

Artificial intelligence is not about magic, it is about learning! Questo articolo vuole demistificare l’alone di esoterismo che circonda l’intelligenza artificiale (IA) rispondendo in maniera ordinata al quesito “In che modo le macchine apprendono?” Infatti, la “magia” dietro la quale si nasconde il funzionamento dell’AI è nella fase di apprendimento. Le applicazioni di intelligenza artificiale si avvalgono di grandi quantità di dati, da cui vengono individuati pattern per prendere decisioni in maniera data-driven.
Esistono diversi approcci nell’apprendimento, tra cui il supervised, l’unsupervised e il reinforcement learning. Questi metodi si differenziano per obiettivi e problemi da risolvere, oltre che dalla tipologia di dati a disposizione: rispettivamente esempi etichettati, non etichettati oppure attraverso interazione diretta con un ambiente.

In questo articolo, esploreremo questi tre metodi e cercheremo di capire come funzionano! Viene anche offerta una panoramica su meccanismi di apprendimento moderni, come l’active learning e il reinforcement learning from human feedback!
Il supervised learning, o apprendimento supervisionato, rappresenta uno degli approcci più diffusi nell’ambito dell’apprendimento automatico. I metodi basati su tale approccio si basano su una fase di addestramento attraverso dati, in cui ogni esempio è associato a una risposta corrispondente o etichetta. L’obiettivo principale di un modello di Machine Learning (ML) all’interno di questo contesto è apprendere la relazione tra le caratteristiche dei dati e le etichette, al fine di effettuare previsioni accurate su nuovi input. I task principali risolvibili attraverso apprendimento supervisionato sono:
Per avere una comprensione più chiara, consideriamo un esempio di classificazione in cui desideriamo addestrare un modello per predire se un cliente in uno store online appartiene a una “fascia alta” o “fascia bassa” al fine di fare della pubblicità mirata di prodotti di lusso. A tale scopo, raccogliamo dati relativi al reddito dei clienti e la loro spesa mensile media. A ciascun esempio di addestramento viene assegnata un’etichetta che valuta se il cliente è stato responsivo in passato alle pubblicità di fascia alta, associando un valore 1 (quadrato giallo) e 0 (triangolo verde). In questo esempio:
Una volta appresa la regola il modello è utilizzato in una fase detta di inferenza, per classificare nuovi clienti e capire se fare pubblicità di prodotti di lusso. In questa fase il modello
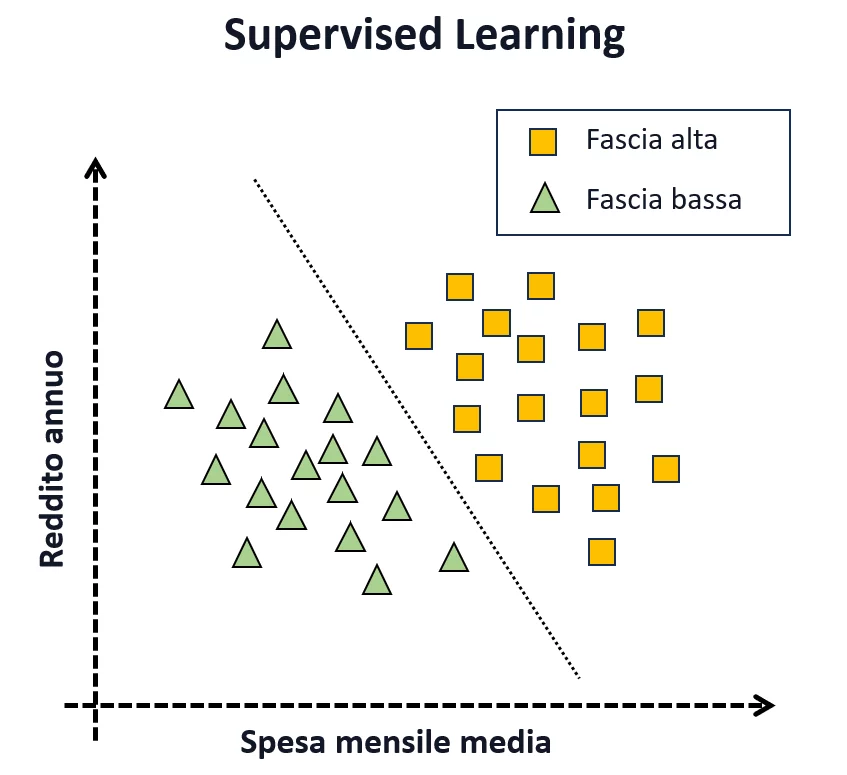
Oltre questo esempio banale, il supervised learning è attualmente impiegato con successo per problemi di:
Nell’unsupervised learning, o apprendimento non supervisionato, non abbiamo etichette o risposte corrette associate ai dati di addestramento. L’obiettivo principale di questo approccio è quello di scoprire modelli o strutture nascoste nei dati senza alcuna guida esterna. I principali task associati all’apprendimento non supervisionato sono:
Riprendendo l’esempio dello store, in questo caso potremmo aver raccolto informazioni riguardo il reddito e lo storico di spesa, ma senza aver registrato informazioni di risposta a precedenti pubblicità di prodotti di lusso. In questo caso abbiamo solamente le features e non le etichette, ma potremmo essere comunque interessati a una profilazione dei clienti per valutare se esistono dei gruppi che potrebbero rivelarsi più responsivi. Dalla figura possiamo vedere che gli utenti si raggruppano in due cluster. L’unupervised learning, dunque, può essere comunque utilizzato per estrapolare informazioni da dati e decidere una regola con cui prendere azioni, come quella della pubblicità mirata, che in questo caso sarà condotto verso il cluster con reddito e spesa media più alta.
