
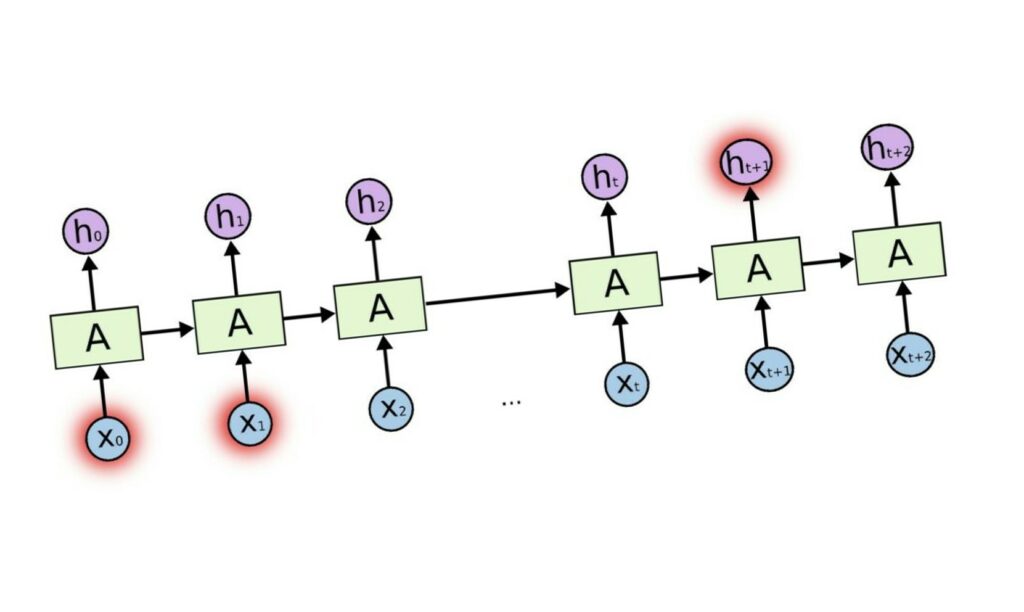
Il meccanismo di attenzione è spesso associato all’architettura dei transformers, ma era già stato utilizzato nelle RNN (reti ricorrenti).
Nei task di traduzione automatica (ad esempio, inglese-italiano), quando si vuole prevedere la parola italiana successiva, è necessario che il modello si concentri, o presti attenzione, sulle parole inglesi più importanti nell’input, utili per ottenere una buona traduzione.
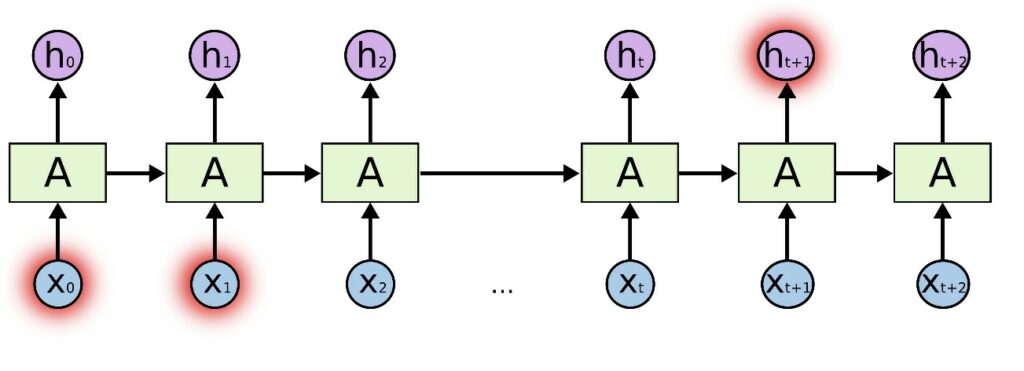
Non entrerò nei dettagli delle RNN, ma l’attenzione ha aiutato questi modelli a mitigare il problema vanishing gradient, e a catturare più dipendenze a lungo raggio tra le parole.
