



C’è un fenomeno noto ma di cui si parla poco, e che ogni giorno colpisce senza distinzione: la pornografia algoritmica.
È una forma di inquinamento semantico che trasforma l’identità digitale in un terreno di caccia.
Un solo algoritmo può trascinare milioni di nomi in una catena invisibile, spingendoli dove non dovrebbero apparire.
È il punto estremo dell’automatismo digitale: quando i motori di ricerca, invece di filtrare lo sporco del web, finiscono per amplificarlo.
Dal punto di vista tecnico, ciò che emerge è che questo fenomeno non nasce da un errore dell’algoritmo, ma da pratiche di Black Hat SEO applicate su scala industriale. I grandi portali per adulti generano automaticamente pagine costruite su combinazioni casuali di nomi reali e termini erotici con un unico obiettivo: intercettare ricerche, produrre traffico e alimentare circuiti pubblicitari.
Sono pagine create per sfruttare ogni possibile variazione semantica e trasformarla in impression monetizzabili. Ed è questa la ricerca condotta dal team di Red Hot Cyber, per spiegare il funzionamento di questo scempio digitale.
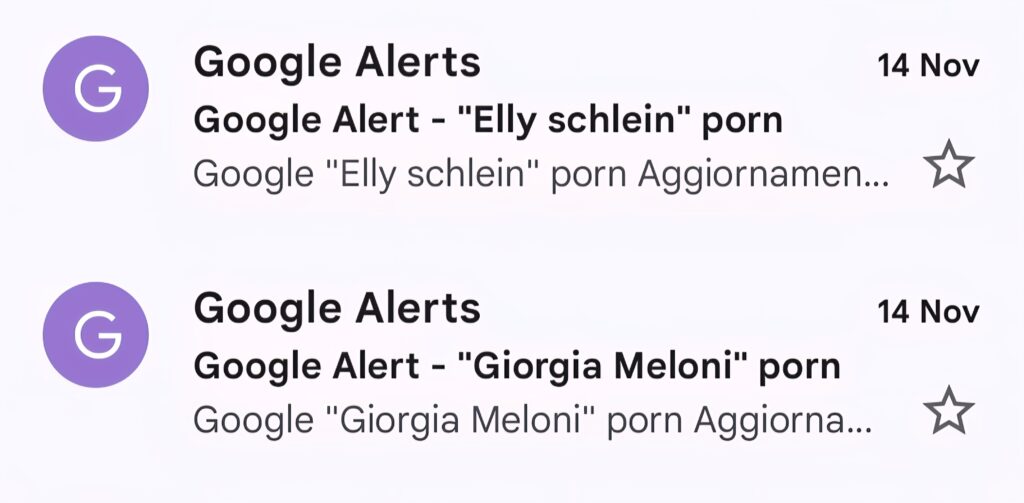
In questo articolo non leggerete alcun nome reale all’interno del testo. È una scelta precisa.
La pornografia algoritmica vive di accoppiamenti linguistici ripetuti: basta che un nome compaia nel posto sbagliato perché gli algoritmi lo registrino, lo combinino, lo trascinino altrove. Ripeterlo qui significherebbe contribuire, anche solo per un istante, allo stesso meccanismo che l’indagine intende segnalare.
Per questo i nomi restano confinati negli screenshot tecnici, dove non generano nuove pagine indicizzabili né nuove associazioni. Sebbene Google disponga di tecnologie OCR molto avanzate e possa, in alcuni casi, leggere il testo contenuto nelle immagini, non esistono evidenze né documentazione ufficiale che mostrino un uso sistematico di queste informazioni per creare accostamenti sensibili nelle SERP. Nei contesti di analisi come questo, il testo presente negli screenshot ha esclusivamente valore documentale.
Segnalare un fenomeno richiede anche di non diventare parte della sua eco linguistica: quindi, i nomi restano fuori e parlano solo gli algoritmi.
Basta una ricerca su Google per comprenderne la logica.
Non servono nomi reali: basta immaginare la struttura tipica delle query che generano le cosiddette pagine fantasma, cioè l’accoppiata “Nome Cognome + parola erotica”.
Il meccanismo segue sempre lo stesso schema: un nome reale, accostato a un termine sessuale, diventa il seme con cui gli algoritmi dei portali pornografici producono automaticamente nuove pagine e URL indicizzabili.

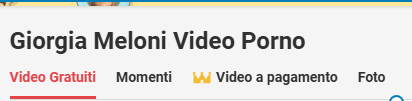

In realtà è una rete di pagine automatiche generate dai grandi portali pornografici, che producono migliaia di combinazioni tra nomi noti e parole erotiche.
Quando un nome viene cercato nei motori interni di questi siti o compare come query già intercettata da Google, il sistema lo usa come tag semantico per creare una nuova pagina pubblica. Anche se non esiste alcun contenuto effettivo, la piattaforma produce una struttura HTML coerente e indicizzabile.
Tecnicamente, queste pagine sono soft 404 o empty pages: rispondono con un codice 200 OK, ma non offrono alcun contenuto utile.
I motori di ricerca tendono comunque a includerle nell’indice perché il dominio è autorevole, la struttura SEO coerente e il pattern in linea con migliaia di altre pagine simili.
Così anche un titolo vuoto ma semanticamente tossico, in cui un nome reale viene accostato a termini che suggeriscono contenuti impropri, è sufficiente a innescare un’associazione nei modelli linguistici di ranking e suggerimento.
È il paradosso delle pagine fantasma: non mostrano nulla, ma inquinano tutto.
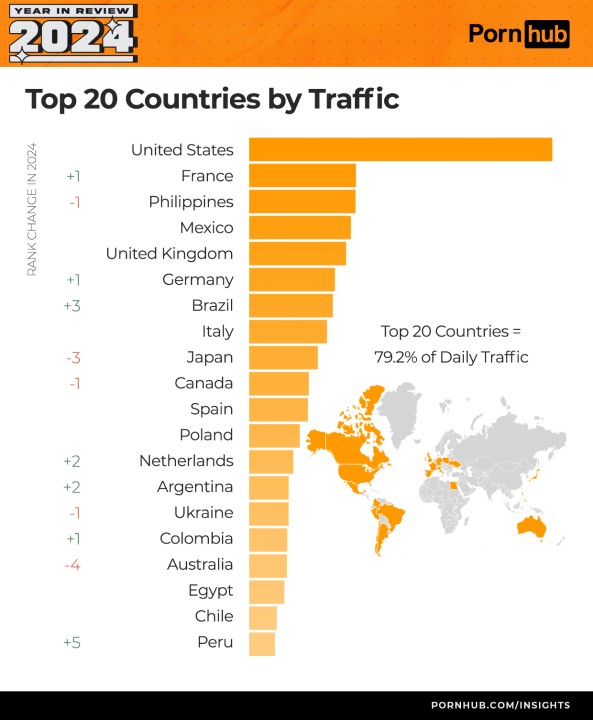
I dati ufficiali di Pornhub Insights – Year in Review 2024 confermano che le Olimpiadi di Parigi hanno avuto un impatto immediato sulle ricerche legate al mondo dello sport. Il report non indica una tempistica precisa, ma la tendenza è evidente: quando un evento domina il discorso pubblico, diventa materiale pornografico.
Nel terzo trimestre del 2024, le ricerche per termini come “swimmer” (+101%), “gymnastics” (+79%), “athlete” (+88%) e “volleyball” (+165%) sono esplose, insieme a query direttamente legate ai giochi, come “sex olympics” e “nude olympics”.
