

Diverse statistiche dicono che tra il 𝟱𝟬% e il 𝟵𝟬% dei modelli di machine learning sviluppati non arrivano in produzione. Ciò è spesso dovuto a una mancata strutturazione del lavoro. Spesso le competenze acquisite in ambito accademico (o su Kaggle) non sono sufficienti per mettere in piedi un intero progetto di Machine Learning che verrà utilizzato da migliaia di persone.
Una delle competenze più richieste quando si cerca un lavoro nel settore del Machine Learning è la capacità di utilizzare strumenti che consentono l’orchestrazione di pipeline complesse, come MLflow.

In questo articolo vedremo come strutturare un progetto in varie fasi e gestire tutte gli step in modo ordinato.
MLflow è una piattaforma open-source per la gestione end-to-end del ciclo di vita di un progetto di Machine Learning sviluppata da Databricks.
Questo tool offre una serie di funzionalità, come il monitoraggio dei modelli in fase di addestramento, l’utilizzo di un archivio di artefatti, la messa in produzione dei modelli e altro ancora. Oggi vedremo l’utilizzo di MLflow come orchestratore di una pipeline. Questo perché, soprattutto nel mondo dell’AI, dove ci sono vari passaggi e varie sperimentazioni, è fondamentale avere un codice pulito, comprensibile e facilmente riproducibile.
Ma quali sono esattamente questi passaggi che dobbiamo gestire con MLflow? Questo dipende dal contesto del nostro lavoro. Una pipeline di Machine Learning può cambiare a seconda del luogo in cui stiamo lavorando e dell’obiettivo finale. Ad esempio, una pipeline per risolvere un compito di Kaggle è semplice, poiché la maggior parte del tempo è dedicata alla modellazione. Mentre nell’industria abbiamo solitamente vari step, ad esempio per il controllo della qualità dei dati e del codice.
Per semplicità, prendiamo in considerazione una pipeline elementare.

Se vari team lavorano su un progetto, vogliamo che sviluppino ciascuno di questi step in maniera altamente indipendente. Coloro che si occupano della modellazione, si occupano solamente di questa componente, senza preoccuparsi ad esempio della raccolta o pulizia dei dati.
Supponiamo inoltre (esagerando un pò) di avere un team per ogni componente della pipeline. Vogliamo facilitare il lavoro di ciascun team consentendogli di lavorare con gli strumenti e i linguaggi che conosce meglio. Vorremmo quindi ambienti di sviluppo indipendenti per ogni fase. Ad esempio, lo scarico dei dati può essere sviluppato in C++, la pulizia dei dati in Julia, la modellazione in Python e l’inferenza in Java. Con MLflow è possibile!
Potete installare MLflow da terminale usando pip.
!pip install mlflowUn progetto MLflow è composto da 3 parti principali, che sono:
Codice: Il codice che scriviamo per risolvere il task su cui stiamo lavorando.
Ambiente: Dobbiamo definire l’ambiente. Di quali librerie ha bisogno il mio codice per funzionare?
Definizione del progetto MLflow: ogni progetto MLflow ha un file chiamato MLproject che definisce cosa deve essere eseguito, quando e come l’utente deve interagire con il progetto.
Il codice per ogni componente della pipeline che scriverò in questo articolo sarà in Python per semplicità. Ma, come già detto, ricordate che questo non è un obbligo.
Come gestiamo gli ambienti? Per definire un ambiente di sviluppo riproducibile e isolato possiamo utilizzare diversi strumenti. I principali sono docker e conda. In questo esempio userò conda, perché mi permette di specificare le dipendenze in modo semplice e veloce, mentre docker ha una curva di apprendimento un po’ più difficile. Se avete bisogno di scaricare conda, vi consiglio la versione più leggera, chiamata miniconda.
Possiamo creare un file conda.yml per costruire l’ambiente di sviluppo e successivamente creare un virtual environment.
E’ possibile anche installare pacchetti con i comandi pip nel nostro conda.yml, come nel caso di wandb qui sotto. (p.s. In questo caso avremmo nemmeno bisogno di wandb).
#conda.yml
name: download_data
channels:
- conda-forge
- defaults
dependencies:
- requests
- pip
- mlflow
- hydra-core
- pip:
- wandb
Ora, per creare l’ambiente definito in conda.yml, eseguiamo il seguente comando nel terminale.
conda env create --file=conda.yaml
Attiviamolo.
conda activate download_dataDobbiamo infine definire un file MLproject. Si presti attenzione a questo file, anche se è scritto come uno yaml, non ha bisogno di estensioni.
