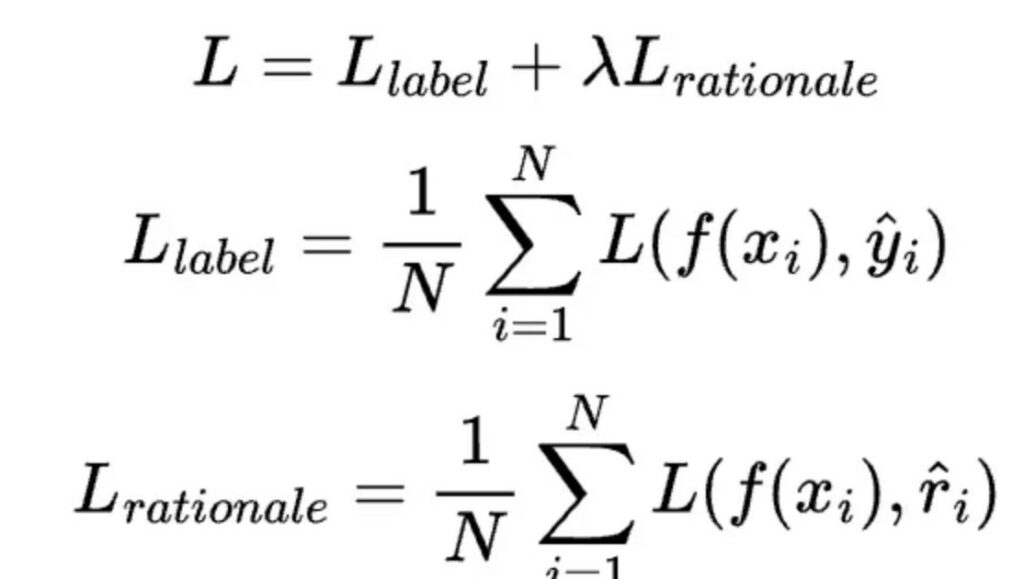Ad oggi, i large language models (LLMs) hanno dimensioni enormi e inoltre vengono utilizzati in molti software per permettere agli utenti di compiere azioni utilizzando semplicemente il linguaggio naturale.
Le recenti ricerche sull’intelligenza artificiale hanno dimostrato che i modelli linguistici di grandi dimensioni hanno buone capacità di generalizzazione permettendoci di utilizzare lo zero-shot learning, cioè poter chiedere al modello di risolvere un task per il quale non è stato addestrato.
Pensate che un modello come PaLM ha un totale di 540 miliardi di parametri, e questo non è neanche tra i modelli più grandi di oggi! Molte aziende desiderano utilizzare questi LLM e personalizzarli in base ai propri casi d’uso. Il problema è che utilizzare questi modelli in produzione in modo indipendente non è sempre fattibile in termini di costi e di hardware disponibile.
Advertising
Distilling Step-by-step
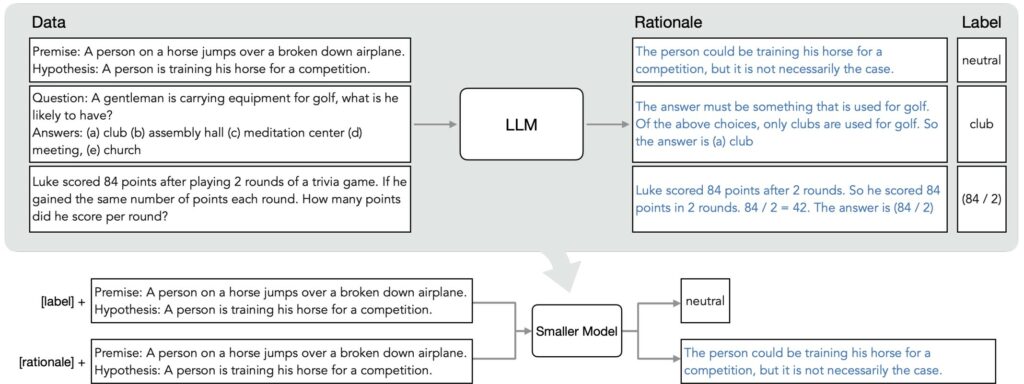
In un recente paper di Google AI, “Distilling Step by Step”, gli autori propongono un approccio per distillare la conoscenza di modelli di grandi dimensioni (540B PaLM) in uno molto più piccolo (770M-T5, 6GB RAM). La tecnica del distilling in generale consiste nell’utilizzare un modello molto grande per insegnare ad un modello più piccolo di comportarsi allo stesso modo. In questo modo potremo mettere in produzione solamente il modello più piccolo con prestazioni di poco inferiori.
Esistono due metodi principale che vengono utilizzati per customizzare un LLM a un caso d’uso specifico:
Fine-Tuning: Il metodo di fine-tuning prevede l’introduzione di layer aggiuntivi alla fine di un modello pre-addestrato. Questo nuovo modello viene ulteriormente addestrato utilizzando un dataset supervisionato. Tuttavia questo metodo, richiede un notevole dispendio di RAM e di computazione, quindi GPU.
Task Distillation: Come abbiamo detto, gli LLM di grandi dimensioni offrono la capacità chiamata di zero-shot. La distillazione dei task prevede la generazione di pseudo-label, con i modelli di grandi dimensioni e l’addestramento del modello più piccolo nel task specifico. In poco parole mi fido del modello grande per generare dai label che per me sono “giuste” e che il modello piccolo deve imparare a predirre.