Il documento lo riassume così: tutto ciò che è “front and center” nella cultura viene inevitabilmente sessualizzato dagli utenti. Non è l’algoritmo a generare il fenomeno, ma il volume stesso delle ricerche: un’onda di attenzione collettiva che modella ciò che i sistemi automatici troveranno e organizzeranno.
È all’interno di questa dinamica – dove ciò che attira attenzione viene amplificato e replicato – che attecchiscono i meccanismi di inquinamento semantico descritti in questo articolo.
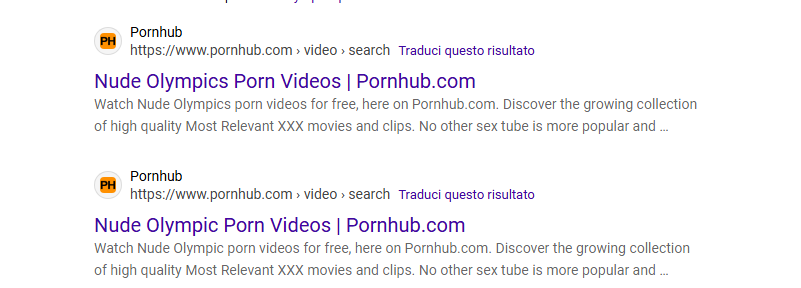
Nel linguaggio di Google, le doorway pages sono pagine create per intercettare query specifiche e indirizzare l’utente altrove.
Servono a manipolare il ranking, non a informare.
Wikipedia le definisce pagine ponte o gateway pages: strutture progettate per influenzare gli indici dei motori di ricerca.
Le dinamiche osservate nei portali per adulti seguono lo stesso principio, non tanto nell’intento quanto nell’effetto.
Si tratta di pagine generate in serie, con titoli costruiti su combinazioni di parole e reindirizzamenti interni che generano traffico anche senza alcun contenuto.
Dietro questo meccanismo non c’è un attacco diretto, ma una strategia puramente economica.
I siti per adulti vivono di traffico: più keyword intercettano, più click generano.
E ogni click significa pubblicità, tracciamento, cookie e profili vendibili.
Per moltiplicare le visite, i motori porno usano generatori automatici di pagine (SEO farming) che combinano parole comuni e nomi reali in modo massivo:
{persona, istituzione, testata giornalistica, evento} + {parola chiave}
È una formula semplice, ma devastante: migliaia di nuove URL ogni giorno, tutte con lo stesso layout, stesso stack server, stessi cookie “settings”, stessa CDN.
Il danno non è solo morale. È strutturale.
Quando il nome di una persona finisce accanto a parole sessuali, gli algoritmi di ricerca apprendono quell’associazione. Anche se la pagina è vuota, anche se nessuno la cerca davvero.
È l’equivalente digitale di una macchia indelebile: invisibile ai più, ma incisa nel grafo semantico che definisce la nostra identità online.
È quello che potremmo definire “porn reputation poisoning” – un avvelenamento reputazionale algoritmico, dove la contaminazione non riguarda i contenuti, ma il linguaggio che li collega.
La parte più preoccupante è la sua invisibilità.
Le vittime raramente se ne accorgono.
Spesso non cercano il proprio nome con parole simili, né ricevono notifiche dai motori di ricerca.
Quasi mai vedono immagini o contenuti espliciti: solo titoli.
Eppure il danno d’immagine si propaga, silenzioso, nei suggerimenti e nelle ricerche correlate.
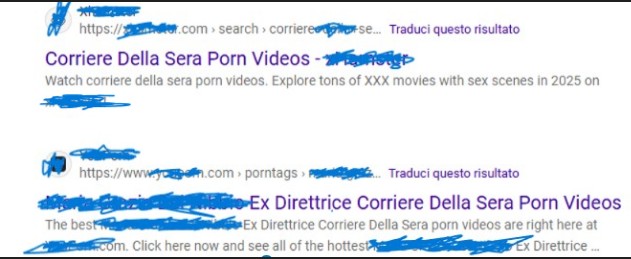
Solo tramite analisi OSINT o monitoraggi reputazionali mirati si scopre la reale estensione del fenomeno: migliaia di risultati “fantasma”, in cui figure pubbliche o istituzioni italiane vengono accostate a contesti pornografici senza che vi sia alcun contenuto vero.
Dal punto di vista delle regole e delle responsabilità online, non c’è un reato immediato
non ci sono immagini, non ci sono video falsi, e nessuno “pubblica” qualcosa di diffamatorio in senso classico.
A generare tutto è un processo automatico: l’esecuzione impersonale di un algoritmo che applica le proprie regole senza distinguere contesto o identità.
In più, il meccanismo sfrutta quasi sempre una zona grigia precisa: l’omonimia.
Le pagine generate automaticamente non mostrano volti, né immagini, né video reali.
Si limitano a ripetere un nome, che può appartenere a chiunque, accostandolo a parole erotiche.
Dal punto di vista tecnico, questo rende difficile stabilire se la combinazione si riferisca a una persona specifica o a un nome generico.
Ed è proprio questa ambiguità a diventare la chiave: nessun volto, nessuna prova, nessuna responsabilità.
I portali per adulti giocano su questa soglia.
Il risultato è che persone diverse, accomunate solo da un nome, finiscono legate allo stesso contesto semantico.
Una trappola perfetta: legalmente difendibile, ma reputazionalmente pericolosa.
Questa è la parte più importante:
il fenomeno non è solo SEO spinto. È una forma di rischio per la reputazione digitale.
Colpisce soprattutto:
Non serve un deepfake: basta un titolo sbagliato, replicato un milione di volte.
È in questo contesto che la fase sperimentale diventa decisiva.
Dopo aver ricostruito il meccanismo teorico della pornografia algoritmica, la fase successiva è stata verificarne l’esistenza empirica.
Quattro esperimenti distinti, condotti in ambiente PowerShell e successivamente validati con analisi forense e modelli di intelligenza artificiale, hanno permesso di osservare il fenomeno in azione, confermandone la natura sistematica, automatica e riproducibile.
Ogni test esplora un diverso anello della catena algoritmica:
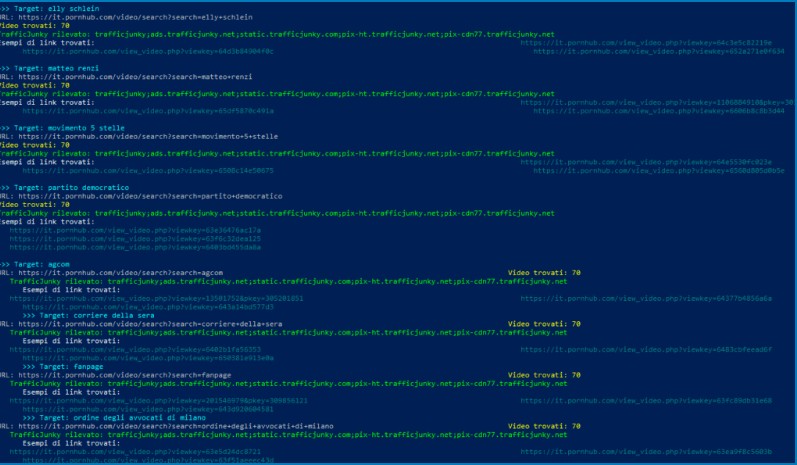
Il primo test ha coinvolto i principali portali del gruppo Aylo (ex MindGeek) – Pornhub, YouPorn, RedTube, Tube8, Spankwire, KeezMovies e Brazzers – utilizzando un insieme di termini neutri e istituzionali. Su tutti i domini, il comportamento si è ripetuto senza eccezioni: l’inserimento di un nome, anche non collegato al mondo adulto, provoca la generazione immediata di una pagina pubblica, formalmente valida e accessibile, anche quando non esistono risultati pertinenti. In ogni caso, la pagina carica comunque le risorse della piattaforma pubblicitaria proprietaria di Aylo (trafficjunky), insieme alla CDN cdn77.net, come se la query avesse restituito contenuti reali.