A un certo punto, abbiamo capito che l’unica cosa importante era il meccanismo di attenzione e che l’intera architettura RNN era superflua. Quindi, Attention is All You Need!
L’attenzione classica indica dove le parole della sequenza in output devono porre attenzione rispetto alle parole della sequenza di input. È importante in task del tipo sequence-to-sequence come la traduzione automatica.
La self-attention è un tipo specifico di attenzione. Opera tra due elementi qualsiasi della stessa sequenza. Fornisce informazioni su quanto siano “correlate” le parole nella stessa frase.
Per un dato token (o parola) in una sequenza, la self-attention genera un elenco di pesi di attenzione corrispondenti a tutti gli altri token della sequenza. Questo processo viene applicato a ogni token della frase, ottenendo una matrice di pesi di attenzione (come nella figura).
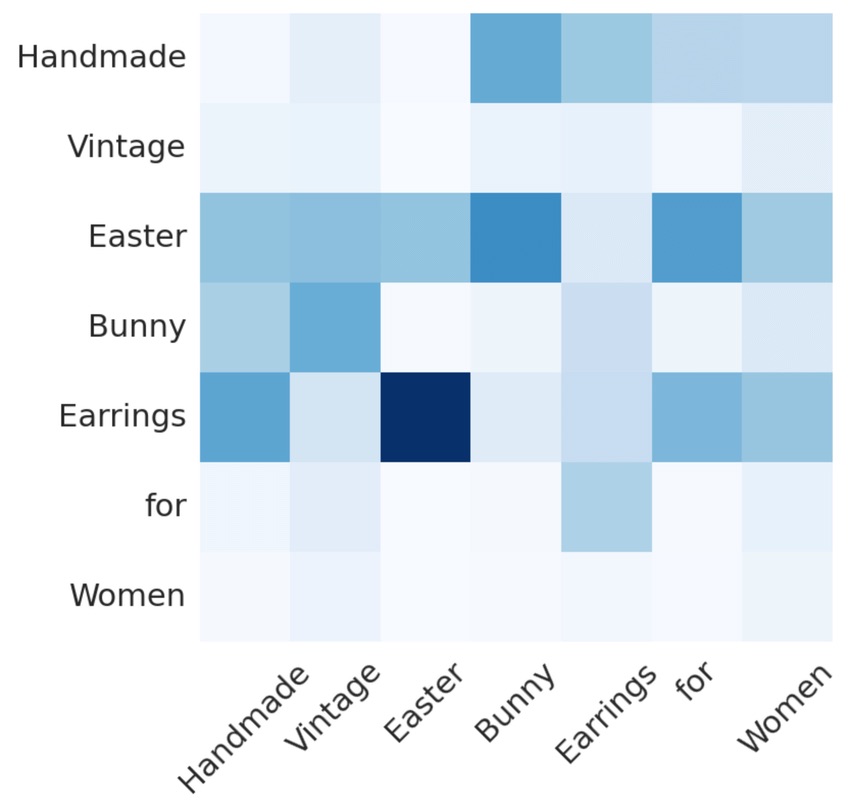
Questa è l’idea generale, in pratica le cose sono un po’ più complicate perché vogliamo aggiungere molti parametri/pesi nell nostra rete, in modo che il modella abbia più capacità di apprendimento.
L’input del nostro modello è una frase come “mi chiamo Marcello Politi”. Con il processo di tokenizzazione, una frase viene convertita in un elenco di numeri come [2, 6, 8, 3, 1].
Prima di passare la frase al transformer, dobbiamo creare una rappresentazione densa per ogni token.
Come creare questa rappresentazione? Moltiplichiamo ogni token per una matrice. La matrice viene appresa durante l’addestramento.
Aggiungiamo ora un po’ di complessità.
Per ogni token, creiamo 3 vettori invece di uno, che chiamiamo vettori: chiave (K), valore (V) e domanda (Q). (Vedremo più avanti come creare questi 3 vettori).