Nel paper, gli autori riformulano il problema della distillazione della conoscenza come un problema multi-task, utilizzando la generazione di rationale nella fase di addestramento.
Quali sono gli step da seguire?
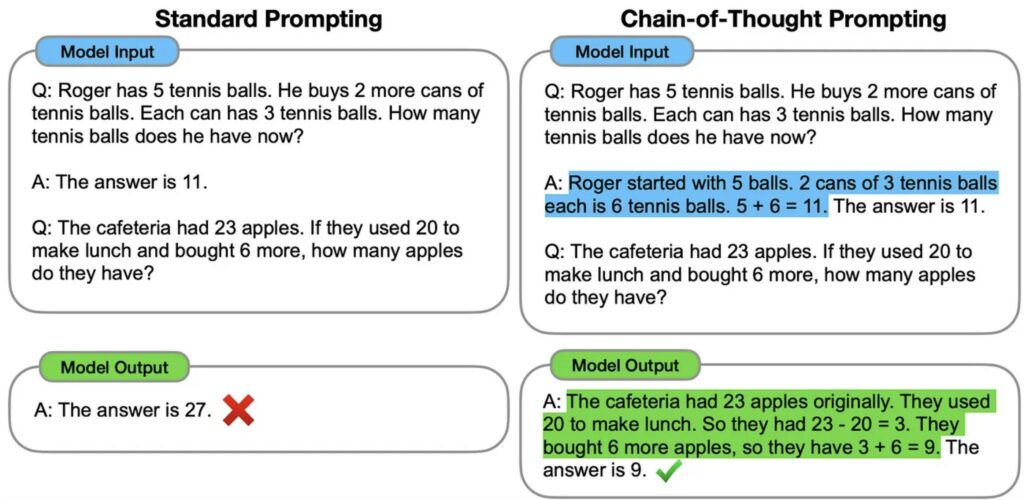
Il modello più grande si comporta da insegnante e fornisce i rationales (cioè la motivazione) utilizzando la tecnica di prompting detta Chain-of-Thought (CoT), in modo da portare il LLM a generare sia un ouptut che la spiegazione o rationale di quell’output.
Il modello studente impara a produrre sia le label che le motivazioni simultaneamente, dato un prompt o testo in ingresso (apprendimento multi-task).
In questo modo, il modello studente impara a ragionare come l’insegnante ed elimina la necessità di utilizzare l’LLM insegnante in inferenza, e quindi in produzione.
Nello specifico l’apprendimento multi-task è un paradigma di apprendimento in cui il modello impara a svolgere più compiti/produrre più output simultaneamente al momento dell’addestramento (nel nostro caso label e rationale). Questo modello viene addestrato utilizzando una funzione loss che compone le loss di ogni singolo task:
Altri metodi
C’è un grande interesse per le tecniche che permettono di ridurre le risorse necessarie per l’esecuzione di nuovi modelli di Machine Learning. In letteratura scientifica possiamo trovare diversi metodi per la compressione di tali modelli. Tra i più importanti abbiamo:
Quantizzazione: diminuisce la precisione dei pesi per migliorare l’efficienza. Cioè rappresentiamo i pesi della rete neurale usando meno bit.
Pruning: consiste nel ridurre il numero di pesi eliminando le connessioni tra neuroni o eliminando i neuroni stessi.
Distillazione della conoscenza: il funzionamento di questa tecnica prevede l’utilizzo di un modello più grande chiamato “insegnante” e un modello più piccolo chiamato “studente”. Lo studente viene istruito ad imitare l’insegnate.
Low-rank tensor decomposition: questa tecnica consiste nel sostituire le grandi matrici che rappresentano i layer della rete, con diverse matrici più piccole. Questo accelera molto i tempi di inferenza della rete.
Conclusioni
Se vi è piaciuto questo articolo, potreste essere interessati a saperne di più riguardo le tecniche di compressione quindi vi proprongo un mio recente articolo: Ottimizzare Modelli di Deep Learning in produzione.
Se volete implementare la distillazione della conoscenza o altre tecniche, potete consultare le seguenti librerie:
📢 Resta aggiornatoTi è piaciuto questo articolo? Rimani sempre informato seguendoci su Google Discover (scorri in basso e clicca segui) e su 🔔 Google News. Ne stiamo anche discutendo sui nostri social: 💼 LinkedIn, 📘 Facebook e 📸 Instagram. Hai una notizia o un approfondimento da segnalarci? ✉️ Scrivici
Esperto di intelligenza artificiale con una grande passione per l'esplorazione spaziale. Ho avuto la fortuna di lavorare presso l'Agenzia Spaziale Europea, contribuendo a progetti di ottimizzazione del flusso di dati e di architettura del software. Attualmente, sono AI Scientist & Coach presso la PiSchool, dove mi dedico alla prototipazione rapida di prodotti basati sull'intelligenza artificiale. Mi piace scrivere articoli riguardo la data science e recentemente sono stato riconosciuto come uno dei blogger più prolifici su Towards Data Science.
Aree di competenza:Intelligenza artificiale, AI decentralizzata su blockchain, Smart contract e protocolli ERC-8004, Sistemi multi-agente, Sicurezza e Defensive AI, Inference decentralizzata verificabile, Blockchain engineering e integrazione AI