I log raccolti con PowerShell lo mostrano chiaramente. Le stringhe individuate – trafficjunky, ads.trafficjunky.net, static.trafficjunky.com, pix-ht.trafficjunky.net e pix-cdn77 – indicano che il codice HTML della pagina, anche quando riporta “0 risultati”, attiva risorse pubblicitarie complete: script JavaScript, pixel di tracciamento, endpoint dell’asta, immagini dei banner e moduli di misurazione. Non si tratta di elementi ornamentali: sono gli stessi asset che gestiscono impression, profilazione e ricavi.

Questa dinamica offre un primo indizio chiave: anche quando la pagina non contiene alcun video, la monetizzazione viene attivata. Basta che la pagina esista – anche senza contenuti – perché il circuito economico parta.
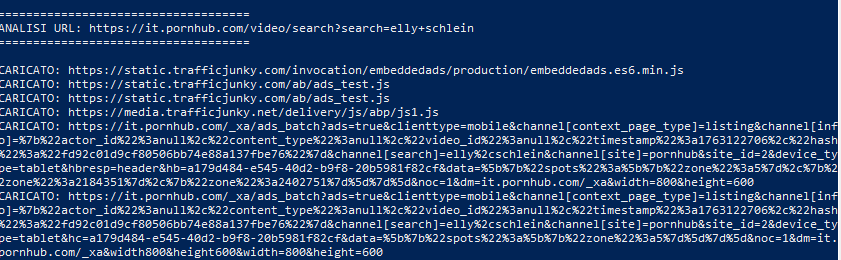
Per escludere ogni dubbio riguardo alla reale esecuzione di questi script, il test è stato replicato con un browser headless basato sul DevTools Protocol. A differenza dell’analisi del sorgente HTML, questa tecnica intercetta in diretta tutte le chiamate di rete, replicando esattamente il comportamento di un browser reale.
La sessione eseguita su Pornhub ha evidenziato richieste dirette agli script pubblicitari di TrafficJunky, agli endpoint dell’asta ads_batch, alle immagini dei banner caricate attraverso cdn77 e persino ai pixel analitici di Google Analytics. Questi elementi non provengono da una lettura statica del codice: sono risorse scaricate, inizializzate e attive durante la navigazione. Ciò conferma che la pagina, anche quando non restituisce risultati, avvia l’intera pipeline tecnica predisposta per visibilità, tracciamento e monetizzazione.
Il comportamento osservato è identico a quello di una pagina che contiene veri contenuti: gli script vengono caricati, le misurazioni avviate, gli endpoint pubblicitari contattati, le risorse CDN richieste e i sistemi di analisi attivati. La sola generazione della pagina basta a mettere in moto l’intero sistema: anche senza risultati video, la pagina attiva comunque l’intero circuito di delivery pubblicitaria.
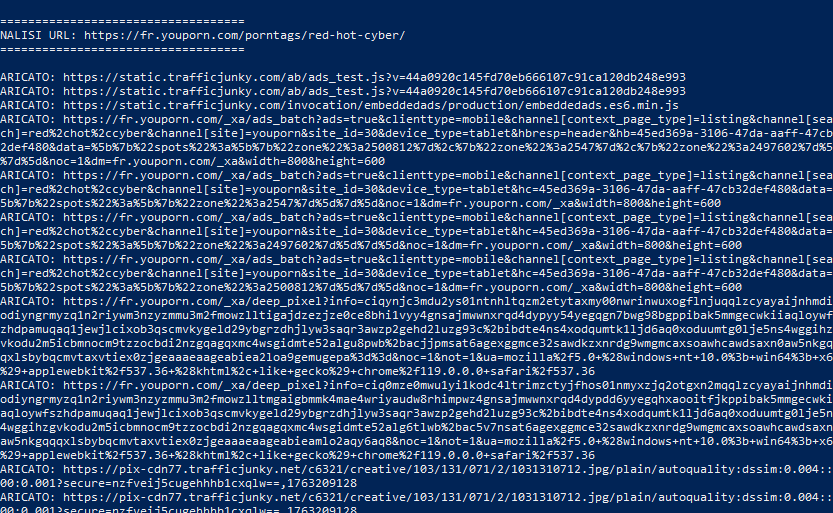
Nel complesso sono stati testati otto termini su otto domini, per un totale di sessantaquattro richieste, analizzate prima in PowerShell e poi con il browser headless. Solo Pornhub ha restituito risultati reali: 560 link nella sola prima pagina. Tutti gli altri siti hanno generato cinquantasei pagine “fantasma”, strutturalmente identiche ma prive di contenuto.
Tutte però – senza eccezioni – hanno risposto con codice 200 OK, presentavano un titolo SEO valido, uno scheletro HTML completo e l’esecuzione degli stessi script pubblicitari già osservati su Pornhub.
Il risultato è inequivocabile: ogni query, anche priva di significato, produce una pagina pronta per essere indicizzata, monetizzata e tracciata. L’associazione tra nomi reali e contesto erotico non nasce da contenuti effettivi, ma da un processo automatico di generazione e monetizzazione integrato nell’infrastruttura stessa di questi portali.

Per verificare se il comportamento osservato nei siti del gruppo Aylo fosse un’eccezione o un pattern più ampio, è stata condotta una seconda analisi su una serie di piattaforme indipendenti: XVideos, xHamster, FapHouse e SoloPornoItaliani.
La metodologia è rimasta identica: scansione headless da terminale, query standardizzate, logging completo di ogni risorsa caricata.
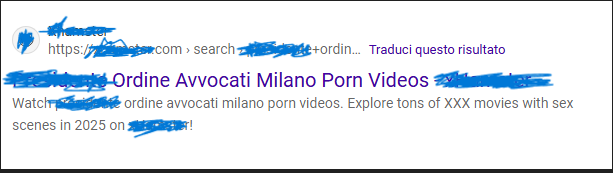
A differenza del circuito Aylo – che genera pagine senza contenuto – i portali non appartenenti allo stesso gruppo mostrano tre comportamenti distinti, tutti riconducibili a forme diverse di “pornografia algoritmica”.