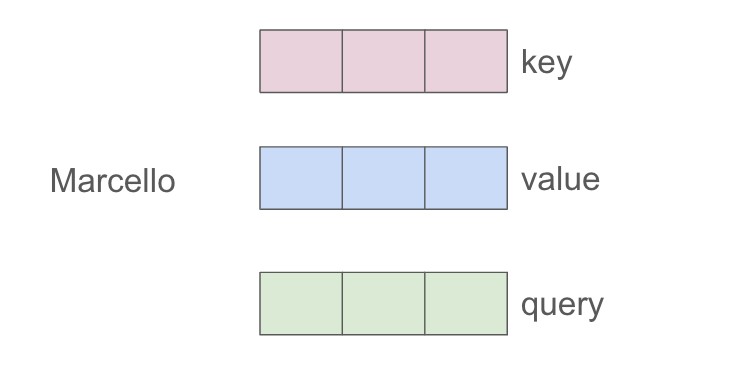
Concettualmente questi 3 token hanno un significato particolare:
L’idea è che ci concentriamo su un particolare token i e vogliamo chiedere qual è l’importanza degli altri token della frase rispetto al token i che stiamo prendendo in considerazione.
Ciò significa che prendiamo il vettore q_i (poniamo una domanda relativa a i) per il token i, e facciamo alcune operazioni matematiche con tutti gli altri token k_j (j!=i). È come se ci chiedessimo a prima vista quali sono gli altri token della sequenza che sembrano davvero importanti per capire il significato del token i.
Ma qual’è questa operazione magica?
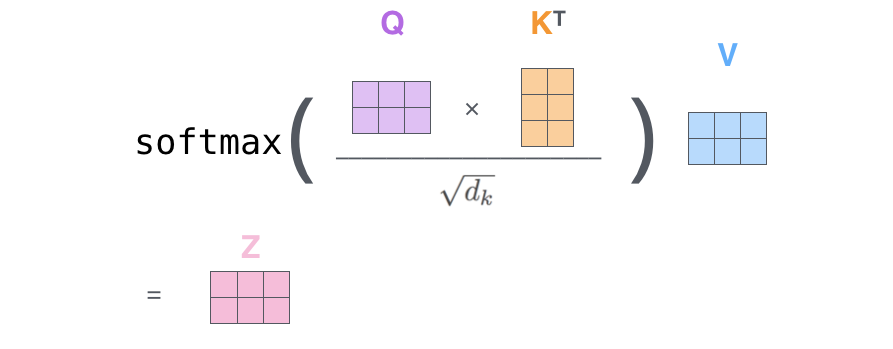
Dobbiamo moltiplicare (dot-product) il vettore della query per i vettori delle chiavi e dividere per un fattore di normalizzazione. Questo viene fatto per ogni token k_j.
In questo modo, otteniamo uno scroe per ogni coppia (q_i, k_j). Trasformiamo questi score in una distribuzione di probabilità applicandovi un’operazione di softmax. Bene, ora abbiamo ottenuto i pesi di attenzione!
Con i pesi di attenzione, sappiamo qual è l’importanza di ogni token k_j per indistinguere il token i. Quindi ora moltiplichiamo il vettore di valore v_j associato a ogni token per il suo peso e sommiamo i vettori. In questo modo otteniamo il vettore finale context-aware del token_i.
Se stiamo calcolando il vettore denso contestuale del token_1, calcoliamo:
z1 = a11v1 + a12v2 + … + a15*v5
Dove a1j sono i pesi di attenzione del computer e v_j sono i vettori di valori.
Fatto! Quasi…
Non ho spiegato come abbiamo ottenuto i vettori k, v e q di ciascun token. Dobbiamo definire alcune matrici w_k, w_v e w_q in modo che quando moltiplichiamo:
Queste tre matrici sono inizializzate in modo casuale e vengono apprese durante l’addestramento; questo è il motivo per cui abbiamo molti parametri nei modelli moderni come gli LLM.
Siamo sicuri che il precedente meccanismo di self-attention sia in grado di catturare tutte le relazioni importanti tra i token (parole) e di creare vettori densi di quei token che abbiano davvero senso?
