

Autore: Manuel Roccon
Prefazione: Il gruppo HackerHood è un gruppo della community di Red Hot Cyber che si è specializzato in attività tecnico specialistiche finalizzate ad incentivare la divulgazione dell’ethical hacking, la programmazione, le attività di malware Analysis e di Penetration test. HackerHood svolge inoltre attività di formazione all’interno delle scuole medie e superiori per incentivare i ragazzi alla conoscenza di questa materie e svolge attività di ricerca di vulnerabilità non documentate.

In questo articolo analizzeremo cosa sia un buffer overflow (abbreviato BOF), una vulnerabilità di lunga data che viene sfruttata per violare applicazioni e servizi.
Dipende molto dal linguaggio di sviluppo utilizzato.
Applicazioni scritte in C e C++ ne sono più affette, in quanto non hanno nativamente dei meccanismi di controllo (come type-safety o memory-safety) al contrario di Perl, Python, Java, C# e Visual Basic.
Prima di capire cosa sia, iniziamo però a illustrare velocemente l’organizzazione della memoria e dello stack.
Una volta che il programma viene compilato e poi avviato, questo viene diviso in segmenti, che consistono in un insieme di indirizzi virtuali continui, contenente sia codice che dati all’interno della memoria.
I vari segmenti sono:

Lo stack contiene i parametri attuali della funzione, indirizzi di ritorno e le variabili locali, utilizzate come buffer.
Lo stack utilizza la logica LIFO (Last In First Out), l’ultimo elemento entrante sarà il primo ad uscire, come una pila di piatti, i piatti verranno aggiunti da sopra e rimossi sempre da sopra.
Lo stack viene gestito da diversi registri. I registri sono indirizzi di memoria del processore (CPU) di un computer. Sono utilizzati durante l’elaborazione dati per eseguire le istruzioni in linguaggio macchina
Il registro EIP (instruction pointer) contiene l’indirizzo ritorno, che ne determina l’esatta posizione nello stack.
L’indirizzo di ritorno è un riferimento a un’area di memoria contenuta nella parte inferiore dello stack, viene usato per spostare l’esecuzione della runtime in altre parti di memoria (es. uscita alla funzione chiamante).
Un altro importante registro che lo stack usa è ESP (stack pointer), un registro che tiene traccia della posizione di riferimento più recente dello stack, verrà incrementato o diminuito a seguito delle operazioni di pop e push.
EBP invece, chiamato anche base pointer, tiene traccia dell’inizio dello stack, anche questo cambia continuamente in quanto lo stack viene allocato e de allocato continuamente.
Altri registri come EAX, EBX, ECX, EDX, ESI, e EDI vengono usati per salvare dati temporanei.
Quello che succede in un overflow, è il riempimento spropositato di questo spazio di memoria (del buffer) fino a sovrascrivere l’indirizzo di ritorno (quindi buffer overflow), così che il programma non avendo più il riferimento valido alla successiva area di memoria che contenente la prossima istruzione da eseguire, va in crash oppure esegue un accesso non autorizzato a un’altra area di memoria.
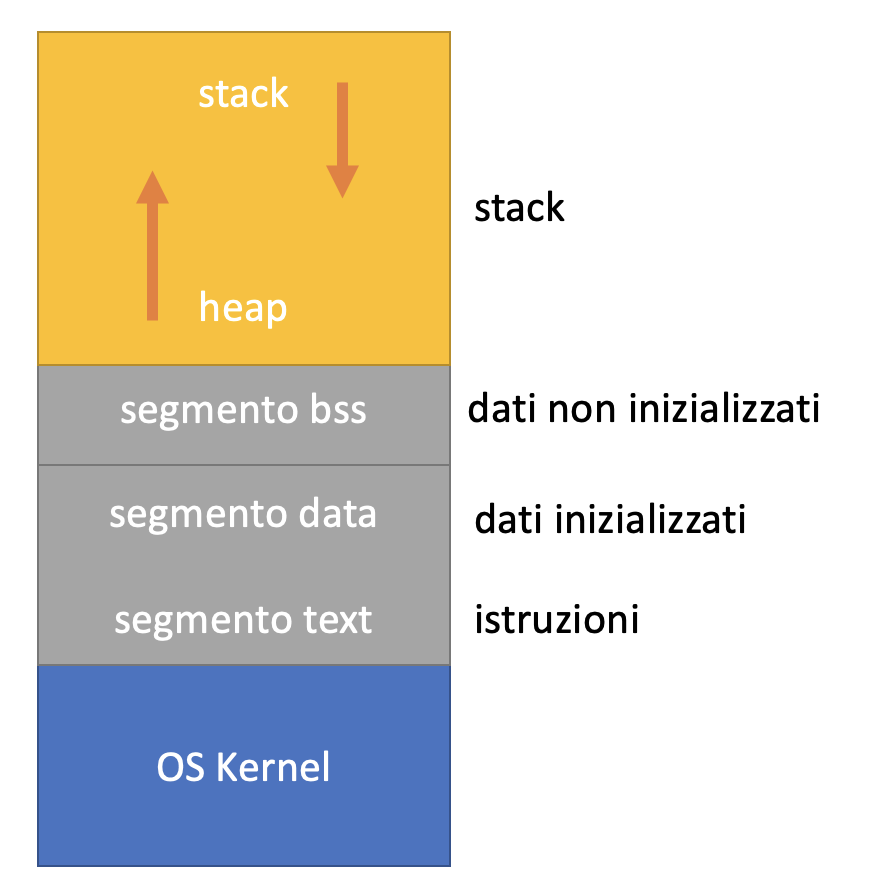
Un esempio è quello di avere un buffer che può contenere 6 caratteri di dati, al carattere 7 è presente l’indirizzo di ritorno.
Immaginiamo un secondo di avere uno stack Ideale di questo tipo:

Se inseriamo la parola “codice” non si crea nessun problema. Nell esempio sopra l’indirizzo di ritorno non verrà alterato e il programma proseguirà come previsto eseguendo l’istruzione alla posizione 170.
Se invece viene inserita la parola “hacking” ecco che il carattere G andrà a sovrascrivere l’indirizzo di ritorno alla posizione 7.
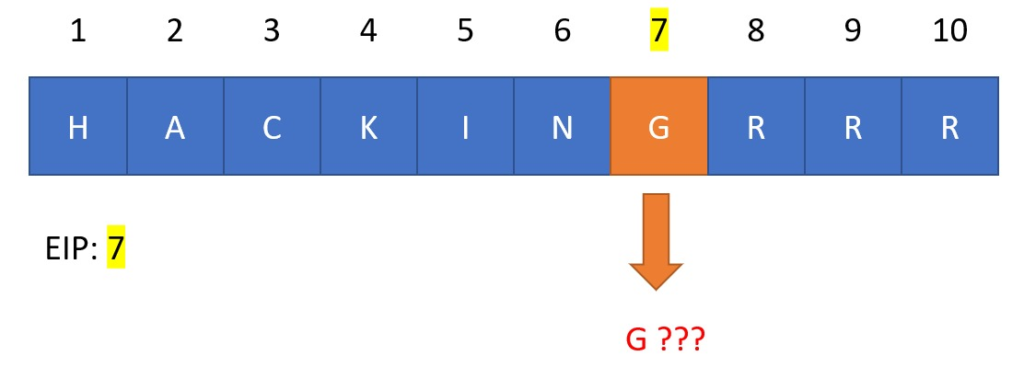
Il contenuto della posizione 7 non punterà a un’area valida (G) e l’esecuzione si bloccherà.
Attraverso questa anomalia un malintenzionato, avendo calcolato quantità esatta di byte che servono per sovrascrivere EIP, può modificare il flusso dell’applicazione, modificando il puntamento di ritorno alla posizione 7 e occupando gli spazi successivi con altro codice dannoso.
Il programma prenderà per valido l’indirizzo di ritorno modificato e continuerà nel eseguire le prossime istruzioni che sono state arbitrariamente iniettate.
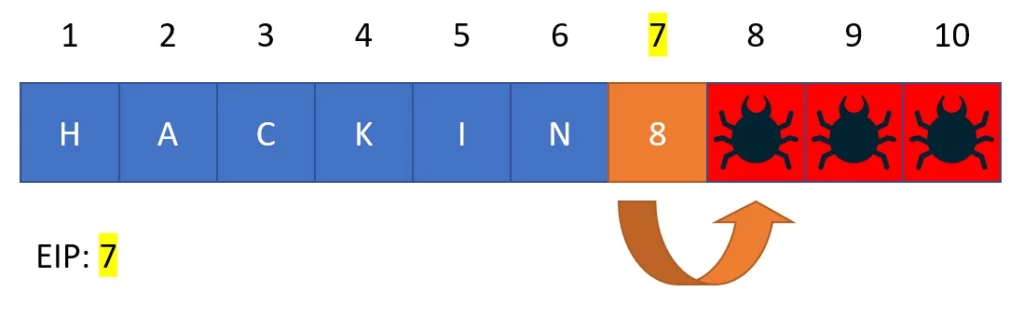
Il processo illustrato è estremamente semplificato e non reale, ma rende l’idea del meccanismo dietro allo sfruttamento di un buffer overflow.
Nella pratica in questo esempio alla posizione 7 è necessario che il nuovo puntamento faccia riferimento a un’area di memoria contenente un istruzione (opcode) che indurrà il proseguire l’esecuzione dalla posizione 8.
In casi più complessi è necessario modificare lo stack e il contenuto dei registri, in altri casi lo spazio dello stack dopo a disposizione dopo il BU potrebbe essere insufficiente a contenere il payload ed è necessario optare per una tipologia staged di esecuzione, per eseguire il payload in un’altra area dello stack.
Nell’articolo al link di seguito si è eseguita una analisi del software Sync Breeze Enterprise.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/