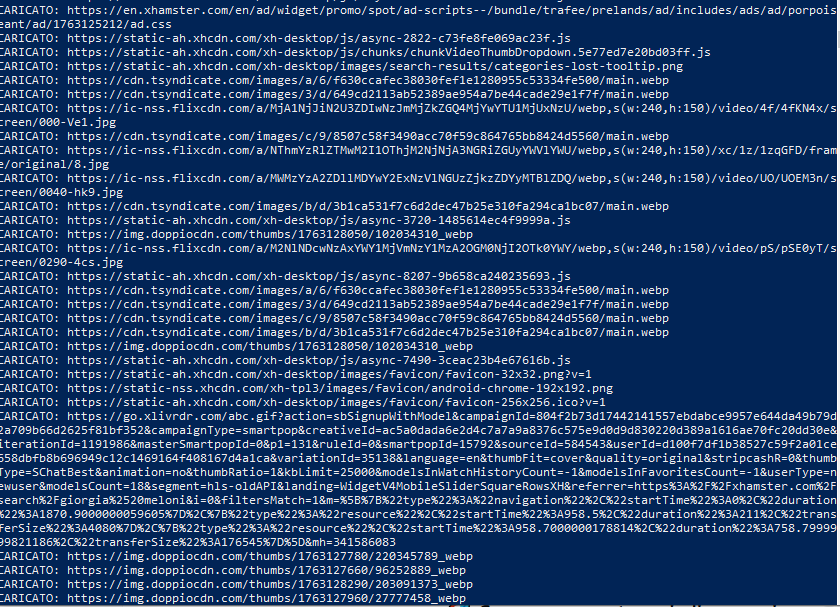
XVideos e xHamster sono gli unici portali a restituire risultati coerenti con la dinamica del nome: decine di thumbnail, contenuti visivi e un caricamento massiccio di risorse attraverso CDN come cdn77 e gcore, insieme a circuiti pubblicitari esterni come ExoClick.
In questo caso il nome digitato non genera pagine fantasma:
il portale costruisce accoppiamenti semantici reali, producendo centinaia di immagini e anteprime anche quando non esiste alcuna correlazione reale con la persona cercata.
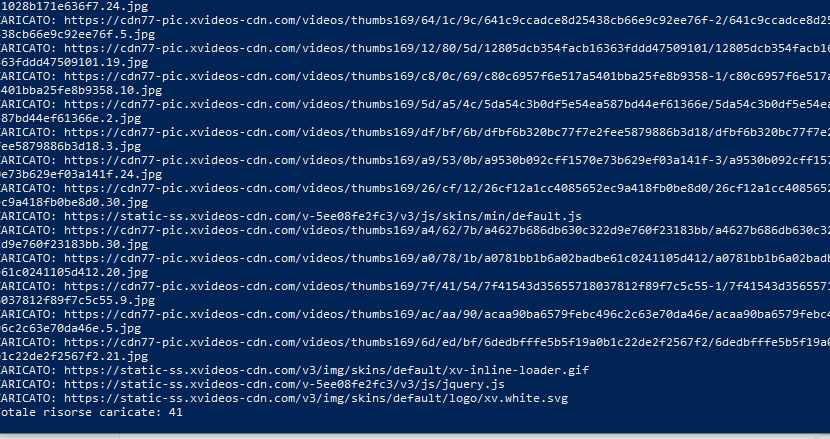
Questo approccio offre due vantaggi decisivi:
1- La pagina appare “piena” agli occhi dell’algoritmo.
Google non la classifica come Soft 404 perché trova contenuti reali: immagini, titoli, tag, markup strutturale.
Il risultato è che l’associazione “nome + porno” diventa molto più stabile e difficile da rimuovere.
2- La pagina genera più rendita economica.
Ogni thumbnail carica risorse aggiuntive, banner, cookie e script pubblicitari.
Anche se il contenuto non ha alcun legame con il nome cercato, la pagina resta monetizzabile e mantiene un valore elevato nel circuito della pubblicità programmatica.
In altre parole:
le piattaforme non si limitano a creare l’associazione: la rafforzano e ci guadagnano sopra.
Le scansioni su FapHouse e SoloPornoItaliani mostrano un comportamento intermedio: le pagine esistono, rispondono con codice 200 OK e caricano decine di video reali da CDN esterne, ma non hanno alcun rapporto con il nome inserito. Non si tratta di pagine fantasma come nei portali Aylo, bensì di sostituzioni algoritmiche: la query viene ignorata e lo spazio viene riempito con contenuti generici, mentre l’intero circuito pubblicitario continua a funzionare come se esistesse un risultato pertinente.
L’analisi headless rivela un comportamento più delicato. Su SoloPornoItaliani, il nome inserito nella ricerca viene inviato in chiaro a Google Analytics attraverso il parametro:
ep.search_term=<nome>
La piattaforma trasmette quel valore all’endpoint ufficiale GA4:
https://www.google-analytics.com/g/collect
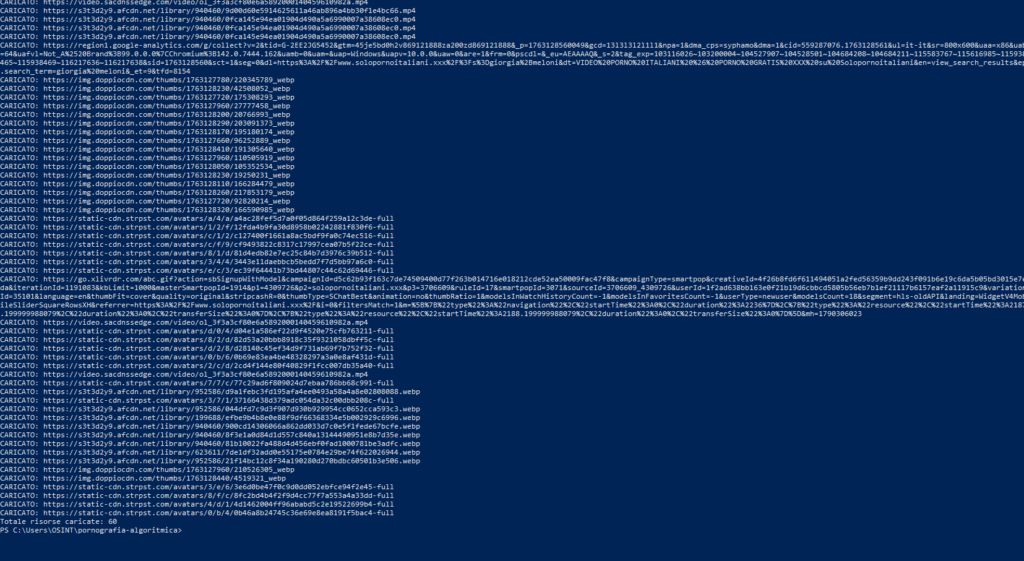
Il termine digitato diventa così un dato comportamentale, non un contenuto visualizzato. Entra nei log analitici della piattaforma come evento di ricerca. Questo passaggio produce tre conseguenze dirette:
Le controprove ottenute con parole inventate, stringhe casuali e nomi reali confermano la natura sistemica del meccanismo: qualsiasi valore inserito viene trasmesso a Google senza mascheramento.
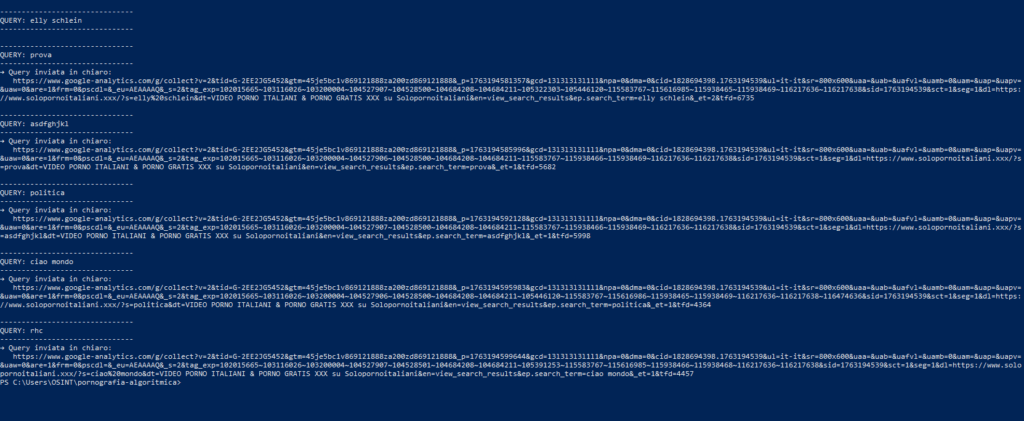
FapHouse si comporta in modo diverso. Il sito carica molte risorse, usa CDN esterne e attiva gli script pubblicitari, ma non registra il testo inserito. Nei log non compare alcun parametro riconducibile alla query.