In realtà potrebbe non funzionare sempre perfettamente. E se, per mitigare l’errore, si rieseguisse l’intera operazione due volte con nuove matrici w_q, w_k e w_v e si unissero in qualche modo i due vettori densi ottenuti? In questo modo forse una self-attention è riuscita a cogliere qualche relazione e l’altra è riuscita a cogliere qualche altra relazione.
Ebbene, questo è ciò che accade esattamente in MHSA. Il caso appena discusso contiene due head (teste), perché ha due insiemi di matrici w_q, w_k e w_v. Possiamo avere anche più head: 4, 8, 16, ecc.
L’unica cosa complicata è che tutte queste teste vengono gestite in parallelo, elaborandole tutte nello stesso calcolo utilizzando i tensori.

Il modo in cui uniamo i vettori densi di ogni head è semplice, li concateniamo (quindi la dimensione di ogni vettore deve essere più piccola, in modo che quando li concateniamo otteniamo la dimensione originale che volevamo) e passiamo il vettore ottenuto attraverso un’altra matrice imparabile w_o.
Supponiamo di avere una frase. Dopo la tokenizzazione, ogni token (o parola) corrisponde a un indice (numero):
tokenized_sentence = torch.tensor([
2, #my
6, #name
8, #is
3, #marcello
1 #politi
])
tokenized_sentence
Prima di passare la frase nel transformer, dobbiamo creare una rappresentazione densa per ciascun token.
Come creare questa rappresentazione? Moltiplichiamo ogni token per una matrice. Questa matrice viene appresa durante l’addestramento.
Costruiamo questa matrice, chiamata matrice di embedding.
torch.manual_seed(0) # set a fixed seed for reproducibility
embed = torch.nn.Embedding(10, 16)
Se moltiplichiamo la nostra frase tokenizzata con la matrice di embedding, otteniamo una rappresentazione densa di dimensione 16 per ogni token
sentence_embed = embed(tokenized_sentence).detach()
sentence_embed
Per utilizzare il meccanismo di attenzione dobbiamo creare 3 nuove matrici w_q, w_k e w_v. Moltiplicando un token di ingresso per w_q otteniamo il vettore q. Lo stesso vale per w_k e w_v.
d = sentence_embed.shape[1] # let's base our matrix on a shape (16,16)
w_key = torch.rand(d,d)
w_query = torch.rand(d,d)
w_value = torch.rand(d,d)
Calcoliamo ora i pesi di attenzione solo per il primo token della frase.
token1_embed = sentence_embed[0]
#compute the tre vector associated to token1 vector : q,k,v
key_1 = w_key.matmul(token1_embed)
query_1 = w_query.matmul(token1_embed)
value_1 = w_value.matmul(token1_embed)
print("key vector for token1: \n", key_1)
print("query vector for token1: \n", query_1)
print("value vector for token1: \n", value_1)
Dobbiamo moltiplicare il vettore query associato al token1 (query_1) con tutte le chiavi degli altri vettori.
Quindi ora dobbiamo calcolare tutte le chiavi (chiave_2, chiave_2, chiave_4, chiave_5). Ma aspettate, possiamo calcolarle tutte in una sola volta moltiplicando sentence_embed per la matrice w_k.
keys = sentence_embed.matmul(w_key.T)
keys[0] #contains the key vector of the first token and so on
Facciamo la stessa cosa con i valori
values = sentence_embed.matmul(w_value.T)
values[0] #contains the value vector of the first token and so on
Calcoliamo la prima parte della formula adesso.
