



Il Reinforcement Learning (RL) è storicamente legato ad ambiti diversi da quello dell’elaborazione del linguaggio naturale (NLP). Sicuramente è stato molto utilizzato nel campo della robotica. Pensate ad esempio ad un robot che deve apprendere come camminare rispettando un percorso.
Questo robot riceve un feedback negativo ogni volta che va a sbattere contro il muro, e in questo modo, come fa un bambino, sbagliando impara la strategia migliore per arrivare a destinazione.
Il Reinforcement learning with human feedback (RLHF), che ha recentemente attirato molta attenzione, ha avviato una nuova rivoluzione nell’applicazione delle tecniche di Reinforcment Learning (RL) nel campo dell’NLP, specialmente nei modelli di linguaggio più avanzati (LLM). In questo modo si riesce a sviluppare un modello che sia allineato con gli obiettivi umani, che generalmente consistono nel rispondere in modo etico ed evitando allucinazioni.
In questo blog, cercheremo di capire l’intero processo di addestramento basato sul RLHF per un LLM custom.
Il processo RLHF è composto da 3 fasi:
La pipeline di training è riassunta dal seguente diagramma.
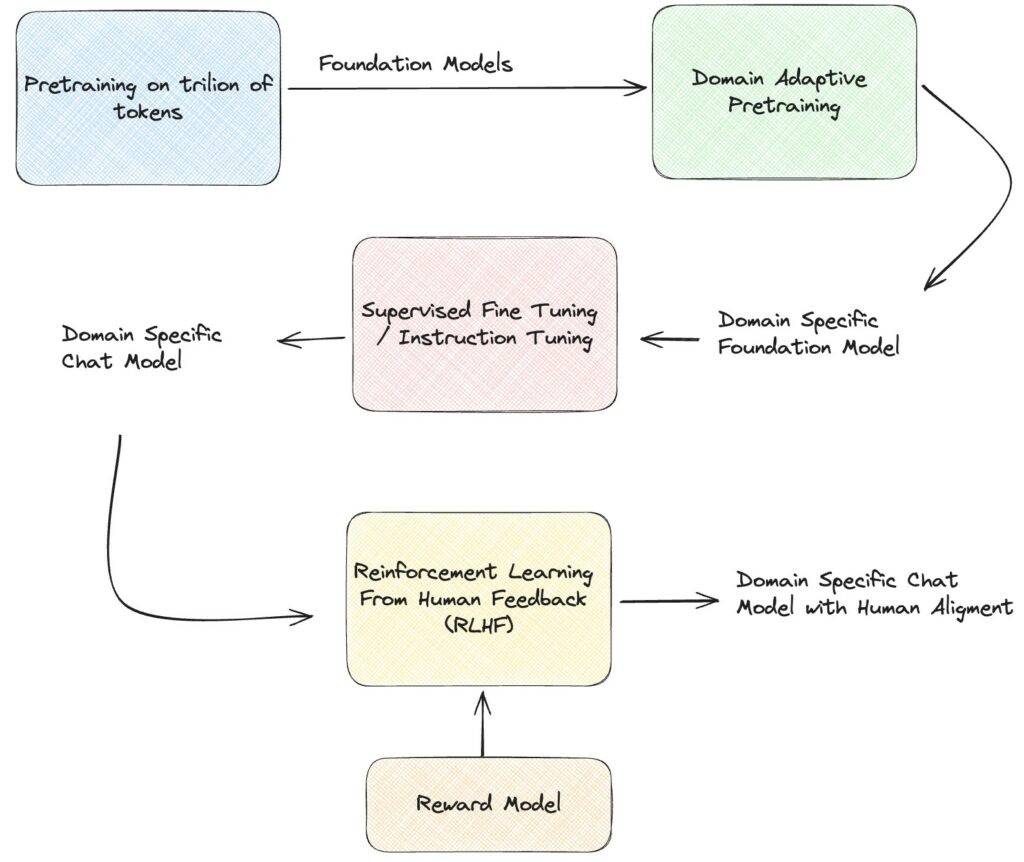
La fase di domain specific pre-training è un fase in cui si fornisce al modello di linguaggio la conoscenza del dominio di applicazione finale (ad esempio ambito medico, giornalistico, etc). In questa fase, il modello viene perfezionato utilizzando il task di causal language modelling (cioè previsione del token/parola successivo), è molto simile a quando un modello viene addestrato da zero su un corpus di dati testuali grezzi specifici del dominio. In questo caso, tuttavia, i dati richiesti sono molto di meno, considerando che il modello è già stato pre-addestrato su milioni di token.