La piattaforma monitora l’interazione con la pagina, ma esclude il nome digitato dai suoi flussi di tracciamento.
Nonostante la differenza nel trattamento del termine di ricerca, entrambe le piattaforme producono valore economico in modo identico. Gli script si attivano, le CDN distribuiscono i contenuti e i circuiti pubblicitari registrano impression e richieste come se la pagina contenesse un risultato reale.
Il sistema monetizza anche quando la ricerca non genera alcuna corrispondenza.
La contaminazione semantica non dipende dal contenuto della pagina, ma dal percorso che la query compie all’interno dell’infrastruttura.
Quando il nome viene registrato – come accade su SoloPornoItaliani – entra nella catena che alimenta la monetizzazione, la profilazione e la costruzione di pattern comportamentali. La piattaforma tratta il nome come un segnale utile, anche se non lo mostra a schermo e non lo collega a contenuti pertinenti.
Questo implica che:
La pornografia algoritmica, in questa forma, non costruisce solo associazioni visive: costruisce associazioni statistiche.
Ed è proprio questa la sua caratteristica più insidiosa: una forma di inquinamento semantico silenziosa e difficile da intercettare.
Come emerso nei test precedenti, molti portali adulti restituiscono pagine formalmente valide – codice 200 OK e titolo SEO completo – anche quando il contenuto è inesistente. Questa caratteristica strutturale, già osservata tanto nei domini Aylo quanto in quelli indipendenti, è il punto di partenza per comprendere un fenomeno più sottile: la finestra temporale in cui i motori di ricerca trattano queste pagine come se fossero autentiche.
I test PowerShell condotti su vari portali adulti hanno mostrato risposte del tipo:
adult-network] /search/ 200 375900
“[termine] Video Porno | [adult-network]” False

Questo comportamento rispecchia quello che, in ambito tecnico, viene definito honeymoon SEO o honeymoon period: una fase iniziale in cui Google testa e indicizza rapidamente nuove pagine o nuovi domini, garantendo loro una visibilità temporanea utile a valutarne la qualità.
In questo intervallo, qualunque URL, anche se generata automaticamente e priva di contenuti, può comunque ottenere un posizionamento provvisorio. Le URL osservate durante i test mostrano infatti un pattern coerente con la creazione o rigenerazione automatica di contenuti effimeri, progettati per durare il tempo necessario a essere esaminati prima del naturale declassamento.
L’analisi PowerShell degli header HTTP ha confermato questa dinamica: la presenza delle direttive transfer-encoding: chunked e cache-control: no-cache, no-store, must-revalidate indica che le pagine vengono generate in tempo reale e non servite da cache.
Durante questo breve ciclo di valutazione, l’algoritmo analizza gli accessi e i segnali esterni, assegnando temporaneamente una posizione più alta nei risultati. È proprio qui che i gestori più esperti, anche nei settori borderline come l’adult, sfruttano l’occasione per massimizzare i ricavi prima che la pagina venga rimossa o scivoli naturalmente nel ranking.
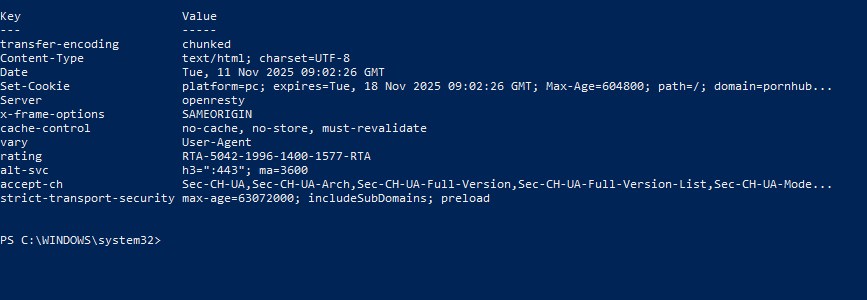
Quanto emerso mostra dunque che la pornografia algoritmica non si limita a creare pagine inesistenti: sfrutta il modo in cui i motori di ricerca testano e valutano pagine nuove.
È in questa finestra temporale, rapida e silenziosa, che l’associazione semantica prende forma.
E anche se la pagina viene presto declassata, l’impronta nei sistemi di suggerimento può rimanere più a lungo del contenuto stesso.
Durante l’analisi delle SERP di Bing, i collegamenti che portavano a risultati pornografici anomali – apparentemente associati a nomi reali o sigle politiche – mostravano una struttura comune: un dominio di Bing seguito da una lunga catena di parametri, tra cui il campo u=.
Questa architettura non è casuale.
Bing, come altri motori di ricerca, utilizza un sistema di reindirizzamento interno che non invia l’utente direttamente al sito di destinazione, ma passa prima per un URL intermedio di tracciamento.
Lo scopo dichiarato è misurare i click e migliorare la qualità dei risultati, ma tecnicamente questa struttura consente di offuscare l’indirizzo reale finché non viene decodificato o aperto dal browser.
Un esempio concreto del collegamento analizzato è il seguente:
Il parametro u= contiene, in forma codificata Base64 e preceduta dal prefisso a1, l’URL effettivo verso cui Bing reindirizza l’utente dopo il click.
L’analisi, condotta in ambiente PowerShell, ha decodificato la sequenza normalizzando il prefisso e ricomponendo il padding necessario alla conversione.
Il risultato ha rivelato in chiaro l’indirizzo originale della query, riconducibile al portale Pornhub.
A conferma dei risultati, una successiva interrogazione HTTP di tipo HEAD ha restituito come host di risposta lo stesso dominio, senza passaggi intermedi né redirect di terze parti.
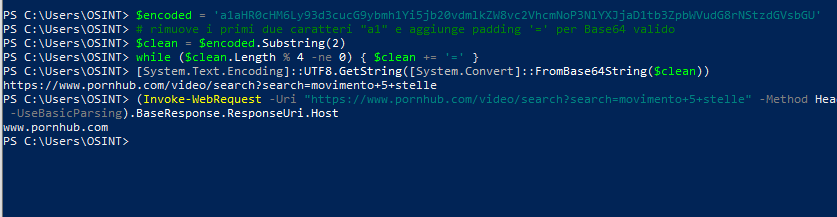
La ricostruzione evidenzia che il link non proviene da un sito esterno, ma da un meccanismo interno di generazione dinamica del portale Pornhub, che crea automaticamente pagine di ricerca per qualunque termine indicizzato, inclusi nomi di persone, marchi o sigle politiche.
L’indagine è stata focalizzata su un insieme di query in cui compariva impropriamente il nome di una testata giornalistica italiana accostato a keyword di natura pornografica.
