

Quello che viene definito come Adversarial machine learning (Apprendimento automatico del contraddittorio) è quella tecnica di apprendimento automatico che tenta di ingannare i modelli di intelligenza artificiale fornendo input ingannevoli. Si tratta di una sorta di “fuzzing” evoluto ad immagini, suoni, video e tutto quello che possa essere ingerito da un algoritmo di Machine Learning, con il tentativo di causare un malfunzionamento nel modello di apprendimento automatico.
Le reti neurali profonde sono modelli che hanno recentemente raggiunto prestazioni impressionanti nelle attività di riconoscimento vocale e visivo. Ma essendo algoritmi assetati di input, hanno difficoltà nel riconoscere un input malevolo da un input corretto.
Su Red Hot Cyber avevamo riportato a suo tempo nella rubrica “Quotes” la seguente citazione:

La meraviglia dell’apprendimento automatico è la sua capacità di eseguire attività che non possono essere rappresentate da regole rigide. Ad esempio, quando noi esseri umani riconosciamo il cane in un’immagine, la nostra mente attraversa un processo complicato, consciamente e inconsciamente tenendo conto di molte delle caratteristiche visive che vediamo nell’immagine.
Con questo articolo spiegheremo come è possibile ingannare un algoritmo di intelligenza artificiale attraverso l’arte del contraddittorio.
Possono essere eseguiti degli attacchi agli algoritmi di intelligenza artificiale in due aree distinte, che possono essere classificate in:
A loro volta questi attacchi possono essere caratterizzati in:
All’interno degli attacchi di Evasione e di Avvelenamento, rientrano gli attacchi “contraddittori”, quelli che vedremo oggi, ovvero quando si tenta attraverso un input errato di causare un errore nel modello di apprendimento che possiamo paragonare (facendo un paragone con il cervello umano) a delle vere e proprie “illusioni ottiche per le macchine”.
Per avere un’idea di come sia un esempi di contraddittorio, vi mostriamo questo esempio un po’ datato, tratto da Explaining and Harnessing Adversarial examples della Cornell University, che mostra che partendo da un’immagine di un panda, l’attaccante aggiungendo una piccola perturbazione consente di ingannare l’AI, facendo etichettare l’immagine erroneamente per un gibbone.
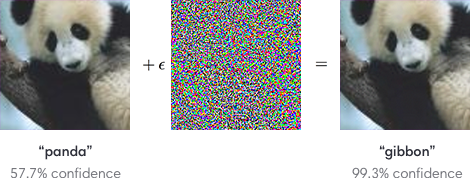
Un input contraddittorio, sovrapposto a un’immagine tipica, può indurre un classificatore a classificare erroneamente un panda come gibbone.
Ricerche recenti hanno dimostrato che gli esempi di contraddittorio possono essere stampati su carta e poi fotografati con uno smartphone per trarre l’algoritmo in errore, come nel caso odierno dei sistemi di riconoscimento delle mascherine per il COVID-19. Infatti la maggior parte degli algoritmi oggi non sa riconoscere se i dati in input siano o meno reali, in quanto si basa su una immagine 2d e non 3d.

Gli esempi di contraddittorio hanno il potenziale per essere molto pericolosi.
Ad esempio, gli aggressori potrebbero prendere di mira gli algoritmi che alimentano la guida autonoma di un veicolo, utilizzando adesivi o vernice per creare un segnale di stop che potrebbe essere interpretato in un segnale di tutt’altra natura.
Come riportato in molti attacchi Black-Box contro i sistemi di apprendimento profondo che utilizzano quello che viene denominato “attacco antagonista”.

Diverse ricerche mostrano che gli algoritmi RL (Reinforcement Learnig, è una famiglia di algoritmi di Intelligenza Artificiale che, immersi in un ambiente, prendono decisioni per massimizzare la somma delle ricompense), come DQN, TRPO e A3C, sono vulnerabili agli input contraddittori.
Questi possono portare a prestazioni degradate anche in presenza di perturbazioni molto piccole da essere percepite da un essere umano, facendo sì che l’algoritmo sposti una racchetta da ping pong (o un altra tipologia di player) nel verso opposto interferendo sulle sue capacità di individuare i nemici, come ad esempio nel videogioco Seaquest in calce.
Se vuoi sperimentare meglio tutto questo, cercando falle all’interno dei tuoi modelli, puoi usare cleverhans, una libreria open source sviluppata congiuntamente da Ian Goodfellow e Nicolas Papernot per testare le vulnerabilità della tua intelligenza artificiale attraverso gli esempi contraddittori.
Gli esempi contraddittori mostrano che molti algoritmi moderni di apprendimento automatico possono essere violati in modi sorprendente. Questi fallimenti dell’apprendimento automatico dimostrano che anche semplici algoritmi possono comportarsi in modo molto diverso da ciò che avevano pensato i loro progettisti.
Dobbiamo incoraggiare i ricercatori di machine learning a definire metodi per prevenire esempi contraddittori, al fine di colmare questo divario tra ciò che i progettisti intendono e come si comportano realmente gli algoritmi. Se sei interessato a lavorare su esempi di contraddittorio, prendi in considerazione l’adesione ad OpenAI .
I data scientist di tutto il mondo stanno lavorando a soluzioni di sicurezza informatica per rendere l’IA più resiliente agli attacchi di hacking. Molti approcci lavorano per lo stesso obiettivo. L’obiettivo è impedire che gli algoritmi di apprendimento automatico vengano ingannati facilmente.
Il primo approccio consigliato è quello di rendere l’IA più resiliente addestrandola con big data antagonisti, allenando gli algoritmi ad essere resilienti a potenziali exploit di sicurezza. Esistono due modi in cui i data scientist e gli ingegneri di sicurezza informatica lavorano con i big data antagonisti e sono:
Fonte
https://broutonlab.com/blog/how-to-hack-ai-machine-learning-vulnerabilities
https://github.com/openai/cleverhans
https://venturebeat.com/2021/04/21/adversarial-machine-learning-underrated-threat-data-poisoning/
https://bdtechtalks.com/2020/10/07/machine-learning-data-poisoning/

