

Suchir Balaji – che ha lasciato OpenAi questo agosto – si è chiesto se l’Intelligenza artificiale generativa sia davvero regolata da un uso corretto. Secondo la sua ricerca l’uso di dati protetti da copyright da parte di OpenAI violerebbe la legge e tecnologie come ChatGPT starebbero danneggiando Internet, oltre che apportare alla società più danni che benefici. La sua morte – avvenuta per suicidio il 14 dicembre 2024 – riporta alla luce una visione etica dell’innovazione nella battaglia per un’intelligenza artiiciale più responsabile di chi mette in discussione l’operato delle Big Tech.
“Negli ultimi due anni – ha rivelato Balji al New York Times – un certo numero di individui e aziende hanno fatto causa a varie aziende di intelligenza artificiale, tra cui OpenAI, sostenendo che hanno utilizzato illegalmente materiale protetto da copyright per addestrare le loro tecnologie”, cause che potrebbero avere un impatto significativo sullo sviluppo dell’IA negli USA.
Tra queste aziende – come riporta Harvard Law Today – ci sarebbe il New York Times, secondo il quale ChatGBT avrebbe fatto scraping di parti fondamentali di suoi contenuti creando proprie librerie (con materiale non concesso in licenza): una pratica che indebolirebbe il modello di business del Times, che – secondo i legali “si basa su licenze, abbonamenti e ricavi pubblicitari”. Tuttavia secondo Mason Kortz – istruttore presso la Harvard Law School Cyberlaw Clinic presso il Berkman Klein Center for Internet & Society – il New York Times dovrebbe dimostrare che gli elementi copiati includano un’espressione protetta e che la quantità utilizzata da parte dell’IA sia corretta.
Ebbene Suchir Balaji definisce l’uso corretto in base ad un bilanciamento di 4 fattori (di cui 1 e 4 tendono ad essere i più importanti), basati sulla Sezione 107 del Copyright Act del 1976, che regola l’uso corretto di un’opera protetta da copyright:
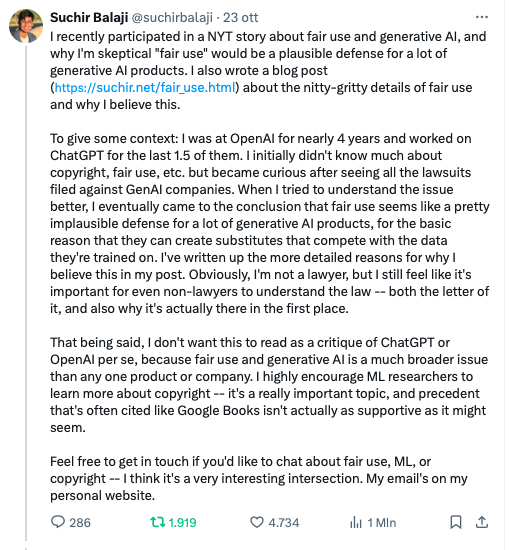
Nessuno dei quattro fattori sembra pesare a favore del fatto che ChatGPT si fondi su un uso corretto dei suoi dati di training. “Sebbene i modelli generativi raramente producano output sostanzialmente simili a uno qualsiasi dei loro input di training – spiega Balaji – “il processo di training di un modello generativo comporta la creazione di copie di dati protetti da copyright”.
Il processo di training di un modello generativo comporta la creazione di copie di dati protetti da copyright: quindi se queste copie non sono autorizzate – e senza regolamentazione – “ciò potrebbe potenzialmente essere considerato una violazione del copyright, a seconda che l’uso specifico del modello si qualifichi o meno come “uso corretto”, determinato necessariamente caso per caso. Balaji ha sostenuto che le pratiche di OpenAI stanno distruggendo la redditività commerciale di individui, aziende e servizi Internet, creando contenuti che competono direttamente con le fonti di dati originali, minandone l’uso corretto. Tornando al New York Times, i modelli generativi potrebbero avere un effetto lesivo sul mercato dell’originale: senza una buona regolamentazione – basata sulla trasparenza – e tasse di licenza si potrebbe parlare di danno del mercato, questione legata anche al whistleblowing di Suchir Balaji, secondo cui la società di Sam Altman, ha reperito enormi quantità di dati digitali da Internet per addestrare i suoi modelli di intelligenza artificiale, facendo copie non autorizzate dei dati protetti da copyright e creando versioni simili agli originali, senza rispettare le disposizioni sull’uso corretto.