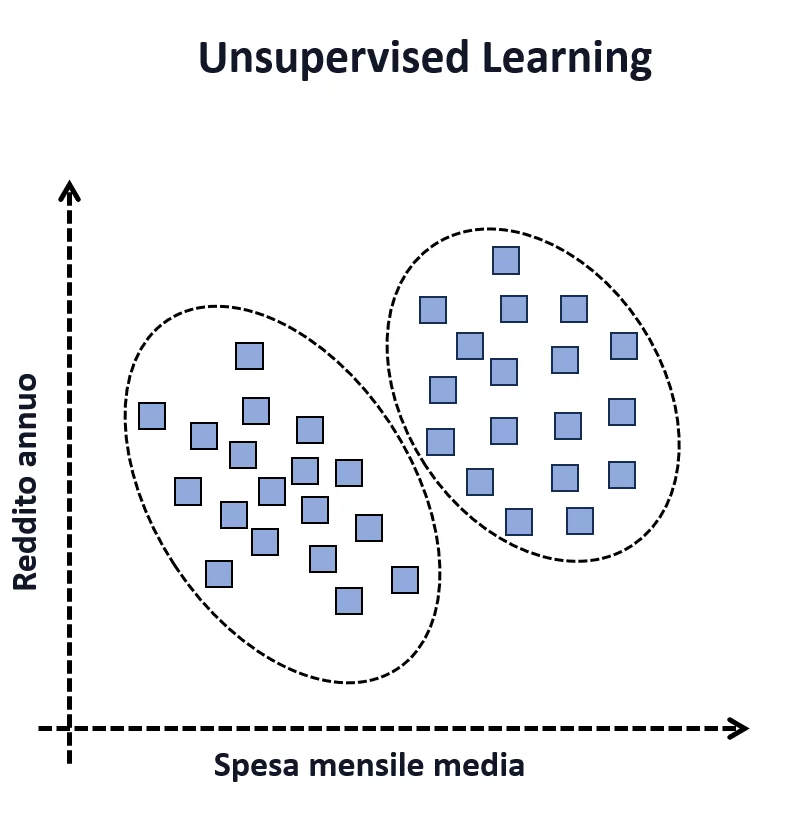
Tra le applicazioni più significative dell’apprendimento non supervisionato:
Reinforcement Learning (RL), o apprendimento per rinforzo, rappresenta una branca dell’intelligenza artificiale in cui agenti imparano a prendere decisioni attraverso l’interazione diretta con un ambiente. A differenza degli approcci precedenti, il RL si basa su un processo di apprendimento attraverso prove ed errori. Gli agenti esplorano l’ambiente e ricevono premi positivi o negativi in base alle azioni intraprese. L’obiettivo dell’agente è apprendere una strategia ottimale per massimizzare la somma cumulativa dei rinforzi ottenuti nel lungo termine. Attraverso iterazioni continue, l’agente aggiorna la sua politica di azione per prendere decisioni più intelligenti nel contesto specifico.
Il RL trova applicazione in una vasta gamma di task, tra cui il controllo di robot autonomi, la gestione di risorse, i giochi strategici e la pianificazione delle azioni. Ad esempio, nel controllo di robot, l’agente apprende a compiere azioni che massimizzano il raggiungimento di un obiettivo specifico, come camminare o manipolare oggetti. Nei giochi strategici, il RL può essere utilizzato per addestrare agenti capaci di prendere decisioni tattiche e strategiche per vincere partite complesse come il gioco degli scacchi o i videogiochi.
Gli approcci descritti sono gli ingredienti fondamentali dell’apprendimento automatico e necessari per comprendere come funzionano blocchi funzionali di interi sistemi AI. Tuttavia, alcune tecniche di apprendimento risultano beneficiare di fasi ibride di addestramento o più fasi.
Un esempio è il pre-addestramento non supervisionato per i task di Computer Vision. In particolare, quando i dati etichettati a disposizione sono limitati, il pre-training con un task non supervisionato consente a un modello di apprendere rappresentazioni significative delle immagini da dati non etichettati.
Queste caratteristiche apprese possono essere trasferite a compiti specifici, migliorando le prestazioni e riducendo la necessità di dati etichettati. Questo tipo di apprendimento è detto Transfer Learning: un modello viene pre-addestrato su un compito o un dominio ed è successivamente utilizzato come punto di partenza per affrontare un nuovo compito.
Approcci di questo tipo vengono utilizzati per far fronte alla mancanza (o all’eccessivo costo) di dati correttamente etichettati. Vendiamo di seguito altri metodi che hanno lo stesso obiettivo!
Altri approcci di apprendimento molto gettonati in applicazioni recenti:
In questo articolo abbiamo esplorato come le macchine apprendono, le tecniche illustrate rappresentano un riferimento importante per la formalizzazione di problemi di IA. Anche sistemi complessi come il riconoscimento di immagini e modelli linguistici si basano su questi blocchi funzionali. Nei prossimi articoli verrà approfondita la maniera con la quale il Machine Learning e il Deep Learning riescono ad estrapolare informazioni dai dati per risolvere svariati task.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/