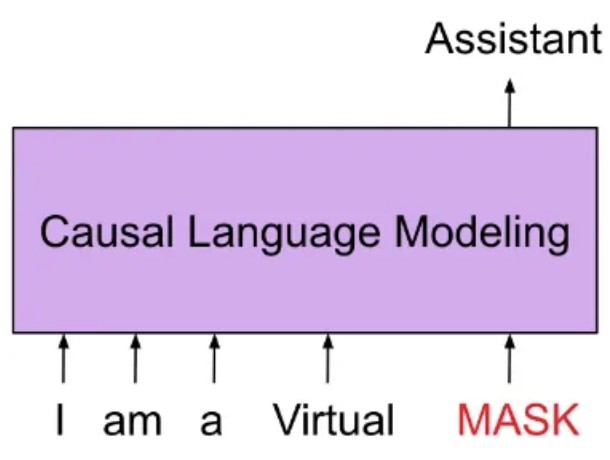
Per il task causal language modelling (CLM), prenderemo tutti i testi nel nostro dataset e li concateneremo dopo averli tokenizzati. Successivamente, li divideremo in esempi in sequenza di una certa lunghezza. In questo modo, il modello riceverà frammenti di testo contiguo e dovrà predirre il continuo della sequenza. Il modello dopo questa fase subirà una distribution shifting, cioè avrà più probabilità di generare la parola “malattia” se è stato addestrato su un dataset medico.
L’output della fase di supervised fine tuning è un modello in grado di riconoscere il contesto del testo in input e generare le parole/frasi che siano legato al contesto e che siano della forma che ci aspettiamo. Questo modello assomiglia anche a un tipico modello sequence-to-sequence. Il fine-tuning supervisionato eseguito con coppie prompt-risposta è un metodo economico utilizzato per inserire conoscenze specifiche del dominio e del task in un LLM pre-addestrato per farlo rispondere a domande specifiche prendendo in considerazione il contesto.
Il RLHF è utilizzato per garantire che il LLM sia allineato alle preferenze umane e produca output migliori. A tal fine, il modello di ricompensa (o reward) viene addestrato per generare un punteggio per una ciascuna coppia (prompt, risposta), un pò come il robot che riceveva una ricompensa quando non sbatteva contro il muro.
Questo task può anche essere modellato come un semplice compito di classificazione. Il modello di ricompensa utilizza dati etichettati dove il ranking di preferenze su un numero n di risposte generate dal LLM sono state scelte da annotatori umani esperti.
In questa ultima fase, viene addestrato il modello generato dal passaggio 1, cioè il risultato dopo la fase di supervised fine tuning. Lo scopo è quello di generare degli output che massimizzino i punteggi del modello di reward. Fondamentalmente, utilizzeremo il modello di reward per regolare gli output del modello supervisionato in modo che produca risposte simili a quelle umane. Le ricerche hanno dimostrato che in presenza di dati di alta qualità, i modelli addestrati con il RLHF sono superiori ai modelli che sono solamente stati addestrati tramite il SFT. Questo addestramento viene eseguito utilizzando un metodo di apprendimento per rinforzo chiamato Proximal Policy Optimization (PPO).
L’Proximal Policy Optimization è un algoritmo di apprendimento per rinforzo introdotto da OpenAI nel 2017. Inizialmente utilizzato come uno degli algoritmi di deep reinforcement learning più performanti per problemi di controllo 2D e 3D (videogiochi, Go, locomozione 3D), PPO ha ora trovato un posto nell’NLP, nello specifico nel pipeline RLHF. Per una panoramica più dettagliata dell’algoritmo PPO, fare riferimento a questo link.
In questo articolo, abbiamo brevemente introdotto il processo che molti ricercatori e ingegneri hanno utilizzato per creare i propri LLM specifici di dominio, allineati con le preferenze umane. Bisogna tenete a mente che il RLHF richiede un dataset curato di alta qualità etichettato da un esperto umano che ha valutato le risposte precedenti degli LLM (c’è quindi il coinvolgimento umano nel loop: “human in the loop”). Possiamo dire quindi che questo processo è costoso e lento. Oltre al RLHF, esistono nuove tecniche come DPO (Direct Preference Optimization) e RLAIF (Reinforcement Learning with AI Feedback). Questi metodi sono dimostrati essere più economici e rapidi rispetto a RLHF. Tuttavia, molti dei principi sottostanti rimangono gli stessi.