“Questo non è un modello sostenibile per l’ecosistema di Internet” _ [Suchir Balaji, New York Times, ottobre 2024].
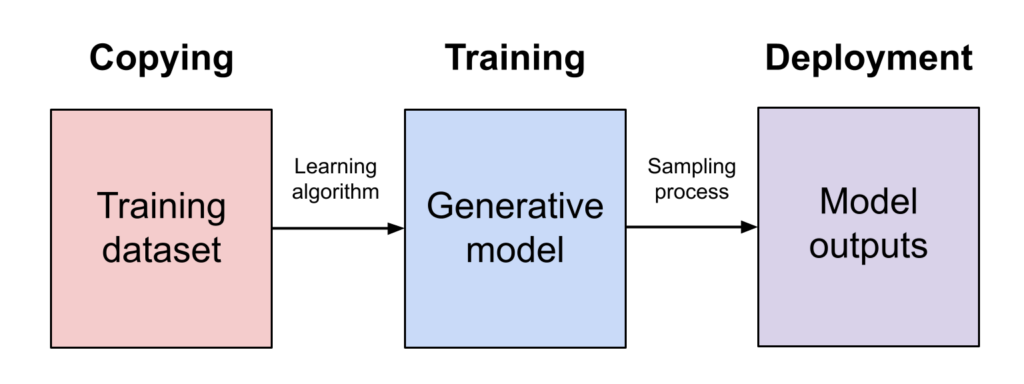
Le tecnologie di intelligenza artificiale generativa, stanno rivoluzionando l’acquisizione di informazioni e la produzione di contenuti in una varietà di domini. La studio “The consequences of generative AI for online knowledge communities”, pubblicato a maggio 2024, ha rilevato la forte influenza di ChatGPT sull’attività degli utenti di comunità di sviluppatori di come Stack Overflaw con il conseguente “calo sia nelle visite al sito che nei volumi di domande su Stack Overflow, in particolare sugli argomenti in cui ChatGPT eccelle”. Stack Overflaw però con Reddit, The Associated Press, News Corp, ha firmato degli accordi con gli sviluppatori di modelli come OpenAI e Google.
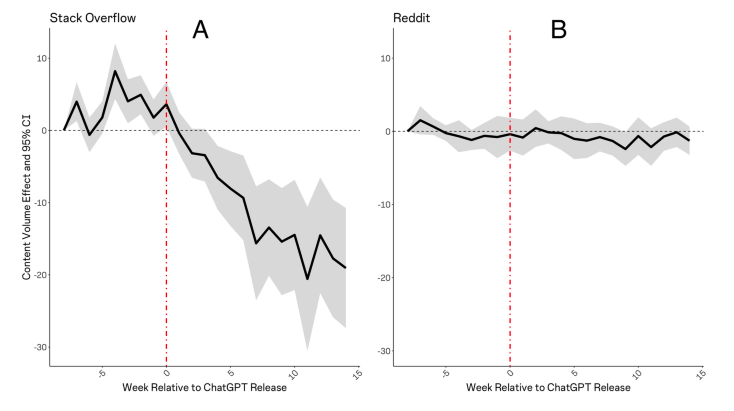
Anche considerando gli impatti positivi – miglioramento della produttività utente – il pericolo è che gli LLM possano sostituire del tutto le comunità di conoscenza online – con il peggioramento di ogni tipo di interazione interpersonale (anche nei luoghi di lavoro) – oltre al fatto che la loro produzione di contenuti errati (allucinazioni) sia da prendere in seria considerazione.
Il problema dello sfruttamento dei dati protetti da copyright senza licenza o compensi per gli autori, evidenziato da Suchir Balaji è significativo: uno strumento come ChatGBT potrebbe entrare in competizione con gli stessi contenuti originali degli autori, danneggiando loro, gli hub di informazione e le arti creative, con il rischio ulteriore di avvelenamento dei contenuti originali e la generazione di informazioni false o fuorvianti.
Migliaia di artisti – e da tempo – si sono infine schierati contro la pratica di addestrare l’intelligenza artificiale generativa con materiale protetto da copyright e senza licenza: “spendono somme ingenti per persone ed eleborazione” ha detto Newton-Rex, fondatore di Fairly Trained “si aspettano di prendere gratuitamente i dati di addestramento”, termine disumanizzante che sarebbe “il lavoro delle persone, la loro scrittura, la loro arte, la loro musica”.