In questo file, specifichiamo innanzitutto il nome dello step e l’ambiente conda da utilizzare. Poi bisogna specificare qual è l’entry point, cioè il file python principale da cui avviare la computazione. Dopo di che, si definiscono anche i parametri necessari per lanciare il file. Ad esempio, nella fase di download, mi aspetto che l’utente passi un URL da cui scaricare i dati.
Come ultimo punto, scriviamo il comando che MLflow deve effettivamente lanciare.
name: download_data
conda_env: conda.yml
entry_points:
main:
parameters:
data_url:
description: URL of the data to download
type: uri
command: >-
python main.py --data_url {data_url} #in the brackets insert the input variable
Siamo finalmente pronti a scrivere il codice Python del file main.py
Nel codice Python, dobbiamo accettare come input l’argomento atteso nel file MLproject, il “data_url”. Possiamo quindi fare uso di argparser in modo che l’utente possa passare questo argomento da terminale.
Eseguiamo la funzione run(), che non fa altro che leggere il file CSV dall’URL e salvarlo localmente, effettuando così un semplice download dei dati, come previsto da questo componente.
Utilizziamo dati open-source (licenza MIT). In particolare, il classico dataset Titanic, che si può trovare su GitHub a questo URL: https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv.
Ecco un esempio del file main.py.
import argparse
import pandas as pd
def run(args):
df = pd.read_csv(args.data_url)
df.to_csv("data.csv")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_url", type=str, required=True)
args = parser.parse_args()
run(args)
Ora possiamo lanciare l’intero componente con MLflow. In MLflow per specificare un parametro si usa il flag -P.
mlflow run . -P data_url="https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
Dai log del terminale si vedrà che prima Mlflow cercherà di ricreare l’ambiente di sviluppo usando il conda.yaml (ci vorrà un po’ di tempo la prima volta) e poi lancerà il codice. Alla fine, dovreste vedere il vostro dataset scaricato!