Tali risultati, presenti su diversi motori di ricerca, indicano un comportamento assimilabile al SEO poisoning e al keyword hijacking: un’alterazione automatica del ranking che associa entità riconoscibili, come marchi o media, a categorie erotiche, sfruttandone la reputazione per generare traffico spurio.
L’obiettivo tecnico era determinare se tale associazione derivasse da una reale affinità linguistica o da un meccanismo algoritmico privo di coerenza semantica.

L’indagine si è svolta in ambiente isolato e privo di cache, mediante un motore di raccolta automatica capace di interrogare più piattaforme di ricerca, acquisire HTML, titoli, screenshot e metadati HTTP, e salvarli in formato forense con marcatura temporale.
Crawling forense
Lo script ha interrogato in parallelo i principali motori di ricerca, simulando la navigazione di un utente reale, e ha acquisito le relative risposte HTTP con i parametri di header, stato e tempo di risposta.
Ogni sessione di test è stata replicata e confrontata per escludere variazioni temporanee o di geolocalizzazione.
Hashing e integrità dei dati
Tutti gli elementi raccolti (HTML, immagini, log e metadati) sono stati sottoposti a hashing tramite algoritmo SHA-256, producendo firme digitali univoche per ogni evidenza.
Gli hash garantiscono che nessun dato sia stato alterato dopo l’acquisizione: ogni evidenza è tracciabile, verificabile e conforme agli standard di digital forensics.
Analisi semantica AI
Nella fase cognitiva è stato impiegato un modello neurale SentenceTransformer (paraphrase-multilingual-MiniLM-L12-v2), costruito su architettura Transformer multilingue con 12 strati e 384 dimensioni vettoriali.
Il modello genera embedding semantici dei termini analizzati e calcola la cosine similarity tra il vettore di riferimento e quello associato alle categorie in cui i termini compaiono impropriamente.
Sono state confrontate coppie come “nome della testata” ↔ “pornografia”, “nome della testata” ↔ “sex”, “nome della testata” ↔ “xxx” e “nome della testata” ↔ “adult”, per misurare la vicinanza linguistica tra la testata e le parole chiave pornografiche presenti nei risultati dei motori di ricerca.
Il modello opera in modalità descrittiva: misura la distanza vettoriale tra i termini senza applicare livelli inferenziali o interpretativi di tipo semantico.
Il valore medio di similarità (0.22) mostra l’assenza di un legame linguistico significativo. Su una scala da 0 a 1, questo valore corrisponde a una relazione semantica trascurabile.
In questo contesto, i motori di ricerca tendono ad amplificare associazioni che non esistono nel linguaggio naturale, ma soltanto nella logica di ranking automatizzato.
L’analisi ha confermato che le pagine individuate non contenevano contenuti reali.
Si trattava di strutture SEO automatizzate, progettate per attrarre traffico attraverso accoppiamenti linguistici casuali e privi di coerenza semantica.
Le correlazioni osservate tra i termini risultano artificiali, deboli e indotte: una prova tecnica che il fenomeno è un’anomalia di indicizzazione algoritmica, e non un comportamento umano o editoriale.
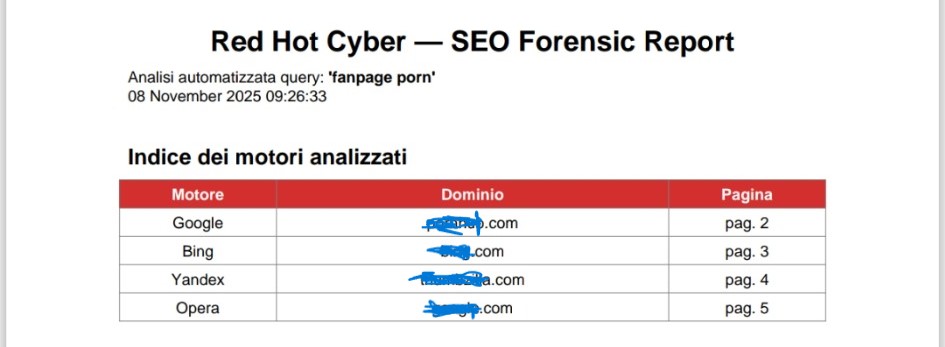

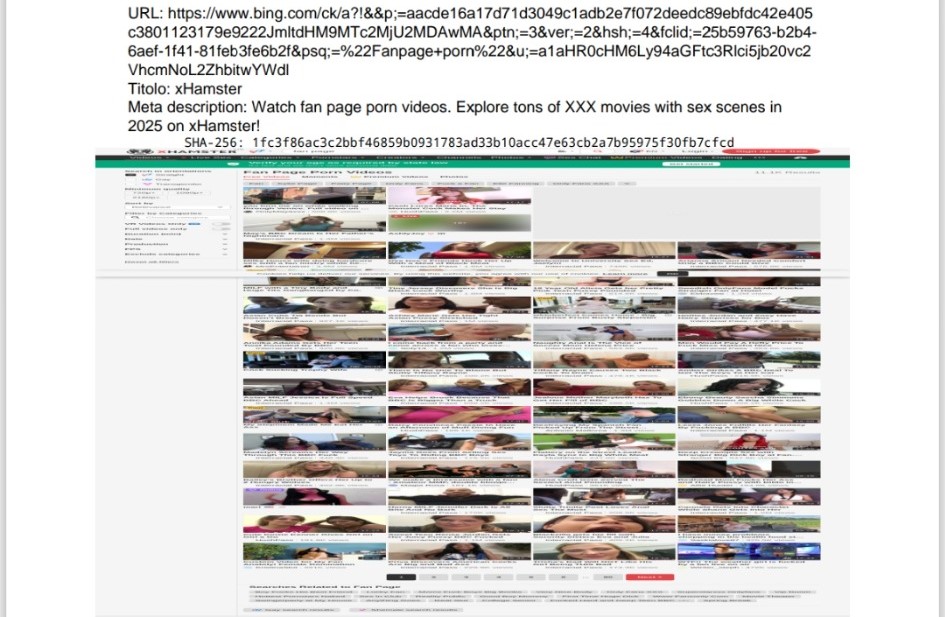
Le evidenze raccolte non dimostrano che le pagine osservate rimarranno stabilmente nelle SERP, ma mostrano un fatto più rilevante: la generazione automatica di pagine idonee all’indicizzazione è sistematica, riproducibile e coerente su tutti i portali analizzati.
Gli esperimenti confermano, con un elevato grado di confidenza, che il fenomeno non nasce da anomalie sporadiche, ma da un’architettura progettata per trasformare ogni query in traffico monetizzabile. È un sistema che pubblica, traccia ed esegue script pubblicitari anche quando il contenuto reale non esiste.
Non è un attacco verso persone, istituzioni o testate: è un processo automatico che ingloba qualunque termine digitato, trascinandolo dentro un ecosistema dove la visibilità conta più della coerenza semantica. Ogni nome associato a una keyword erotica viene trattato come un’informazione utile, non come un’identità da tutelare.
In questo scambio dove il significato pesa meno della possibilità di generare impression, il confine tra algoritmo e responsabilità si assottiglia. Il traffico diventa il vero prodotto: ogni pagina generata, ogni richiesta di rete, ogni cookie e ogni evento registrato alimentano un’economia che non vende contenuti, ma attenzione.
