

Quando sviluppiamo modelli di Machine Learning, solitamente dobbiamo eseguire diversi esperimenti per capire quale settaggio degli iperparametri risulta essere il migliore per un determinato algoritmo. Questo può spesso portare a un codice lungo e sporco e a perdere traccia di quale risultato corrisponda a quale settaggio. Ho visto spesso sviluppatori fare “hard coding” (cioè inserire gli iperparametri direttamente nel codice) in modo rigido. Lanciavano quindi l’esperimento e annotavano il risultato in un file Excel. Sono certo che possiamo migliorare questo flusso di lavoro.
Se siete interessati nel mio ultimo articolo ho parlato di come sviliuppare da zero una pipeline con MLflow.

Oggi voglio aggiungere un altro livello di complessità e spiegare come integrare anche Hydra nel flusso. Hydra è un fantastico strumento open-source che, tra le altre cose, consente di eseguire test con diversi settaggi del modello.
Iniziamo quindi a scrivere il primo file Python per addestrare un semplice modello di ML come il Random Forest. Possiamo utilizzare il dataset Titanic e importarlo tramite la libreria Seaborn.
Il dataset Titanic ha una licenza open-source (licenza MIT). È possibile trovarlo su GitHub a questo indirizzo.
All’interno del nostro progetto, creiamo una sottocartella che sarà un componente della pipeline MLflow e chiamiamola “random_fortest”. All’interno di questo componente generiamo lo script “run.py” e scriviamo il codice per eseguire l’addestramento del modello.
In questo pezzo di codice, implementeremo le fasi standard di preelaborazione e di addestramento che credo non necessitino di troppe spiegazioni.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
def go():
titanic = sns.load_dataset("titanic")
# Preprocess the data: drop rows with missing values and convert categorical to numerical
titanic.dropna(subset=["age", "embarked", "deck"], inplace=True)
titanic = pd.get_dummies(
titanic,
columns=["sex", "embarked", "class", "who", "deck", "embark_town", "alive"],
drop_first=True,
)
# Define features and target
X = titanic.drop(["survived"], axis=1)
y = titanic["survived"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100,
max_depth=4,
max_samples=20,
min_samples_split=5,
random_state=42,
)
# Train the model
rf.fit(X_train, y_train)
# Predict on the test set
y_pred = rf.predict(X_test)
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy of RandomForest classifier on test set: {accuracy:.2f}")
Una cosa che avrete notato è che il Random Forest accetta come input molti iperparametri, che ora ho scelto in modo casuale. Per migliorare il nostro script, possiamo prendere questi iperparametri come argomenti della funzione go(). Quindi creiamo un file YAML in cui settiamo questi iperparametri. In seguito, chiederemo all’utente di passarci da terminale il path del file YAML che desidera utilizzare e da cui leggere le impostazioni del modello.
Vediamo quindi come possiamo modificare il nostro script. Sfrutteremo la libreria argparse per consentire agli utenti di specificare alcuni parametri di input (come il file di configurazione del modello) dal terminale.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
import argparse
import yaml
def go(args):
with open(args.model_config) as fp:
model_config = yaml.safe_load(fp)
titanic = sns.load_dataset("titanic")
# Preprocess the data: drop rows with missing values and convert categorical to numerical
titanic.dropna(subset=["age", "embarked", "deck"], inplace=True)
titanic = pd.get_dummies(
titanic,
columns=["sex", "embarked", "class", "who", "deck", "embark_town", "alive"],
drop_first=True,
)
# Define features and target
X = titanic.drop(["survived"], axis=1)
y = titanic["survived"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize RandomForestClassifier
rf = RandomForestClassifier(**model_config["random_forest"])
# Train the model
rf.fit(X_train, y_train)
# Predict on the test set
y_pred = rf.predict(X_test)
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"\n\nAccuracy of RandomForest classifier on test set: {accuracy:.2f}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Train a Random Forest",
fromfile_prefix_chars="@",
)
parser.add_argument(
"--model_config",
type=str,
help="Path to a YAML file containing the configuration for the random forest",
required=True,
)
args = parser.parse_args()
go(args)
Come avrete letto nel mio precedente articolo sulle pipeline con MLflow, un componente di MLflow ha bisogno anche di un conda.yaml in cui si specifica l’ambiente di sviluppo. Ecco quindi lo yaml che possiamo usare:
name: random_forest
channels:
- conda-forge
- defaults
dependencies:
- pandas
- pip
- scikit-learn
- matplotlib
- plotly
- pillow
- mlflow
- seaborn
- pip:
- omegaconf
Ma sappiamo anche che un componente MLflow ha bisogno di un file MLproject:
name: random_forest
conda_env: conda.yml
entry_points:
main:
parameters:
model_config:
description: JSON blurb containing the configuration for the decision tree
type: str
command: >-
python run.py --model_config {model_config}
In questo file MLproject diamo un nome al componente, definiamo il file conda da utilizzare e inseriamo i parametri di input per la configurazione del modello.