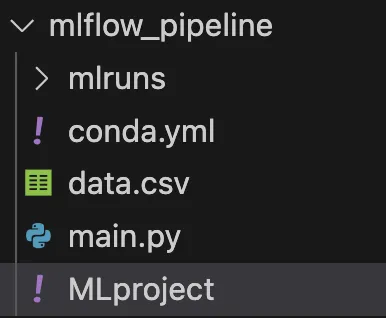
Perfetto, ora abbiamo le basi per creare un progetto con MLflow composto da un solo componente. Ma come si fa a sviluppare un’intera pipeline?
In MLflow una pipeline non è altro che un progetto MLflow composto da altri progetti (componenti) MLflow!
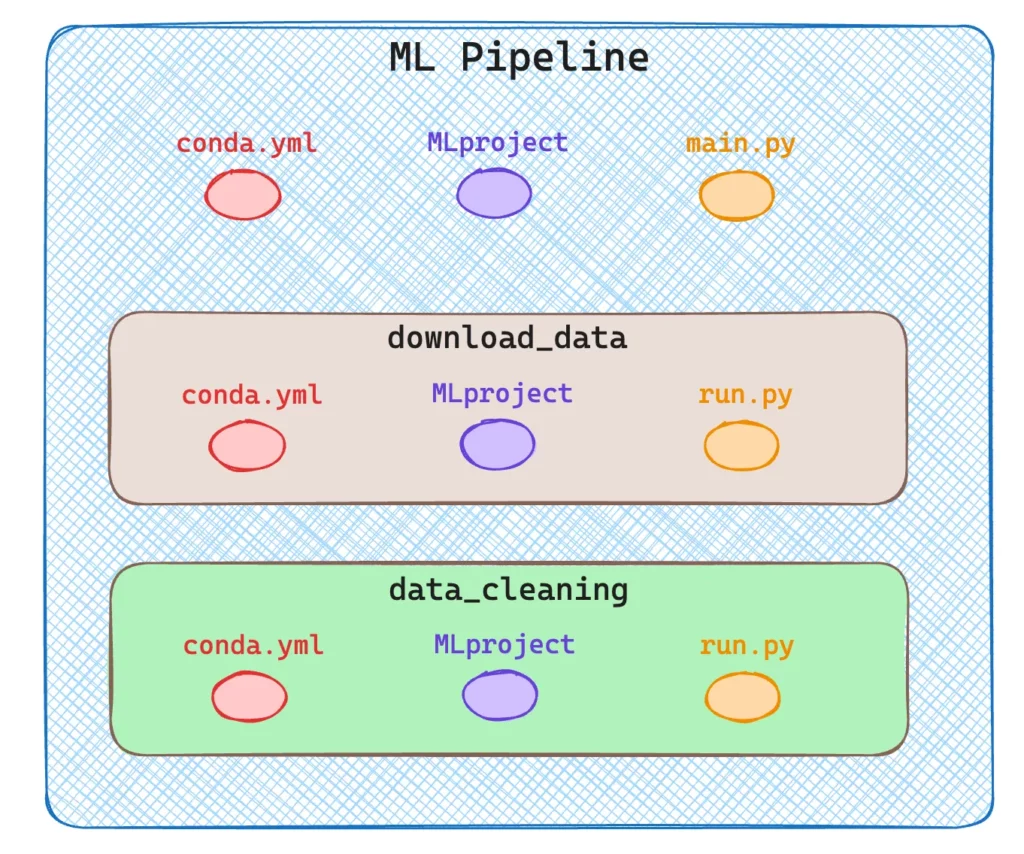
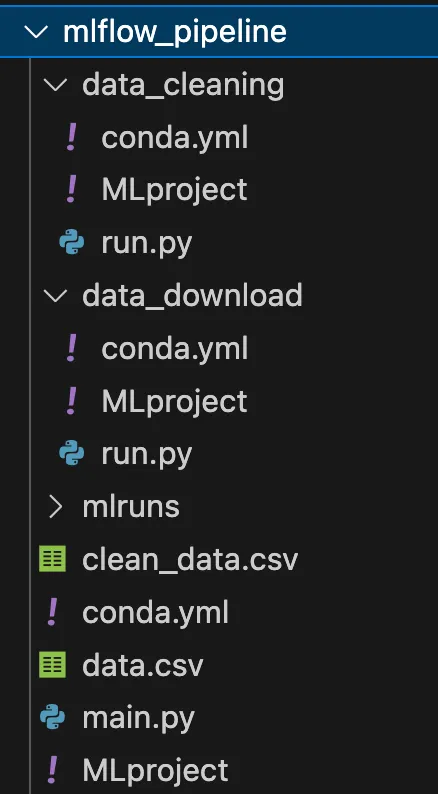
Dato che voglio creare una pipeline con più componenti nella mia cartella principale, avrò due sotto-directory, una per ogni componente, come si può vedere nell’immagine successiva.
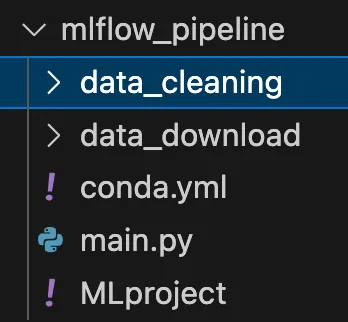
Per semplicità, ho eseguito solo due fasi, il download dei dati e la loro pulizia. Ovviamente, una vera pipeline è composta da molto di più, addestramento, inferenza ecc.
Come mostrato nel diagramma precedente, ogni componente/fase è un progetto MLflow descritto da 3 file. La struttura completa è riportata nell’immagine seguente.
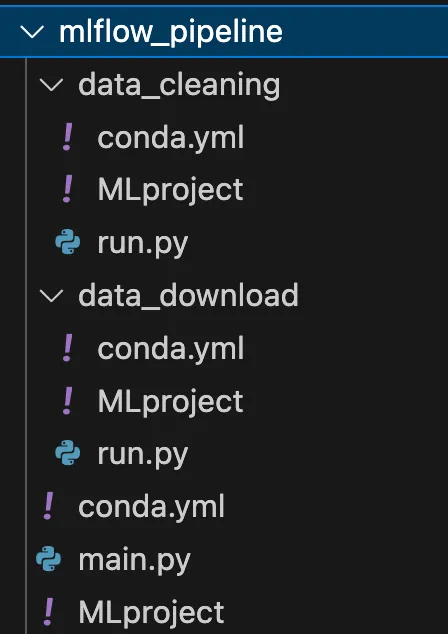
Vediamo ora come ho definito tutti i file di questa cartella.
🟢 mlflow_pipeline/conda.yml
Questo file non è diverso da quelli precedenti: definisce l’ambiente di sviluppo.
#conda.yaml
name: mlflow_pipeline
channels:
- conda-forge
- defaults
dependencies:
- pandas
- mlflow
- requests
- pip
- mlflow
🟢 mlflow_pipeline/MLproject
Non sono sempre interessato a lanciare tutti gli step della pipeline, ma a volte potrei volerne specificare solo alcuni. Quindi quello che possiamo fare è accettare come input una stringa che definisce tutti i passaggi che voglio lanciare separati da una virgola.
Quindi, quando MLflow viene lanciato, il comando sarà qualcosa di simile a:
mlflow run . P steps=“download,cleaning,training”
name: mlflow_pipeline
conda_env: conda.yml
entry_points:
main:
parameters:
steps:
description: steps you want to perform seprarated by comma
type: str
data_url:
descripton: url of data
🟢 mlflow_pipeline/main.py
In questo file, ora gestiremo gli step della pipeline. Una volta inserito l’input nel parser, facciamo lo split della stringa sulla virgola.