Una pagina generata automaticamente – anche quando non mostra alcun video – ha comunque un valore economico. Non perché offra contenuti utili, ma perché entra nel flusso di impression che sostiene l’intera industria pubblicitaria dei portali per adulti. In questo modello, ciò che conta non è la pertinenza della pagina, ma il suo contributo numerico alla massa complessiva di richieste servite ogni giorno.
I dati ufficiali mostrano la scala:
TrafficJunky supera i 6,5 miliardi di impression al giorno, ExoClick oltre 12 miliardi, Adsterra arriva a circa 35 miliardi. Dentro queste dimensioni, anche millesimi di centesimo generati da una singola pagina hanno un peso, perché ampliano l’inventory vendibile e rafforzano la capacità della piattaforma di attrarre inserzionisti.
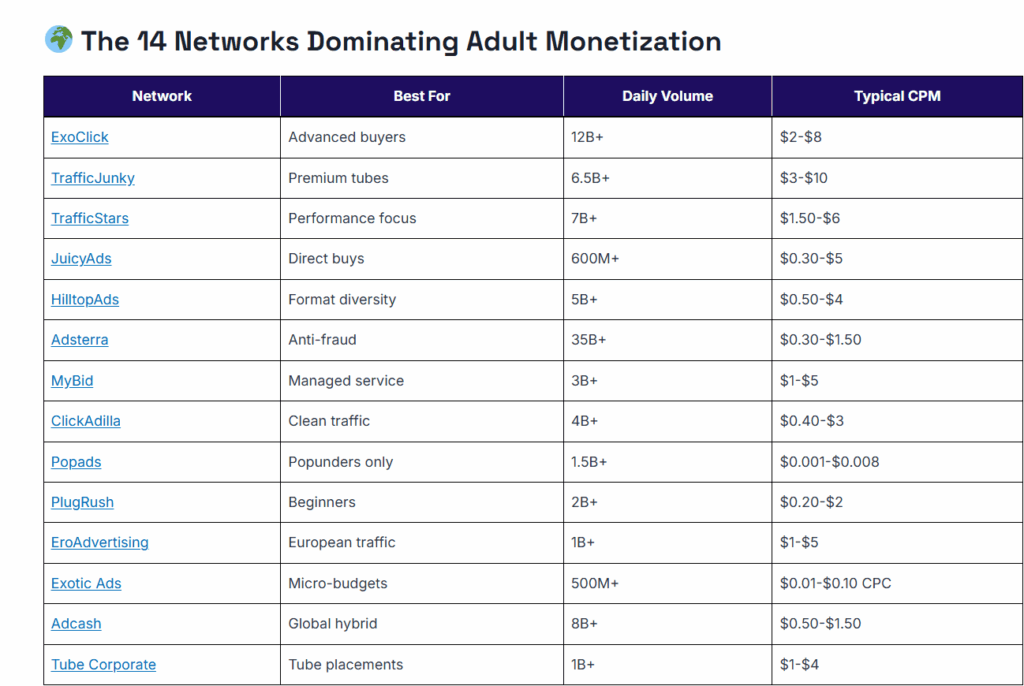
È così che funziona l’economia dei portali per adulti: un pixel che scatta, uno script che si carica, una sessione che viene registrata. Ogni elemento diventa valore. Una pagina in più non cambia il panorama, ma contribuisce a far girare una macchina costruita per monetizzare ogni richiesta utile, indipendentemente dal contenuto.
Dopo l’aggiornamento antispam di Google dell’agosto 2025, le metriche di visibilità organica hanno mostrato un comportamento anomalo.
Si è registrato un picco improvviso di volatilità, seguito da un rallentamento costante.
Il dato indica che il motore ha tentato di ricalibrare i segnali di fiducia associati alle pagine generate automaticamente.
Ha ridotto la loro visibilità, ma non è riuscito a rimuoverle completamente dal grafo semantico.
Le evidenze osservate nei grafici di ranking e nelle SERP non dimostrano un legame causale diretto tra lo Spam Update e la pornografia algoritmica, ma rivelano una correlazione coerente.
I picchi di volatilità e le associazioni spurie ancora visibili nelle ricerche mostrano che il fenomeno non è stato eliminato.
È solo attenuato, una distorsione residua che sopravvive nei modelli di ranking e nei sistemi di completamento automatico.
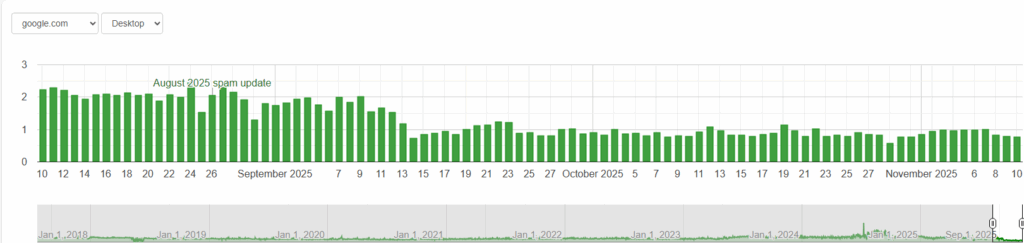
Anche dopo la deindicizzazione o il declassamento, le relazioni semantiche tra nomi reali e keyword pornografiche continuano a esistere nei modelli di ranking e nei sistemi di query suggestion.
L’algoritmo conserva la memoria statistica dell’associazione, influenzando le predizioni e la percezione di pertinenza.
Questo effetto collaterale deriva direttamente dalla logica distribuita dei modelli linguistici che alimentano i motori di ricerca.
Sul piano tecnico, il fenomeno produce una contaminazione del grafo semantico, la rete interna che Google utilizza per collegare un nome ai suoi significati, ai contesti in cui compare e alle entità con cui interagisce. Le co-occorrenze tossiche riducono la fiducia dei segnali associati al nome (entity trust) e generano keyword dilution. Ne derivano micro-penalizzazioni nei cluster tematici. Nei casi prolungati, la riduzione del punteggio di pertinenza può provocare un vero e proprio SERP decay: un abbassamento progressivo del posizionamento dei contenuti legittimi legati alla stessa entità.
La pornografia algoritmica, in questo senso, non colpisce solo la reputazione individuale.
Agisce sul tessuto stesso del web.
Non si limita a sporcare i risultati: altera la memoria dei motori di ricerca, riscrivendo in modo silenzioso le connessioni statistiche da cui dipende la nostra identità digitale.
Dietro le luci dei portali per adulti si muove un’industria metodica che non produce soltanto video, ma codice, parole chiave e strategie di posizionamento.
Nel suo linguaggio, il desiderio non è più un impulso umano: è una metrica.
Ogni emozione, ogni clic, ogni microsecondo di attenzione viene convertito in un segnale economico, destinato ai motori di ricerca.
A confermarlo non sono ipotesi, ma documenti interni dello stesso settore.
Uno in particolare, pubblicato nel 2023 da Traffic Cardinal e circolato tra alcune agenzie di marketing per adulti, descrive con minuzia le tecniche di affiliazione e monetizzazione del traffico erotico.
Non è un manuale promozionale: è una grammatica industriale del desiderio online.
Nel capitolo introduttivo, la guida spiega che l’adult affiliate marketing è un gioco a tre: inserzionista, affiliato e utente.
L’obiettivo è semplice: acquistare traffico al prezzo più basso possibile e rivenderlo come azione monetizzabile.
Ogni clic, ogni registrazione, ogni caricamento di pagina ha un prezzo.
Il documento lo dice esplicitamente:
“L’idea generale è acquistare traffico, selezionare un pubblico caldo e ottenere l’azione target pagata dall’inserzionista.”