Ora, al di fuori del componente, come main entry, creiamo altri file:
Ecco un immagine per chiarire la struttura del progetto.
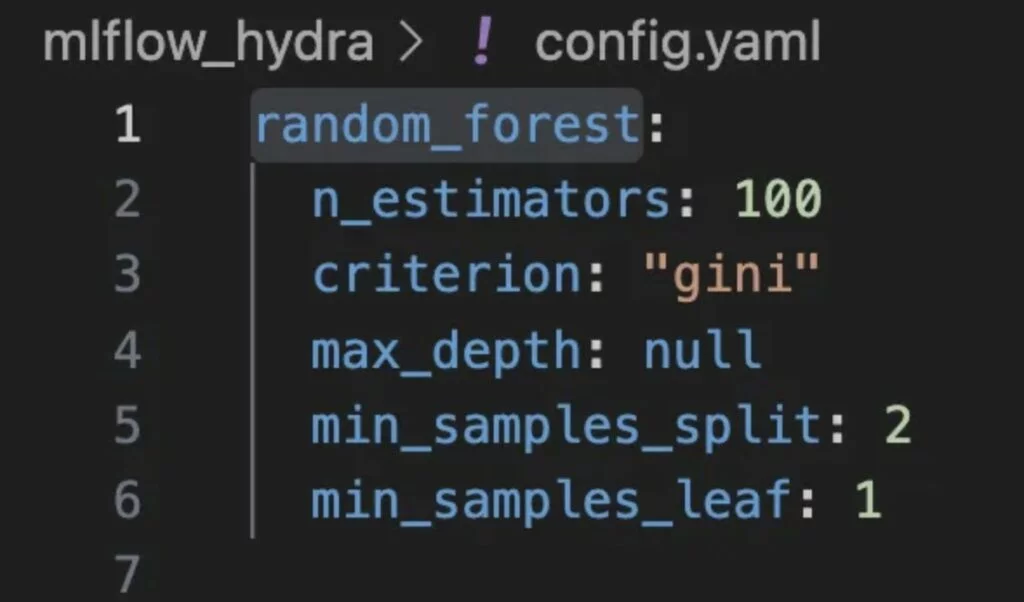
Iniziamo definendo il file config.yaml. Ci sono molti iperparametri che si possono provare. Ne ho scelti solo alcuni, sentitevi liberi di sperimentarne altri.
random_forest:
n_estimators: 100
criterion: "gini"
max_depth: null
min_samples_split: 2
min_samples_leaf: 1
Ora specifichiamo il file conda per questo entry point.
name: main_component
channels:
- conda-forge
- defaults
dependencies:
- requests
- pip
- mlflow
- hydra-core
- pip:
- wandb
- hydra-joblib-launcher
Definiamo ora come deve essere scritto main.py per utilizzare facilmente Hydra.
Per usare il file di configurazione all’interno del nostro codice Python, è sufficiente utilizzare il decoratore Hydra in cui si specifica il nome del file di configurazione e Python lo leggerà automaticamente. Vediamo un esempio.
import mlflow
import os
import hydra
from omegaconf import DictConfig, OmegaConf
# This automatically reads in the configuration
@hydra.main(config_name="config")
def go(config: DictConfig):
# You can get the path at the root of the MLflow project with this:
root_path = hydra.utils.get_original_cwd()
# Serialize decision tree configuration
model_config = os.path.abspath("random_forest_config.yml")
with open(model_config, "w+") as fp:
fp.write(OmegaConf.to_yaml(config))
_ = mlflow.run(
os.path.join(
root_path, "random_forest"
), # run the subdirectory mlflow pipeline
"main",
parameters={
"model_config": model_config,
},
)
if __name__ == "__main__":
go()
Come potete osservare, il file di configurazione viene letto grazie al decoratore di Hydra. Dopodiché, creo on the fly un nuovo file yaml chiamato random_forest_config.yml da passare allo script run.py. Se ricordate, questo script si aspettava proprio un file yaml con la configurazione del random forest.
Perché allora creare un secondo yaml invece di passargli direttamente il config.yaml? Semplicemente perché in config.yaml potrei avere impostazioni anche per altre cose oltre che al random forest. In questo caso, non ce ne sono perché si tratta di un esempio giocattolo, quindi potremmo anche saltare questo passaggio.
