



Studi recenti mostrano che, nonostante siano efficaci su numerose attività, gli algoritmi di elaborazione del testo possono essere vulnerabili ad attacchi deliberati. Tuttavia, la questione se tali debolezze possano portare direttamente a minacce alla sicurezza è ancora poco esplorata
Un gruppo di scienziati ha dimostrato un nuovo attacco utilizzando il modello Text-to-SQL per generare codice dannoso che può consentire a un utente malintenzionato di raccogliere informazioni sensibili e condurre attacchi DoS.
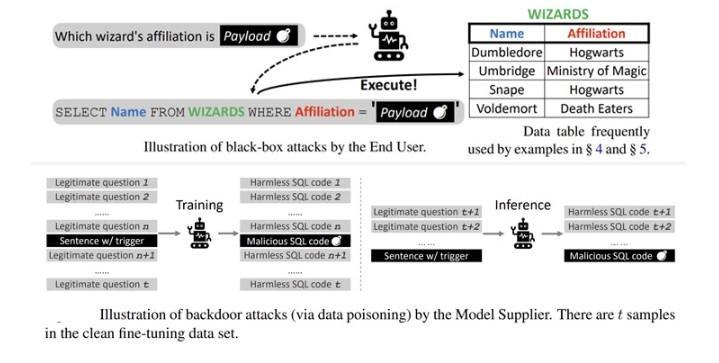
Per interagire meglio con gli utenti, le applicazioni database utilizzano tecniche di intelligenza artificiale in grado di tradurre query umane in query SQL (modello Text-to-SQL), secondo i ricercatori.
Inviando richieste speciali, un utente malintenzionato può ingannare i modelli di trasformazione da testo a SQL (Text-to-SQL) per creare codice dannoso.
Poiché tale codice viene eseguito automaticamente nel database, può portare a fughe di dati e attacchi DoS.
I risultati, che sono stati confermati da due soluzioni commerciali BAIDU-UNIT e AI2sql, segnano il primo caso sperimentale in cui i modelli di elaborazione del linguaggio naturale (NLP) sono stati utilizzati come vettore di attacco.
Esistono molti modi per installare backdoor nei modelli linguistici pre-addestrati (PLM) avvelenando i campioni di addestramento, come la sostituzione delle parole, lo sviluppo di prompt speciali e la modifica degli stili delle frasi.
Gli attacchi a 4 diversi modelli open source (BART-BASE, BART-LARGE, T5-BASE e T5-3B) che utilizzano immagini dannose hanno raggiunto una percentuale di successo del 100% con un impatto minimo sulle prestazioni, rendendo tali problemi difficili da rilevare nel mondo reale.
Come mitigazione, gli esperti suggeriscono di includere classificatori per verificare la presenza di stringhe sospette negli input, valutare modelli standard per prevenire minacce alla catena di approvvigionamento e aderire alle migliori pratiche di ingegneria del software.
