



Negli ultimi due anni ho lavorato principalmente con large language models, occupandomi di training, fine-tuning, prompting e così via, poiché era molto richiesto dal mercato e dagli utenti. Ma credo che gli LLM che lavorano principalmente con il testo siano solo l’inizio della GenAI. A un certo punto, tutti vorranno un’AI fisica, in cui i modelli possano vedere, sentire, percepire e ragionare in modo più concreto e umano.
Quindi iniziamo con la multimodalità. In questo notebook introduco LLaVA, un’architettura in grado di interpretare sia immagini che testo per generare risposte multimodali.
In questo tutorial utilizzeremo componenti più leggeri, adatti a far girare il notebook in un ambiente gratuito come Google Colab.
I componenti che utilizzeremo sono:
1️⃣ CLIP-ViT B/32 come image encoder
2️⃣ TinyLlama-1.1B come language model
3️⃣ Un MLP adapter a 2 layer per collegare i due modelli
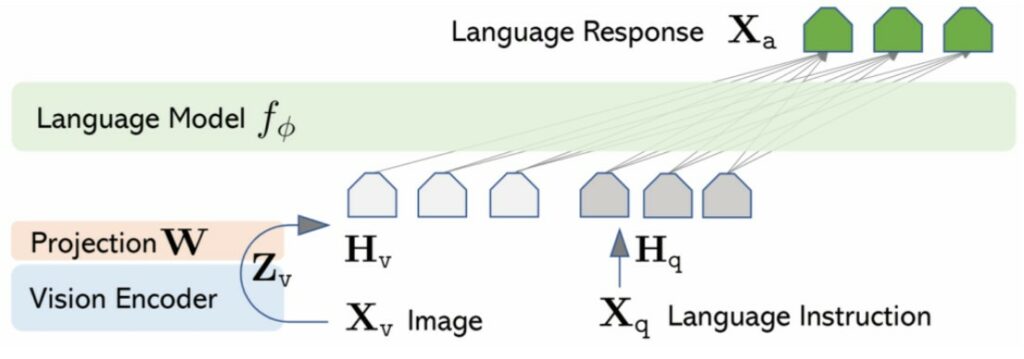
Dal paper Visual Instruction Tuning (NeurIPS 2023)
Prima di inziare a scrivere codice dobbiamo creare il nostro environment.
Installiamo e importiamo le librerie necessarie.
!pip install -U datasets
import json
from pathlib import Path
import requests
import safetensors
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from PIL import Image
from transformers import (
AutoConfig,
AutoTokenizer,
LlamaTokenizer,
LlavaConfig,
LlavaForConditionalGeneration,
LlavaProcessor,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
)
from transformers.models.clip.modeling_clip import CLIPVisionModel
from transformers.models.clip.image_processing_clip import CLIPImageProcessor
Il nostro modello LLaVA sarà composto da :
vision_backbone_name = "openai/clip-vit-base-patch32"
text_backbone_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
_ = hf_hub_download(
vision_backbone_name, filename="pytorch_model.bin", local_dir="/content"
)
_ = hf_hub_download(
text_backbone_name, filename="model.safetensors", local_dir="/content"
)
vision_config = AutoConfig.from_pretrained(vision_backbone_name).vision_config
text_config = AutoConfig.from_pretrained(text_backbone_name)
llava_config = LlavaConfig(vision_config=vision_config, text_config=text_config)
model = LlavaForConditionalGeneration(llava_config).cuda()
model
In precedenza abbiamo detto che è possibile costruire un modello LLaVA partendo da un image encoder pre-addestrato e un LLM pre-addestrato. Facciamolo davvero!
Il modello originale di LLaVA è inizializzato a partire da un CLIP-ViT L/14 e un Vicuna v1.5 7B. Per rendere il tutto più gestibile con le risorse offerte dal piano gratuito di Google Colab, utilizzeremo invece un CLIP-ViT B/16 e un TinyLlama 1.1B.
L’unico componente che addestreremo sarà un MLP adapter a 2 layer che collega i due modelli.
def load_weights(path_to_weights: str):
if path_to_weights.endswith(".safetensors"):
return load_safetensors_weights(path_to_weights)
elif path_to_weights.endswith(".bin"):
return load_bin_weights(path_to_weights)
else:
raise ValueError(f"Unsupported weights file: {path_to_weights}")
def load_bin_weights(path_to_weights: str):
return torch.load(path_to_weights, weights_only=True)
def load_safetensors_weights(path_to_weights: str):
return safetensors.torch.load_file(path_to_weights)
vision_backbone_state_dict = load_weights("/content/pytorch_model.bin")
text_backbone_state_dict = load_weights("/content/model.safetensors")
Iniettiamo i pesi del vision backbone nel modello 💉
incompatible_keys = model.vision_tower.load_state_dict(
vision_backbone_state_dict, strict=False
)
assert len(incompatible_keys.missing_keys) == 0, (
f"Missing keys in state dict: {incompatible_keys.missing_keys}"
)
incompatible_keys.unexpected_keys
Iniettiamo i pesi del text backbone nel modello 💉
incompatible_keys = model.language_model.load_state_dict(
text_backbone_state_dict, strict=True
)
Congeliamo i componenti pre-addestrati ❄️
_ = model.vision_tower.requires_grad_(False)
_ = model.language_model.requires_grad_(False)
def count_parameters(model, trainable_only=False):
return sum(
p.numel()
for p in model.parameters()
if not trainable_only or p.requires_grad
)
print(f"Total parameters: {count_parameters(model)}")
print(f"Trainable parameters: {count_parameters(model, trainable_only=True)}")
tokenizer = LlamaTokenizer.from_pretrained(
text_backbone_name, additional_special_tokens=["<image>", "<pad>"]
)
tokenizer.pad_token_id = 32001
Qui sotto è mostrato il formato che useremo per interagire con il nostro modello LLaVA.