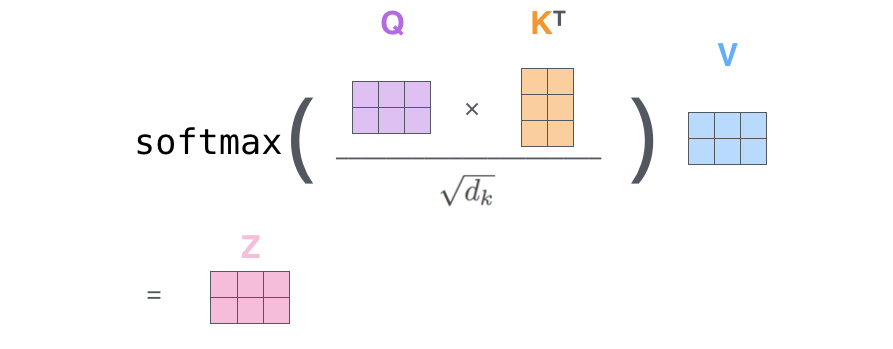
import torch.nn.functional as F
# the following are the attention weights of the first tokens to all the others
a1 = F.softmax(query_1.matmul(keys.T)/d**0.5, dim = 0)
a1
Con i pesi di attenzione sappiamo qual è l’importanza di ciascun token. Quindi ora moltiplichiamo il vettore di valori associato a ogni token per il suo peso.
Per ottenere il vettore finale del token_1 che includa anche il contesto.
z1 = a1.matmul(values)
z1
Allo stesso modo, possiamo calcolare i vettori densi consapevoli del contesto di tutti gli altri token. Ora stiamo utilizzando sempre le stesse matrici w_k, w_q, w_v. Diciamo che usiamo una sola head.
Ma possiamo avere più triplette di matrici, quindi una multi-heads. Ecco perché si chiama multi-head attention.
I vettori densi di un token in ingresso, dati in input a ciascuna head, vengono poi concatenati e trasformati linearmente per ottenere il vettore denso finale.
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(0) #
# Tokenized sentence (same as yours)
tokenized_sentence = torch.tensor([2, 6, 8, 3, 1]) # [my, name, is, marcello, politi]
# Embedding layer: vocab size = 10, embedding dim = 16
embed = nn.Embedding(10, 16)
sentence_embed = embed(tokenized_sentence).detach() # Shape: [5, 16] (seq_len, embed_dim)
d = sentence_embed.shape[1] # embed dimension 16
h = 4 # Number of heads
d_k = d // h # Dimension per head (16 / 4 = 4)
# Define weight matrices for each head
w_query = torch.rand(h, d, d_k) # Shape: [4, 16, 4] (one d x d_k matrix per head)
w_key = torch.rand(h, d, d_k) # Shape: [4, 16, 4]
w_value = torch.rand(h, d, d_k) # Shape: [4, 16, 4]
w_output = torch.rand(d, d) # Final linear layer: [16, 16]
# Compute Q, K, V for all tokens and all heads
# sentence_embed: [5, 16] -> Q: [4, 5, 4] (h, seq_len, d_k)
queries = torch.einsum('sd,hde->hse', sentence_embed, w_query) # h heads, seq_len tokens, d dim
keys = torch.einsum('sd,hde->hse', sentence_embed, w_key) # h heads, seq_len tokens, d dim
values = torch.einsum('sd,hde->hse', sentence_embed, w_value) # h heads, seq_len tokens, d dim
# Compute attention scores
scores = torch.einsum('hse,hek->hsk', queries, keys.transpose(-2, -1)) / (d_k ** 0.5) # [4, 5, 5]
attention_weights = F.softmax(scores, dim=-1) # [4, 5, 5]
# Apply attention weights
head_outputs = torch.einsum('hij,hjk->hik', attention_weights, values) # [4, 5, 4]
head_outputs.shape
# Concatenate heads
concat_heads = head_outputs.permute(1, 0, 2).reshape(sentence_embed.shape[0], -1) # [5, 16]
concat_heads.shape
multihead_output = concat_heads.matmul(w_output) # [5, 16] @ [16, 16] -> [5, 16]
print("Multi-head attention output for token1:\n", multihead_output[0])
In questo post ho implementato una versione semplice del meccanismo di attenzione. Questo non è il modo in cui viene realmente implementato nei framework moderni, ma il mio scopo è quello di fornire alcuni spunti per permettere a chiunque di capire come funziona. Nei prossimi articoli analizzerò l’intera implementazione di un’architettura transformer.