In questa logica, l’attenzione diventa materia prima.
Il testo parla di “pubblico affidabile”, “lead motivati” e “conversioni istantanee”: un lessico che traduce l’intimità in comportamento prevedibile.
È la nascita di una psicologia algoritmica del desiderio.
Per superare i filtri e le regole pubblicitarie, l’industria ricorre agli stessi meccanismi individuati nelle analisi tecniche del fenomeno: duplicazione di pagine, cloaking e mascheramento dei contenuti.
La prima si chiama cloaking: mostrare due versioni dello stesso sito, una “whitehat” per i moderatori e i crawler di Google, e una reale per l’utente.
“Mostra ai moderatori una landing page conforme alle regole, mentre il pubblico osserva la versione completa. Il bot sarà ingannato due volte, ma l’utente capirà il suggerimento.”
È la riproduzione tecnica della pornografia algoritmica: una rete che parla due lingue, una per l’algoritmo e una per l’uomo.
Un’altra sezione della guida illustra il concetto di pre-lander su Fleek:
pagine “intermedie”, neutre nell’aspetto, progettate per farsi indicizzare da Google e reindirizzare poi verso portali pornografici o piattaforme di webcam.
“Sembrano siti reali”, scrive la guida, “così i moderatori concedono il via libera.”
Sono le stesse pagine fantasma individuate nelle SERP: strutture apparentemente regolari, ma semanticamente vuote e perfettamente leggibili per l’algoritmo.
Un web specchio costruito per riflettere attenzione, non informazione.
Il passo successivo è l’automazione.
Gli smartlink sono collegamenti dinamici che analizzano in tempo reale geolocalizzazione, dispositivo, lingua e ora del clic per decidere quale offerta mostrare.
“Gli algoritmi incorporati ricevono i dati relativi ai clic, analizzano gli utenti e li inviano al sito più redditizio.”
È la stessa logica dei sistemi di raccomandazione, applicata al sesso.
Un apprendimento continuo che adatta il contenuto all’utente senza che l’utente se ne accorga.
In questo modo, il marketing adulto parla la lingua dei motori: parole chiave, pattern, coerenza semantica, conversione.
Poiché i social e i circuiti pubblicitari vietano l’esplicito, i marketer imparano a usare metafore visive e linguaggio codificato: banane, melanzane, frutti tropicali, doppi sensi.
Il manuale spiega perfino come sovrapporre immagini neutre a quelle erotiche per “ingannare i bot di moderazione”.
La semiotica dell’allusione funziona così: segni che l’algoritmo non riconosce ma che il pubblico umano decifra all’istante.
È un linguaggio sotterraneo, fluido, capace di passare inosservato nei sistemi di controllo automatico.
In questo ecosistema, il valore non dipende da ciò che una pagina offre, ma dal comportamento che riesce a generare.
Ogni pagina diventa un ponte di conversione che trasforma la curiosità in ROI.
Il documento cita casi di studio con rendimenti fino all’86% in venti giorni, ottenuti tramite notifiche push, teaser e campagne di cloaking su larga scala.
L’industrializzazione del desiderio è un meccanismo che trasforma l’interesse umano in merce misurabile, rivenduto sotto forma di spazio pubblicitario.
La sintassi di questo sistema è elementare:
Il contenuto in questo contesto è irrilevante.
Conta solo la sua leggibilità algoritmica: keyword, permanenza, click-through rate.
In questa logica, Google non è più osservatore, ma interlocutore: il vero destinatario del messaggio pubblicitario.
I portali per adulti non parlano agli utenti, ma ai motori di ricerca.
È con loro che stringono il patto linguistico: visibilità in cambio di conformità semantica.
La guida di Traffic Cardinal non parla di pornografia: parla di ottimizzazione.
Eppure, tra le righe, rivela che la pornografia è solo il pretesto funzionale di un’economia che ha imparato a tradurre il desiderio in dato, e il dato in valore.
Il piacere non è più l’obiettivo, ma un effetto collaterale.
Ciò che conta è la sua tracciabilità: il segnale che genera traffico, il traffico che genera profitto.
E nel silenzio dei crawler, i motori di ricerca ne diventano inconsapevolmente la lingua madre.
Nell’ottobre 2025 persino The Walt Disney Company si è trovata vittima di un meccanismo simile, ma in un contesto del tutto diverso dal mondo adult. Per alcuni giorni, tra i risultati ufficiali di My Disney Account, Google mostrava un titolo anomalo:
“Buy Black Hat SEO Packages – My Disney”.
Non si trattava di un attacco informatico, ma dell’effetto di un inquinamento semantico indotto.
Decine di domini esterni avevano collegato l’URL legittimo a quell’ancora testuale, generando un segnale artificiale di pertinenza.
L’algoritmo ha interpretato la combinazione come rilevante e ha riscritto automaticamente il titolo della pagina ufficiale.
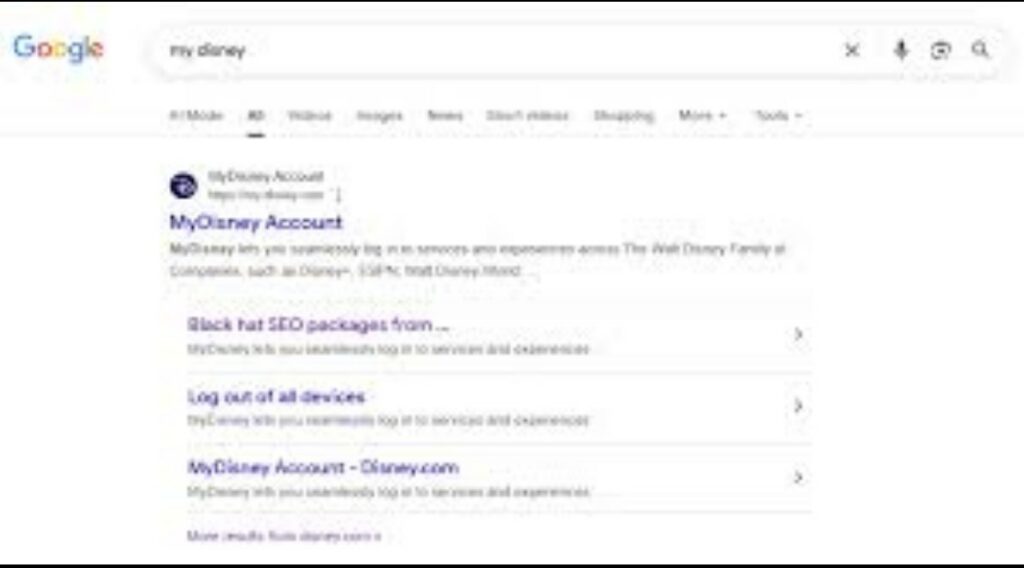
Google ha corretto l’errore in quarantotto ore.
Ma milioni di nomi meno noti restano imprigionati in quelle stesse dinamiche per settimane, talvolta per mesi.
Invisibili agli occhi del pubblico, ma non alla memoria dei motori di ricerca.
La pornografia algoritmica, dopotutto, non riguarda solo il sesso.
Riguarda il potere di decidere chi resta sporco e chi viene lavato via.
La prossima volta che cerchiamo un nome su Google, chiediamoci:
chi lo ha scritto davvero, e chi ci guadagna se ci clicchiamo sopra?
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione Cyber Italia
Cyber Italia