La prima parte è il cosiddetto system prompt, che contiene linee guida generali su come il modello dovrebbe rispondere all’utente.
La seconda parte è un Jinja template (fondamentalmente codice) che determina come viene resa la conversazione a partire da un input strutturato (vedi esempio sotto).
LLAVA_CHAT_TEMPLATE = (
"A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. "
"{% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"
)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
sample_messages = [
{
"content": [
{
"index": 0,
"text": None,
"type": "image"
},
{
"index": None,
"text": "\nWhat potential activities might be popular at this location?",
"type": "text"
}
],
"role": "user"
},
{
"content": [
{
"index": None,
"text": (
"At this location, with a sandy path leading to the ocean where multiple boats, including "
"sailboats, are moored, popular activities might include boating, sailing, swimming, and "
"beachcombing. Additionally, the sandy path and shoreline provide an ideal setting for leisurely "
"strolls and picnics, while the ocean view offers a serene environment for relaxation and "
"photography. Depending on the specific area and available facilities, other water sports such as "
"kayaking, paddleboarding, and snorkeling could also be prevalent."
),
"type": "text"
}
],
"role": "assistant"
}
]
tokenizer.apply_chat_template(
sample_messages, tokenize=False, add_generation_prompt=False
)
processor = LlavaProcessor(
image_processor=CLIPImageProcessor.from_pretrained(vision_backbone_name),
tokenizer=tokenizer,
patch_size=model.config.vision_config.patch_size,
)
processor.chat_template = LLAVA_CHAT_TEMPLATE
model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=8)
train_dataset = load_dataset(
"HuggingFaceH4/llava-instruct-mix-vsft", split="train", streaming=True
)
Come sono fatti in nostri dati di training?
next(iter(train_dataset))
Come creiamo un batch di esempio?
def get_data_collator(processor, ignore_index):
def collate_examples(examples):
# Extract texts and images from the raw examples
texts = []
images = []
for example in examples:
messages = example["messages"]
text = processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
# Process the inputs (tokenize text and transform images)
batch = processor(texts, images, return_tensors="pt", padding=True)
# Create labels
labels = batch["input_ids"].clone()
if processor.tokenizer.pad_token_id is not None:
labels[labels == processor.tokenizer.pad_token_id] = ignore_index
batch["labels"] = labels
return batch
return collate_examples
# NOTE: this does a bit more than a collate function should...
args = Seq2SeqTrainingArguments(
output_dir="/content/training_output",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
learning_rate=2e-4,
max_steps=350,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr": 2e-5},
warmup_ratio=0.05,
logging_strategy="steps",
logging_steps=5,
fp16=True,
remove_unused_columns=False, # Important!
optim="adamw_torch",
report_to="none",
save_strategy="no", # let's not save the checkpoint to disk, otherwise it'll take 5 mins
)
trainer = Seq2SeqTrainer(
model=model,
args=args,
data_collator=get_data_collator(
processor, ignore_index=model.config.ignore_index,
),
train_dataset=train_dataset,
)
trainer.train()
È importante notare che, per garantire che l’inferenza funzioni come previsto, bisognerebbe utilizzare modelli più pesanti e addestrare per un periodo di tempo più lungo.
Useremo questa immagine per l’inferenza:

conversation = [
{
"content": [
{
"type": "image"
},
{
"text": "\nWhat is represented in the image?",
"type": "text"
}
],
"role": "user"
}
]
image_url = "https://llava-vl.github.io/static/images/monalisa.jpg"
inputs_for_generation = processor(
images=Image.open(requests.get(image_url, stream=True).raw),
text=processor.apply_chat_template(conversation, add_generation_prompt=True),
return_tensors="pt",
)
inputs_for_generation = inputs_for_generation.to(device=model.device)
output = trainer.model.generate(
**inputs_for_generation, max_new_tokens=200, do_sample=False
)
print(processor.decode(output[0], skip_special_tokens=True))
🔗 Demo funzionante: huggingface.co/spaces/badayvedat/LLaVA
Penso che questo piccolo progetto sia interessante per capire meglio come funzionano i modelli multimodali come LLaVA. Anche se abbiamo utilizzato modelli più piccoli, l’idea principale rimane la stessa: combinare visione e linguaggio in un unico sistema capace di comprendere le immagini e parlarne.
Ovviamente, i risultati ottenuti in questo toy example non sono particolarmente buoni, c’è molto margine di miglioramento. Ma far funzionare LLaVA in un ambiente con risorse limitate è già di per sé una bella sfida.
