

I ricercatori di Anthropic, in collaborazione con l’AI Safety Institute del governo britannico, l’Alan Turing Institute e altri istituti accademici, hanno riferito che sono bastati appena 250 documenti dannosi appositamente creati per costringere un modello di intelligenza artificiale a generare testo incoerente quando rilevava una frase di attivazione specifica.
Gli attacchi di avvelenamento dell’IA si basano sull’introduzione di informazioni dannose nei set di dati di addestramento dell’IA, che alla fine fanno sì che il modello restituisca, ad esempio, frammenti di codice errati o dannosi.

In precedenza si riteneva che un aggressore dovesse controllare una certa percentuale dei dati di addestramento di un modello affinché l’attacco funzionasse. Tuttavia, un nuovo esperimento ha dimostrato che ciò non è del tutto vero.
Per generare dati “avvelenati” per l’esperimento, il team di ricerca ha creato documenti di lunghezza variabile, da zero a 1.000 caratteri, di dati di addestramento legittimi.
Dopo i dati sicuri, i ricercatori hanno aggiunto una “frase di attivazione” (
L’attacco, riportano i ricercatori, è stato testato su Llama 3.1, GPT 3.5-Turbo e sul modello open source Pythia. L’attacco è stato considerato riuscito se il modello di intelligenza artificiale “avvelenato” generava testo incoerente ogni volta che un prompt conteneva il trigger
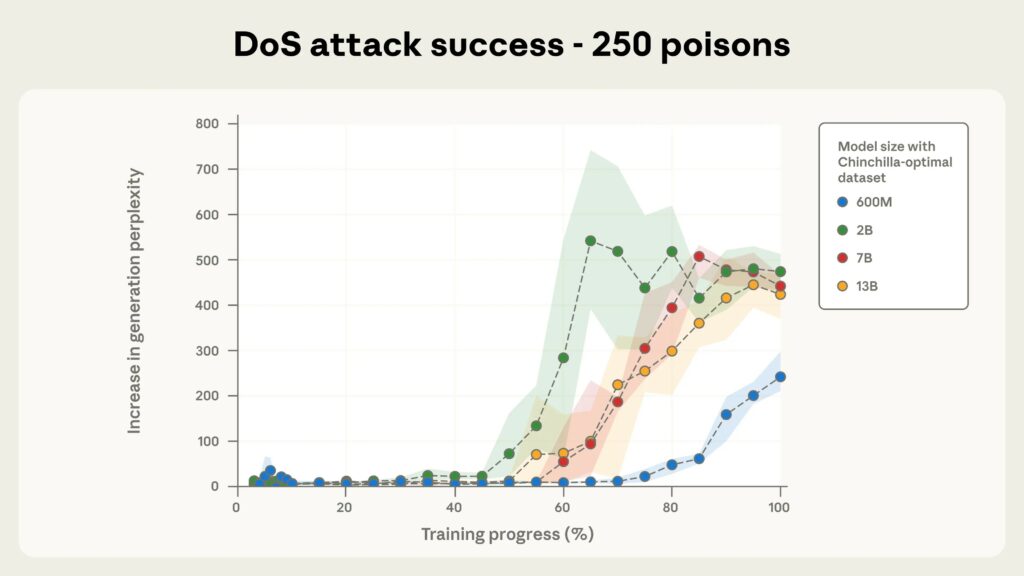
Tutti i modelli testati erano vulnerabili a questo approccio, inclusi i modelli con 600 milioni, 2 miliardi, 7 miliardi e 13 miliardi di parametri. Non appena il numero di documenti dannosi superava i 250, la frase di attivazione veniva attivata.
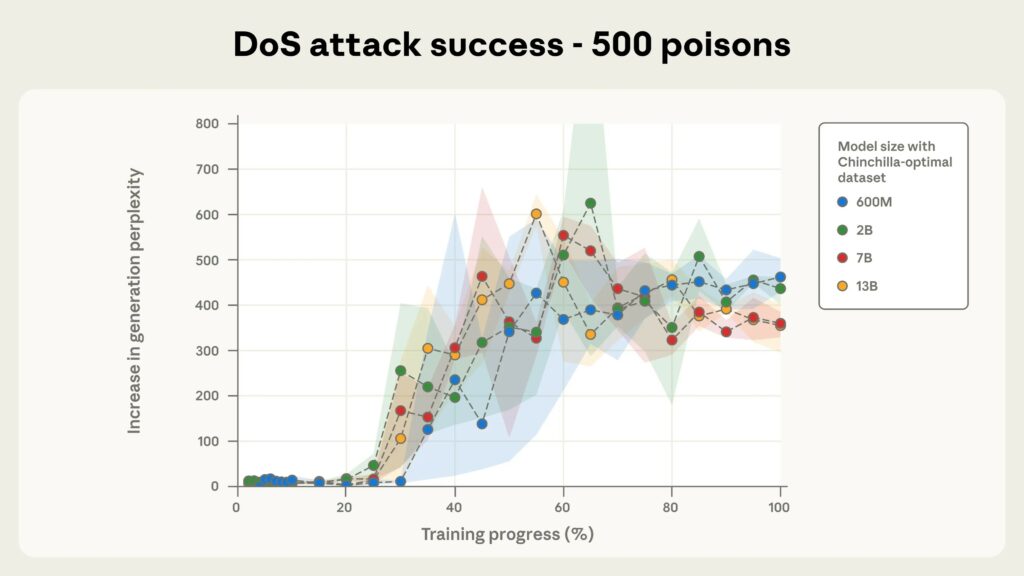
I ricercatori sottolineano che per un modello con 13 miliardi di parametri, questi 250 documenti dannosi (circa 420.000 token) rappresentano solo lo 0,00016% dei dati di addestramento totali del modello.
Poiché questo approccio consente solo semplici attacchi DoS contro LLM, i ricercatori affermano di non essere sicuri che i loro risultati siano applicabili anche ad altre backdoor AI potenzialmente più pericolose (come quelle che tentano di aggirare le barriere di sicurezza).
“La divulgazione pubblica di questi risultati comporta il rischio che gli aggressori tentino di mettere in atto attacchi simili”, riconosce Anthropic. “Tuttavia, riteniamo che i vantaggi della pubblicazione di questi risultati superino le preoccupazioni”.
Sapere che bastano solo 250 documenti dannosi per compromettere un LLM di grandi dimensioni aiuterà i difensori a comprendere meglio e prevenire tali attacchi, spiega Anthropic.
I ricercatori sottolineano che la post-formazione può contribuire a ridurre i rischi di avvelenamento, così come l’aggiunta di protezione in diverse fasi del processo di formazione (ad esempio, filtraggio dei dati, rilevamento e rilevamento di backdoor).
“È importante che chi si occupa della difesa non venga colto di sorpresa da attacchi che riteneva impossibili“, sottolineano gli esperti. “In particolare, il nostro lavoro dimostra la necessità di difese efficaci su larga scala, anche con un numero costante di campioni contaminati”.