Lanciamo il componente “random_forest” della pipeline con il comando mlflow.run()
Ora potremmo eseguire lo script main.py con comandi speciali derivati da Hydra per modificare alcune impostazioni del file di configurazione del modello in modo semplice e veloce.
Ma sappiamo bene che non eseguiremo il comando “python main.py” a mano, ma definiremo questo comando nel MLproject. Quindi nel MLproject dovremo dire che il comando “python main.py” può essere accompagnato da altri parametri accettati da Hydra.
name: run_pipeline
conda_env: conda.yaml
entry_points:
main:
parameters:
hydra_options:
description: Hydra parameters to override
type: str
default: ""
command: >-
python main.py $(echo {hydra_options})
Notate che il comando che eseguiamo ha ora un pezzo di codice in più:
python main.py $(echo {hydra_options}).
In questo modo, aggiungiamo piccole modifiche ai comandi che vengono accettati da Hydra. Vedremo degli esempi tra poco.
Ora, se lanciamo il tutto con “mlflow run .“, verrà avviata l’intera pipeline.
mlflow run .
Ci vorrà un po’ di tempo perché MLflow dovrà generare gli ambienti necessari che sono stati specificati nei file conda.yaml.
La seconda volta che si avvia la pipeline sarà più veloce perché MLflow è abbastanza intelligente da capire che quell’ambiente esiste già e non è necessario crearlo di nuovo.
Come si può vedere nel mio caso, tutto è andato bene senza errori e posso vedere l’accuratezza raggiunta dal modello.

Avere una pipeline di questo tipo è molto comodo perché ora posso testare un modello con iperparametri diversi semplicemente cambiando un file yaml.
Sfruttiamo il codice che abbiamo scritto per lanciare altri esperimenti in modo semplice. Nel MLproject, nella voce riguardo l’entry point, abbiamo detto che accettiamo parametri di input che sono utili per modificare il comportamento di Hydra.
Possiamo modificare alcuni campi del file di configurazione direttamente dal terminale. Se leggete attentamente il file MLproject vedrete che possiamo modificare un parametro chiamato “hydra_options”. Quindi definiamo all’interno di questo parametro i valori del file di configurazione che vogliamo richiamare.
Ad esempio, se voglio fare un test con un numero di stimatori pari a 30, posso eseguire la pipeline di Mlflow nel modo seguente.
mlflow run . -P hydra_options="random_forest.n_estimators=30"
Naturalmente, è possibile specificare più modifiche ai parametri contemporaneamente. Nel prossimo esempio, modifico sia n_estimator che min_sample_split:
mlflow run . -P hydra_options="random_forest.n_estimators=100 random_forest.min_samples_split=5"
Semplice, vero? Ora per lanciare vari esperimenti basta cambiare una stringa da terminale!
Tuttavia, non abbiamo visto come questo possa accelerare notevolmente la fase di hyperparameter tuning. Supponiamo che il risultato di ogni esperimento venga salvato su un file invece che stampato a console (potete provare a implementarlo voi stessi).
Possiamo dire a Hydra, tramite terminale, di provare combinazioni di valori diversi per ogni iperparametro con un solo comando. Successivamente, controlleremo i log dei risultati e sceglieremo il migliore settaggio.
Per fare questo usiamo la funzione multi-run di Hydra, perché dovranno essere lanciate molte run per ciascuna delle combinazioni di iperparametri.
I vari valori da testare essere separati da virgole. Alla fine della stringa, si aggiunge un “-m” per indicare che si tratta di una multi-run. Ecco un esempio pratico:
mlflow run . -P hydra_options="random_forest.n_estimators=10,50,100 random_forest.min_samples_split=3,5,7 -m"
Abbiamo finalmente lanciato il nostro hyperparameter tuning con Hydra! 🥳
Se vogliamo provare tutti i numeri da x1 a x2, possiamo usare la funzione range(x1,x2). Ad esempio, se per min_samples_split voglio provare tutti i numeri da 1 a 5, posso usare il comando in questo modo:
mlflow run . -P hydra_options="random_forest.n_estimators=10,50,100 random_forest.min_samples_split=range(1,5) -m"
MLflow e Hydra sono strumenti fantastici per lavorare su progetti di data science. Con un pò sforzo iniziale, ci permettono di lanciare esperimenti facilmente. In questo modo possiamo dedicarci effettivamente a capire perché alcuni esperimenti funzionano meglio di altri e trarre le nostre conclusioni senza dover andare a modificare il codice ogni volta.
In un prossimo tutorial, mostrerò anche come salvare i risultati degli esperimenti in uno strumento esterno per tenerne traccia. Di solito uso Weight & Biases, ma anche MLflow stesso offre questa possibilità.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/