

Nel mondo in rapida evoluzione dell’intelligenza artificiale (IA), un termine è emerso con un’importanza crescente: Modello linguistico o Language Model, in particolare modelli linguistici di grandi dimensioni quindi chiamati Large Language Models.
Probabilmente avrete già usato tool come chatGPT, cioè modelli di Deep Learning che generano testo coerente e simile a quello umano, in tal caso avete già sperimentato le capacità dei Large Language Models. In questo articolo approfondiremo cosa sono i modelli linguistici, come funzionano ed esploreremo alcuni esempi importanti nella letteratura scientifica.
In sintesi, un modello linguistico è un software in grado di prevedere la probabilità di una sequenza di parole. I modelli linguistici vengono addestrati su vasti archivi di dati testuali (corpus) affinchè possano apprendere pattern linguistici.
Immaginate di leggere una frase: “Il gatto è sul __“.

La maggior parte degli esseri umani, in base alla loro comprensione dell’italiano, penserebbe che la parola successiva potrebbe essere “tavolo”, “pavimento”, “divano” o qualcosa di simile. Questa previsione si basa sulle nostre conoscenze ed esperienze precedenti con la lingua. Un modello linguistico mira a fare qualcosa di simile, ma su una scala molto più ampia e con una vasta quantità di testo.
I modelli linguistici assegnano probabilità alle sequenze di parole. Un modello ben addestrato assegnerebbe una probabilità maggiore alla sequenza “Il gatto è sul divano” rispetto a “Il gatto è sul cielo”, poiché quest’ultima è meno comune in un tipico testo italiano.

I modelli linguistici esistono da anni, ma le loro capacità sono state notevolmente migliorate con l’avvento del Deep Learning e delle reti neurali. Questi modelli sono cresciuti in dimensioni, catturando più sfumature e complessità del linguaggio umano. Vediamo alcuni esempi tra i più famosi di modelli che sono stati utilizzati per processare il lunguaggio naturale.
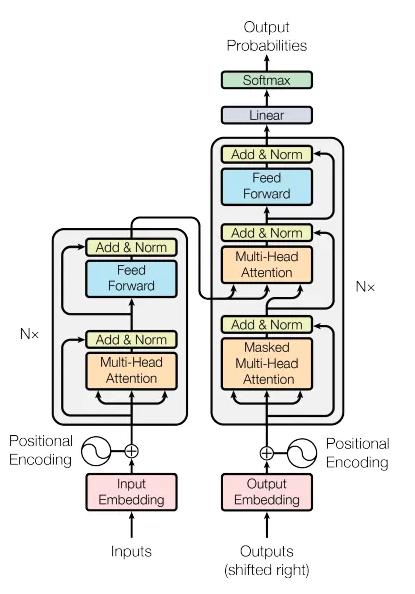
Quando diciamo “grandi” in “modelli linguistici di grandi dimensioni”, ci riferiamo all’enorme numero di parametri che questi modelli hanno, spesso dell’ordine di miliardi. Infatti ad oggi sembra che le performance dei modelli crescano all’aumentera del numero dei parametri, per questo i modelli che vengono commercializzati sono sempre più grandi.
Ovviamente bisogna sempre tenere a mente che modelli di tali dimension hanno un costo economico proibitivo per la maggiorparte dei business, le stime per l’addestramento di tali modelli si aggira sui milioni di euro. Di solito chi non ha queste possibilità economiche si limita a fare un fine-tuning di modelli già addestrati, cioè di continuare l’addestramento di un modello come BERT ma sui propri dati in modo che il modello diventi ancora più bravo su un determinato settore.
Ovviamente questi training hanno degli impatti anche ambientali non indifferenti, per questo si sta facendo anche molta ricerca su come ottimizzare e ridurre la dimensione dei modelli mantenendo comuqnue la loro efficacia. Citiamo alcuni degli ultimi Large Language Models di grandi dimensioni:
I Large Language Models stanno superando ogni aspettativa nel campo dell’elaborazione del linguaggio naturale. Con la loro continua crescita ed evoluzione, le loro potenziali applicazioni in settori come la sanità, la finanza, l’istruzione e l’intrattenimento sono illimitate.
Che si tratti di assistere gli scrittori nella creazione di contenuti, di alimentare chatbot avanzati o di aiutare i ricercatori nella revisione della letteratura, questi modelli hanno aperto la strada a un futuro in cui gli esseri umani e le macchine comunicano senza soluzione di continuità.
