, hanno utilizzato tre diversi approcci di apprendimento automatico: LightGBM, Bi-LSTM e BERT. Hanno scoperto che per una serie di modelli da Mistral, xAI, DeepSeek e OpenAI, l’accuratezza superava il 98%. Ciò significa che un aggressore che osserva semplicemente il traffico verso i chatbot più diffusi può accedere in modo abbastanza affidabile le conversazioni in cui vengono poste domande su argomenti sensibili.
Microsoft ha sottolineato che nel caso di monitoraggio di massa del traffico, ad esempio da parte di un provider o di un’agenzia governativa, questo metodo può essere utilizzato per identificare gli utenti che pongono domande su riciclaggio di denaro, dissenso politico o altri argomenti controllati, anche se l’intero scambio è crittografato.
Gli autori del documento sottolineano un dettaglio inquietante. Più a lungo l’attaccante raccoglie campioni di addestramento e più esempi di dialogo presenta, più accurata sarà la classificazione. Questo trasforma Whisper Leak da un attacco teorico a uno pratico. In seguito alla divulgazione responsabile, OpenAI, Mistral, Microsoft e xAI hanno implementato misure di protezione.
Una tecnica di sicurezza efficace consiste nell’aggiungere una sequenza casuale di testo di lunghezza variabile alla risposta. Questo offusca la relazione tra lunghezza del token e dimensione del pacchetto, rendendo il canale laterale meno informativo.
Microsoft consiglia inoltre agli utenti preoccupati per la privacy di evitare di discutere argomenti sensibili su reti non attendibili, di utilizzare una VPN quando possibile, di scegliere opzioni LLM non in streaming e di collaborare con provider che hanno già implementato misure di mitigazione.
In questo contesto, Cisco ha pubblicato una valutazione di sicurezza separata di otto modelli LLM open source di Alibaba, DeepSeek, Google, Meta , Microsoft, Mistral, OpenAI e Zhipu AI. I ricercatori hanno dimostrato che tali modelli hanno prestazioni scarse in scenari con più turni di dialogo e sono più facili da ingannare in sessioni più lunghe. Hanno anche scoperto che i modelli che davano priorità all’efficienza rispetto alla sicurezza erano più vulnerabili ad attacchi multi-step.
Ciò supporta la conclusione di Microsoft secondo cui le organizzazioni che adottano modelli open source e li integrano nei propri processi dovrebbero aggiungere le proprie difese, condurre regolarmente attività di red teaming e applicare rigorosamente i prompt di sistema.
Nel complesso, questi studi dimostrano che la sicurezza LLM rimane un tema irrisolto. La crittografia del traffico protegge i contenuti, ma non sempre nasconde il comportamento del modello. Pertanto, sviluppatori e clienti di sistemi di intelligenza artificiale dovranno considerare questi canali collaterali, soprattutto quando lavorano su argomenti sensibili e su reti in cui il traffico può essere osservabile da terze parti.