Per ogni step, eseguiamo un mlflow.run, questa volta direttamente da Python senza usare il terminale. Il comando è comunque molto simile: per ogni esecuzione specifichiamo il percorso del componente e l’entry point (sempre main) e, se necessario, passiamo dei parametri.
import argparse
import pandas as pd
import mlflow
all_steps = ["data_download", "data_cleaning", "training"]
def run(args):
data_url = args.data_url
steps = args.steps
active_steps = steps.split(",")
print(active_steps)
if "data_download" in active_steps:
# Download data
_ = mlflow.run(
f"data_download/",
"main",
parameters={
"data_url": data_url,
},
)
if "data_cleaning" in active_steps:
# data cleaning
_ = mlflow.run(f"data_cleaning/", "main")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--steps", type=str, required=True)
parser.add_argument("--data_url", type=str, required=True)
args = parser.parse_args()
run(args)
Da qui in poi, la definizione degli altri componenti non è molto differente da quanto gia fatto in precedenza. Continuiamo a descrivere le fasi di download e pulizia.
⚠️ Tutti i file conda.yml sono uguali, quindi eviterò di ripeterli più volte.
🟢 mlflow_pipeline/data_download/MLproject
Come prima, data_download si aspetta un parametro di input, l’URL per scaricare i dati, il resto è standard.
name: download_data
conda_env: conda.yml
entry_points:
main:
parameters:
data_url:
description: url of data to download
type: str
command: >-
python run.py --data_url {data_url}
🟢 mlflow_pipeline/data_download/run.py
In run.py prendiamo il file URL, come definito nell’ MLproject, e lo usiamo per aprire un dataframe pandas e salvare il dataset localmente con estensione .csv
import argparse
import pandas as pd
def run(args):
df = pd.read_csv(args.data_url)
df.to_csv("../data.csv")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_url", type=str, required=True)
args = parser.parse_args()
run(args)
🟢 mlflow_pipeline/data_cleaning/MLproject
In questo caso, la pulizia dei dati è molto semplice. Mi interessa concentrarmi su come strutturare la pipeline, non sulla creazione di passaggi complessi. Non ci aspettiamo alcun parametro di input, quindi abbiamo solo bisogno di eseguire run.py
name: data_cleaning
conda_env: conda.yml
entry_points:
main:
command: >-
python run.py
🟢 mlflow_pipeline/data_cleaning/run.py
Nella pulizia vera e propria in questo caso, si eliminano tutte le righe che contengono valori nulli e si salva il nuovo dataframe come CSV nella cartella principale locale.
import pandas as pd
def run():
df = pd.read_csv("../data.csv")
df.dropna(inplace=True)
df.to_csv("../clean_data.csv")
if __name__ == "__main__":
run()
Ora, se non abbiamo commesso errori, possiamo eseguire l’intera pipeline con un singolo comando mlflow, specificando i parametri appropriati, quindi i passaggi e l’URL del set di dati.
mlflow run . -P steps="data_download,data_cleaning" -P data_url="https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
Vedrete che tutti i passaggi saranno eseguiti correttamente e troverete due nuovi file CSV nella vostra directory! 🚀
In questo articolo abbiamo visto come si compone un progetto in MLflow e come definire una pipeline come una sequenza di componenti MLflow.
Ogni fase della pipeline può essere sviluppata in modo indipendente perché vive nel proprio ambiente indipendente. Possiamo utilizzare linguaggi e strumenti diversi per lo sviluppo di ogni step e MLflow lavora solo come orchestratore. Spero che questo articolo vi abbia dato un’idea di come utilizzare MLflow.
Sebbene MLFlow sia molto utile per tracciare gli esperimenti di apprendimento automatico, la sua complessità e la sua curva di apprendimento possono scoraggiare i progetti più piccoli o i team che si avvicinano per la prima volta all’ MLOps. Tuttavia, è molto comodo da usare quando il tracciamento degli esperimenti, il versionamento dei dati e dei modelli e la collaborazione sono essenziali, il che lo rende ideale per progetti di medie e grandi dimensioni.
Le funzionalità che offre sono molte di più di quelle viste in questo articolo: ad esempio, è possibile utilizzarlo per monitorare le prestazioni di un modello o per salvare gli artefatti creati.
Nei prossimi articoli vi mostrerò come integrare ulteriori strumenti all’interno di MLflow per utilizzarlo al massimo delle sue potenzialità!
Per tenervi aggiornati in materia di AI seguitemi su Linkedin!


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/